



Most likely you are aware of SEO and its best practices: the value of website structure, rules of tagging, keyword stuffing, the value of unique content optimization for and others, then you might have heard about Google bots. However, what do you know about Google bots? This phenomenon differs from a well-known SEO optimizing, because it is performed at the profound level. If SEO optimization deals with optimizing a text for SE queries, then Google Bot one is a process of website optimization for Google spiders. Of course, these processes do have similarities, but let us clarify their main difference because it may influence your site deeply. Here I will speak of such a phenomenon as site crawlability, as it is the main issue everybody should pay attention to if we speak of a website searchability.
What is Googlebot?
Site crawlers or Google bots are robots that examine a web page and create an index. If a web page permits a bot to access, then this bot adds this page to an index, and only then, this page becomes accessible to the users. If you wish to see how this process is performed, check here. If you wish to understand the process of Googlebot optimization, you need to clarify how exactly a Google spider scans a site. Here are these four steps:
If a webpage has high page ranking level, Google spider will spend more time on its crawling.
Here we can talk of “Crawl budget”, which is an exact amount of time spent by web robots on scanning a certain site: the higher authority a webpage has the more budget it will receive.
Google robots crawl a website constantly
Here what Google says about this: “Google robot hasn’t to access a website more than once every second.” This means that your website is under constant control of web spiders if they have access to it. Today many SEO managers argue about so-called “crawl rate” and try to find an optimal way of website crawling for getting high-ranking level. However, here we can speak of misinterpretation as “crawl rate” is nothing more than a speed of Google robot’s requests rather than crawling repetition. You can even modify this rate yourself using Webmaster Tools. The number of quality backlinks, uniqueness, and social mentions can influence your position in serp ranking. We should also note that web spiders do not scan every page constantly, thus, constant content strategies are very important as unique and useful content attracts the bot’s attention. Some pages cannot be scanned and become a part of Google cache. Formally, it is the screenshot of your web page from when Google last crawled it. So this cached version is ranking for Google and the new changes don’t count.
Robots.txt file is the first thing Google robots scan in order to get a roadmap for site crawling
This means that if a page is marked as disallowed in this file, robots will not be able to scan and index it.
XML sitemap is a guide for Google bots
XML sitemap helps bots to find out what website places have to be crawled and indexed, as there might be differences in the structure and website organization, thus this process may not be automatically. Good Sitemap can help the pages with low ranking level, few backlinks and useless content as well as helps Google to deal with images, news, video etc.
6 Strategies on How to Optimize Your Site Better for Googlebot’s Crawling
As you have understood, Google spider optimization must be done before any step for SE optimization is taken. Crawlability errors are the most common errors nowadays. Thus, let us now consider what you should do to facilitate the process of indexing for Google bots.
Overdoing is not good
Do you know that Googlebots cannot scan various frames, Flash, JavaScript, DHTML as well as well-known HTML. Moreover, Google has not clarified yet whether Googlebot is able to crawl Ajax and JavaScript, thus you would better not use them when creating your website. Although Matt Cutts states that JavaScript can be opened for web spiders, such evidence as Google Webmaster Guidelines refutes this: “If such things as cookies, various frames, Flash or JavaScript can’t be seen in a text browser, then web spiders might not be able to crawl this website.” To my mind, JavaScript must not be overused. Sometimes it is needed to view cookies your website have.
Do not underestimate robots.txt file
Have you ever thought of the purpose of the robots.txt file? It is the common file used in many SEO strategies, but is it really useful? Firstly, this file is a directive for all web spiders, thus Google robot will spend “crawl budget” on any web page of your site. Secondly, you should decide yourself what file the bots have to scan, thus if there is a file that is not allowed to crawl, you can indicate it in your robots.txt file. Why do this? If there are pages that should not be crawled, Google bot will immediately see this and scan the part of your site, which is more important. However, my suggestion does not block what should not be blocked. Moreover, you can try robots.txt checker to test what of your web pages are closed for indexation. If you do not indicate that something is disallowed to crawl, the bot will crawl and index everything by default. Thus, the main function of the robots.txt file is indicating where it should not go.
Useful and unique content really matters
The rule is that content that is crawled more frequent, as a result gets higher traffic. Despite the fact that PageRank determines crawl frequency, it can step aside when speaking of the usefulness and freshness of the pages that have similar PageRank. Thus, your main aim is to get your low-ranked pages to be regularly scanned. AJ Kohn once said: “You are a winner if you have transformed your low-ranked pages into those, which are scanned more often, than the competitions.”
Getting magical scroll pages
If your site contains those endlessly, scrolling pages, that does not mean you have no chances for Googlebot optimization. Thus, you should make sure that these web pages comply with Google’s guidelines.
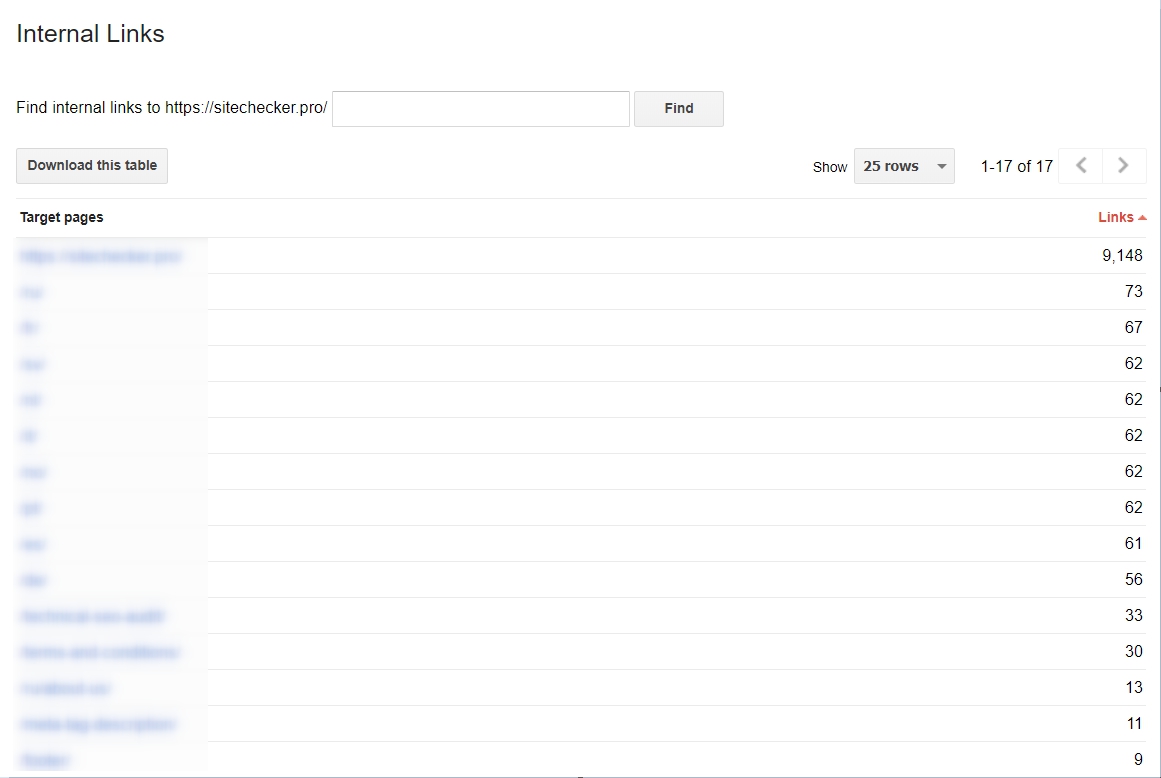
You have to start using internal links
This is very important to use if you wish to make a process of scanning much easier for Googlebots. If your links are tight-knit and consolidated, the process of scanning will be much effective. If you wish to get an analysis of your internal hyperlinks, you can do this by going to the Google Webmaster Tools, then Search Traffic and choose the Internal Links section. If the web pages are on top of the list, then they contain useful content.
Sitemap.xml is vital
The sitemap gives directions for Googlebot on how to access a website; it is simply a map to follow. Why is it used then? Many websites today are not easy to scan, and these difficulties can make a process of crawling very complicated. Thus, the sections of your site that can confuse web spider is indicated in a sitemap, and this can guarantee all the website areas will be crawled.
How to Analyze Googlebot’s Activity?
If you wish to see the Googlebot’s activity performed on your site, you can use Google Webmaster Tools. Moreover, we advise you to check the data provided by this service on a regular basis, as it will show you if some problems occur while crawling. Just check the “Crawl” section in your Webmaster Tools.
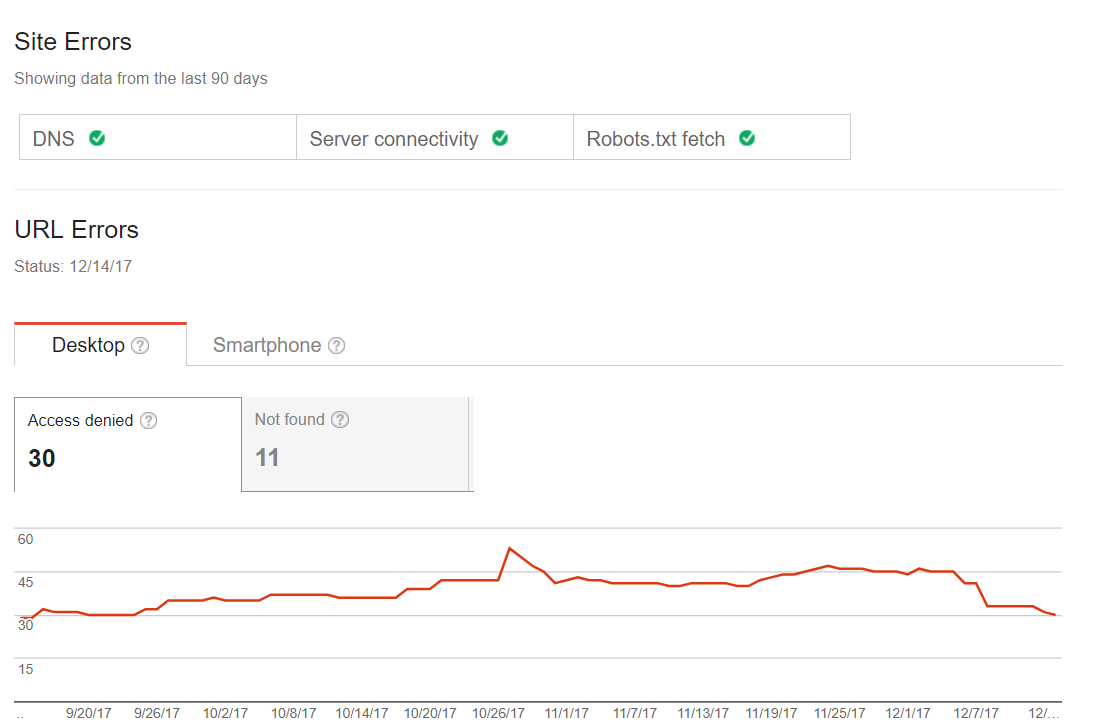
Common crawling errors
You can check whether your site is facing any problems with the scanning process. Thus, you will either have no issues status or have red flags, e.g pages, which are expected to be due to the last index. Thus, the first step you should take, when talking about the Googlebot optimization. Some websites may have minor scan errors, but that does not mean they will influence traffic or ranking. Nevertheless, with the passage of time, such problems may result in traffic decline. Here you can find an example of such site:
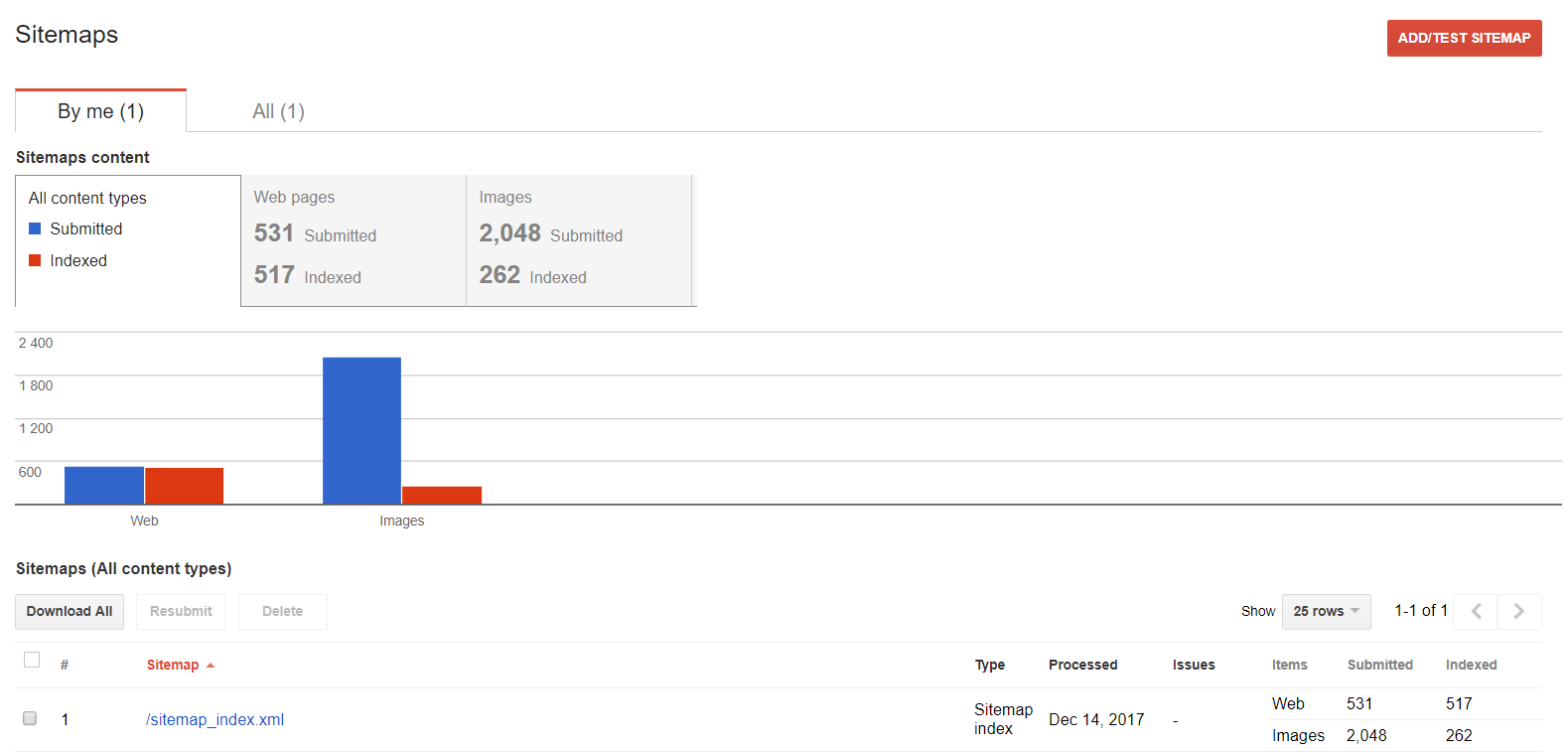
Sitemaps
You can use this function if you wish to work with your sitemap: examine, add or find out what content is being indexed.
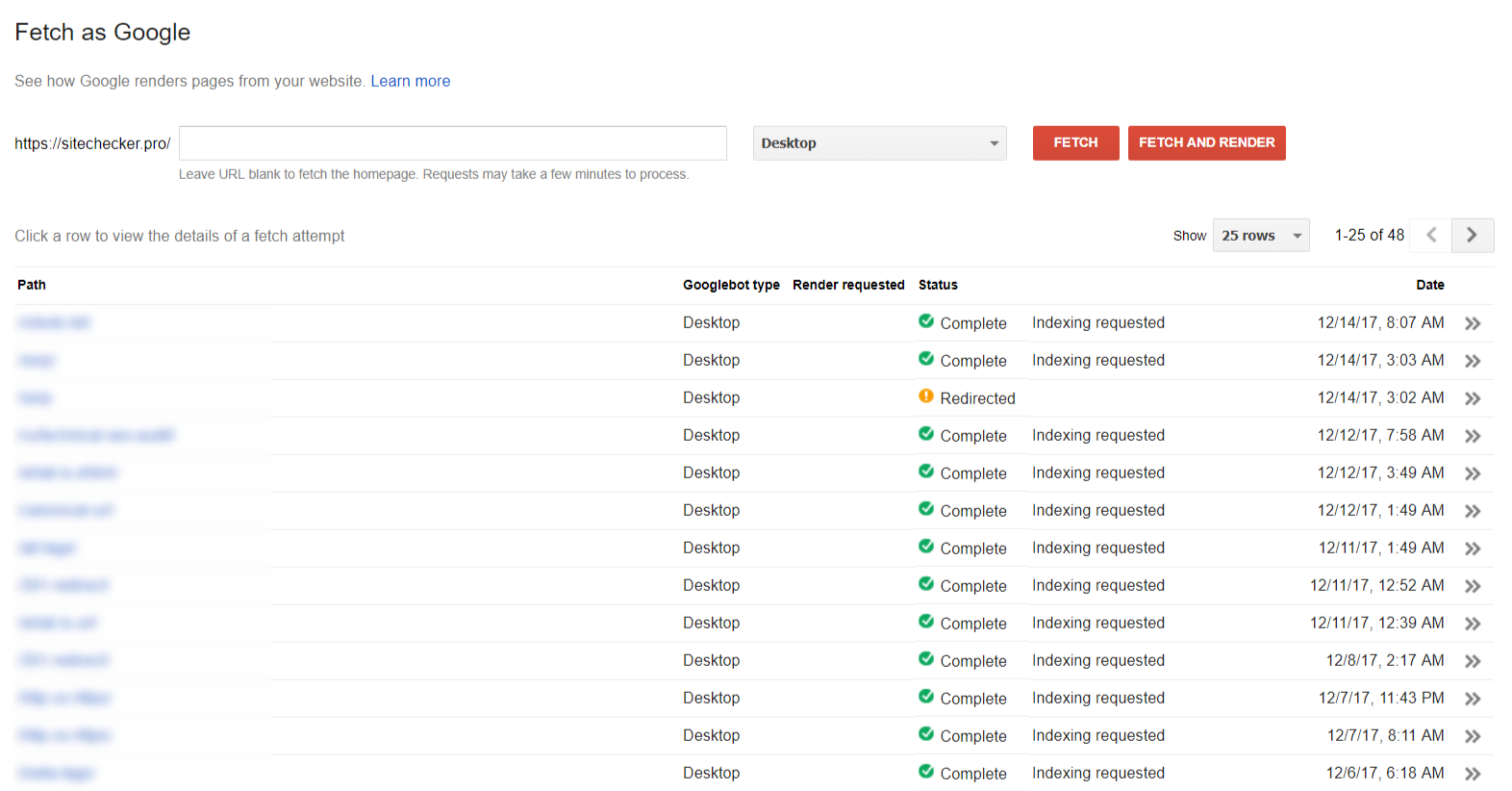
Fetching
The section “Fetch as Google” help you to see your site/page the way Google sees it.
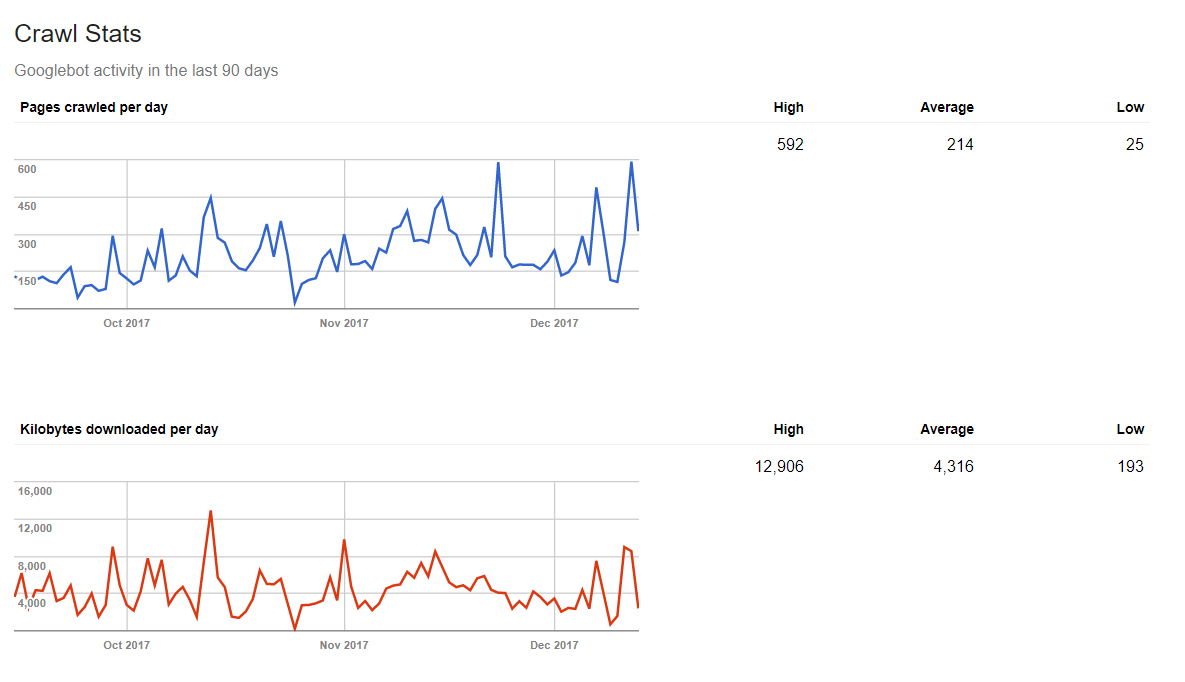
Crawling statistics
Google can also tell you how much data a web spider processes a day. Thus, if you post fresh content on a regular basis, you will have a positive result in statistics.
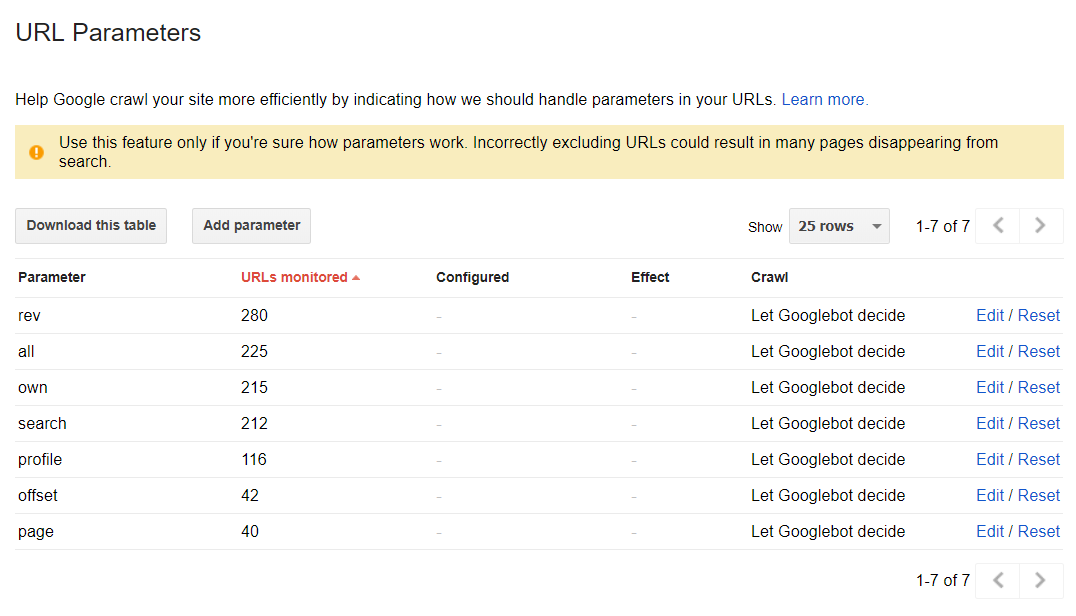
The parameters of URL
This section can help you to discover a way Google crawls and indexes your website, using URL parameters. You can find more about “What is a URL” reading our guide. However, in default mode, all pages are crawled due to the web spider decisions:
Discover How Many of Your Website’s Pages are Indexed with Google Index Checker
The Google Index Checker is vital for SEO professionals and website owners to confirm if web pages are indexed by Google, a crucial factor in search engine visibility. This tool easily checks the indexing status of pages or entire websites, aiding in enhancing a website’s SEO performance.
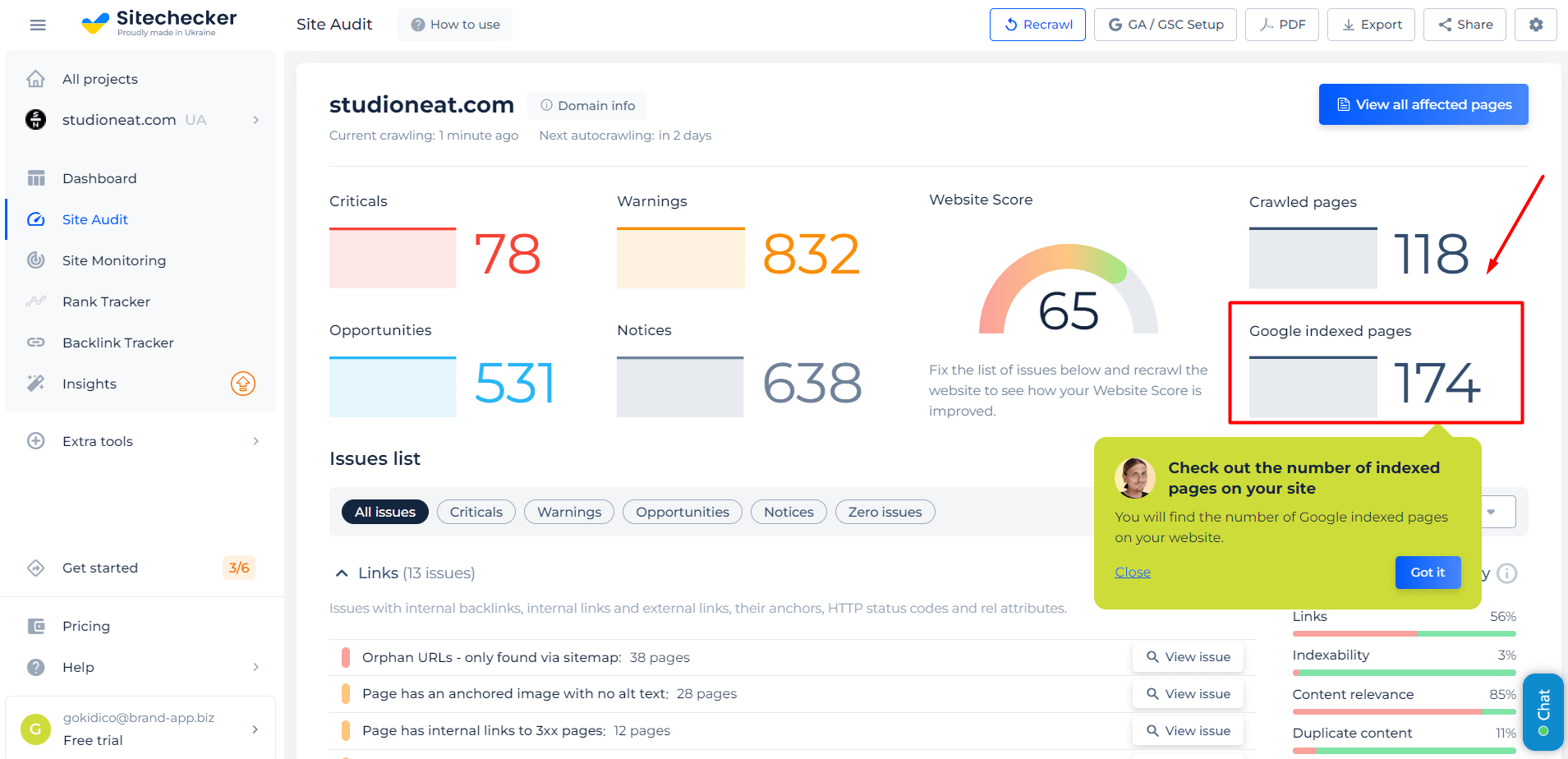
Tool identifies issues preventing page indexing, such as crawl errors or meta tags. It offers solutions for these problems, aiding in optimizing web pages to meet Google’s indexing criteria. This tool’s quick and accurate results are essential for enhancing your website’s online visibility.
Check Your Google Index Status Now!
Our Index Checker quickly reveals your indexed pages for better SEO planning.
To further ensure your site is accessible to search engine crawlers, using a Googlebot Simulator can help you see how Googlebot navigates your site and identify any obstacles that may prevent proper crawling and indexing. The combination of both tools provides quick and accurate results, essential for enhancing your website’s online visibility.
Conclusion
Googlebot, a vital component for SEO, is essential for optimizing a website for Google’s crawlers. It indexes pages that allow access, prioritizing them based on their authority and allocating a ‘Crawl budget’ accordingly. Continuous crawling by these bots underscores the need for a dynamic website. Key elements like the robots.txt file and XML sitemap guide Googlebots through the site, ensuring comprehensive indexing. Effective Googlebot optimization involves maintaining high-quality content, strategic internal linking, and proper sitemap usage. Regular monitoring through Google Webmaster Tools is crucial for identifying and addressing crawling issues, ensuring optimal website health and searchability.





