


What is Robots.txt Tester?
The Robots.txt Tester tool by Sitechecker is designed for validating a website’s robots.txt file, ensuring that search engine bots understand which pages should be indexed or ignored. This facilitates efficient management of a site’s visibility in search results. The tool offers comprehensive site checks to identify indexing issues and also provides page-specific scans to determine if a page is indexed. This enhances the accuracy of search engine indexing by quickly identifying and correcting any errors in the robots.txt file settings.
How the tool can assist you?
Robots.txt File Validation: verifies the correctness of a website’s robots.txt file, ensuring it accurately directs search engine bots.
Page-Specific Scans: offers the ability to check if individual pages are correctly indexed or not, allowing for targeted troubleshooting.
Indexing Issue Identification: provides comprehensive checks to spot any indexing problems across the entire site.
Key features of the tool
Unified Dashboard: offers a comprehensive overview of SEO metrics for easy monitoring.
User-friendly Interface: designed for intuitive navigation and ease of use.
Complete SEO Toolset: provides a wide range of tools for optimizing website performance in search engines.
How to Use the Tool
The tool offers two types of online scanning: whole site and individual page. Simply select the option you’re interested in and initiate the scan.
The Site Robots.txt File Testing
To check your site’s robot settings and uncover any indexing issues, simply select the site inspection option. Within minutes, you’ll receive a comprehensive report.
Step 1: Choose the site checking
Step 2: Get the results
The Robots.txt Analyzer to assess server directive file configuration, give you valuable data on how their website’s directives influence search engine indexing. The report includes identification of pages blocked from crawling, specific directives like ‘noindex’ and ‘nofollow’, and any crawl delays set for search engine bots. This helps in ensuring that the website crawl policy file is facilitating optimal website visibility and search engine accessibility.
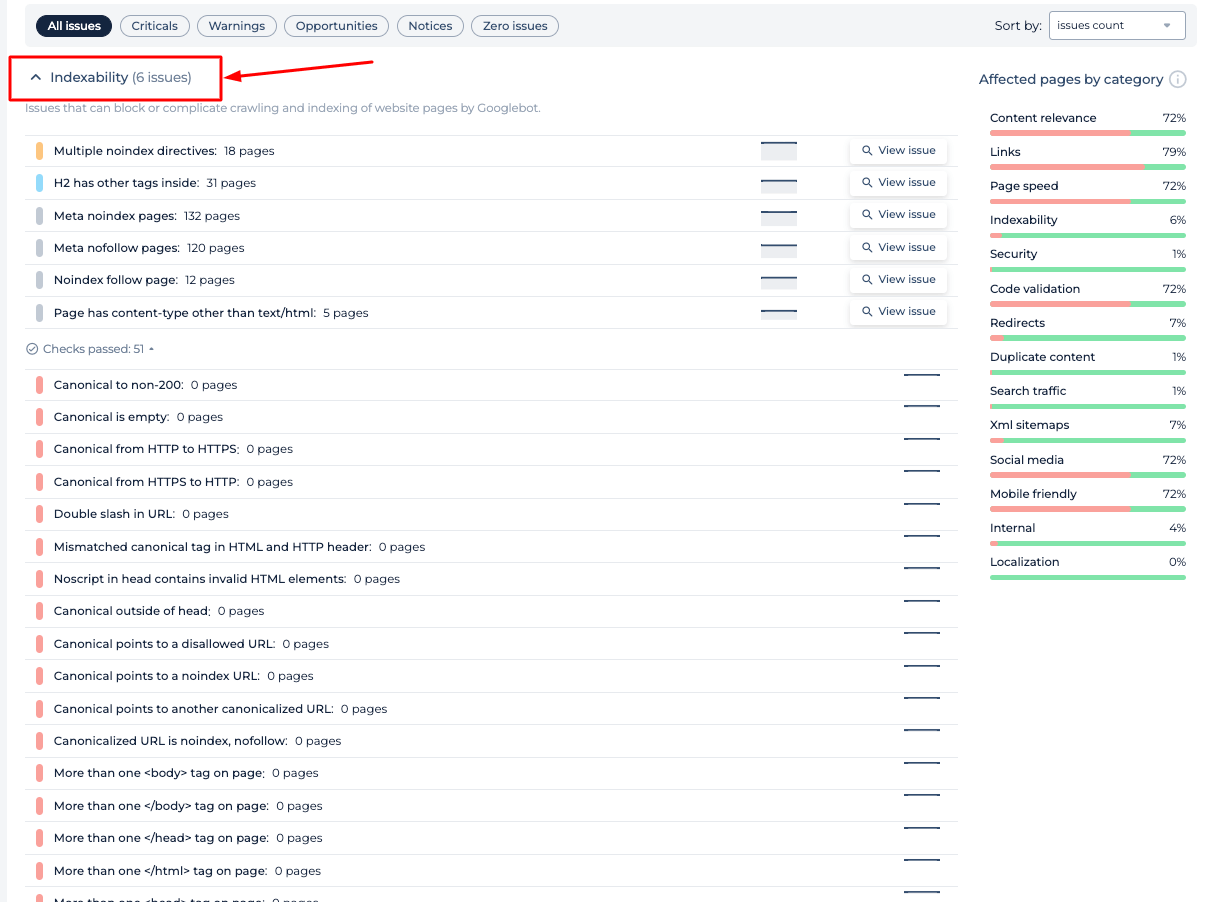
Additional feauters
The Robots.txt Checker offers a comprehensive analysis of a website’s SEO health. It identifies critical issues, warnings, opportunities for improvement, and general notices. Detailed insights are provided on content relevance, link integrity, page speed, and indexability. The audit categorizes affected pages, allowing users to prioritize optimizations for better search engine visibility. This feature complements the Robots.txt Checker by ensuring broader SEO elements are also addressed.
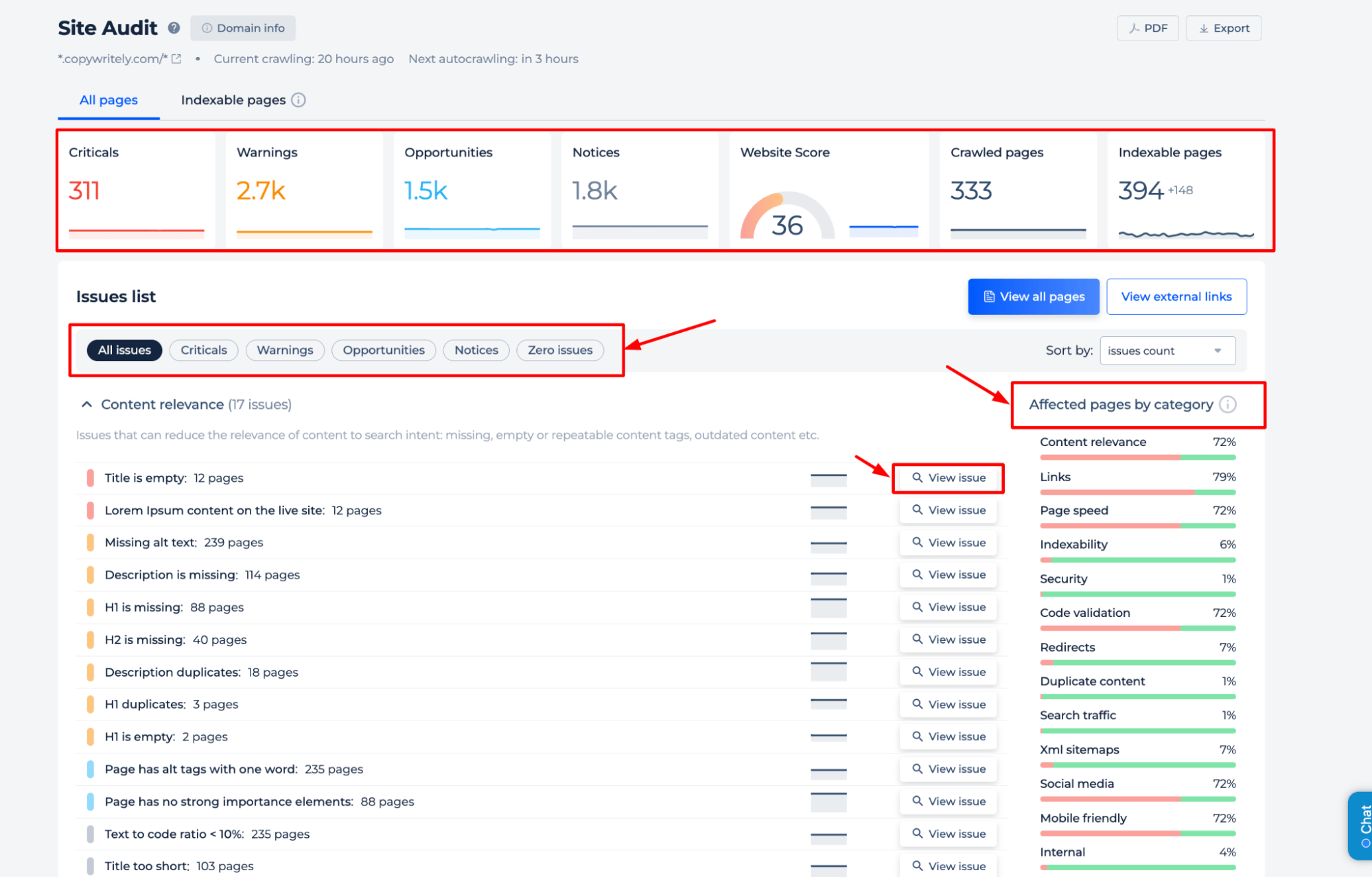
Test Robots.txt for a Specific Page
Step 1: Initiate a check for a specific page
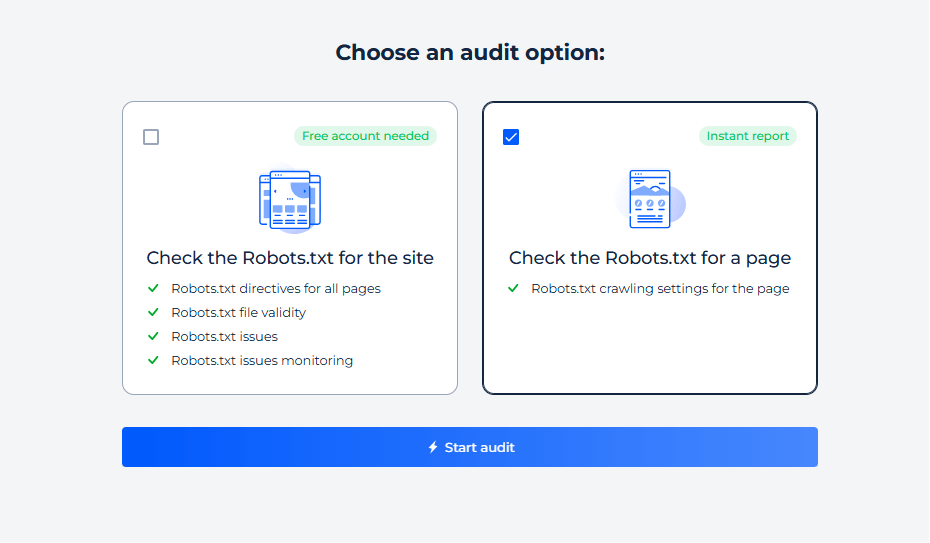
Step 2: Get the results
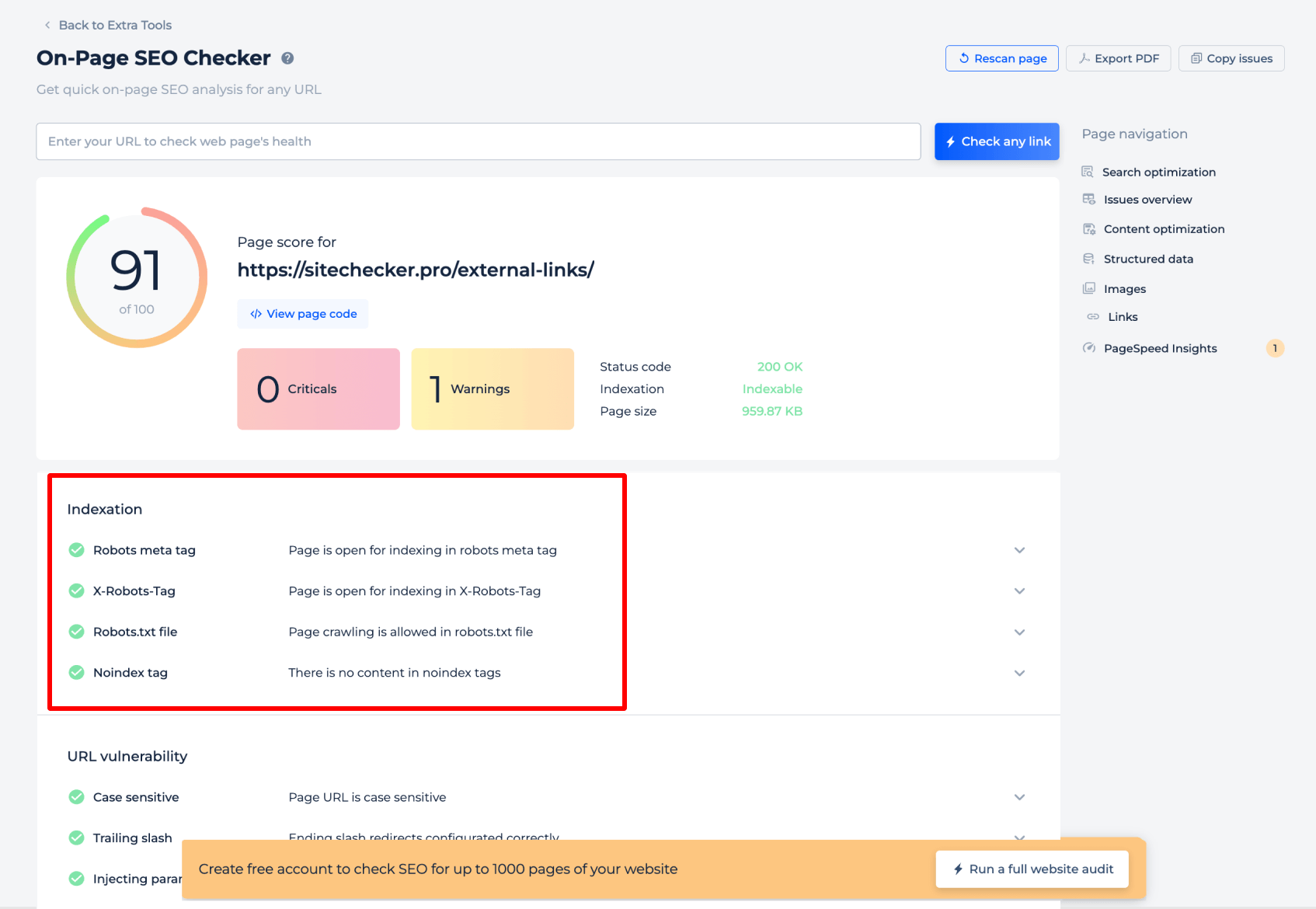
The Robots.txt Tester for a specific page provides critical insights into how search engines interpret robots.txt directives for that page. It analyzes the robots meta tag and X-Robots-Tag to confirm whether the page is open for indexing. Additionally, it verifies if crawling is permitted by the website crawl policy file and checks for the presence of ‘noindex’ tags that could prevent indexing. This focused assessment ensures each page is correctly configured to be accessible to search engine bots.
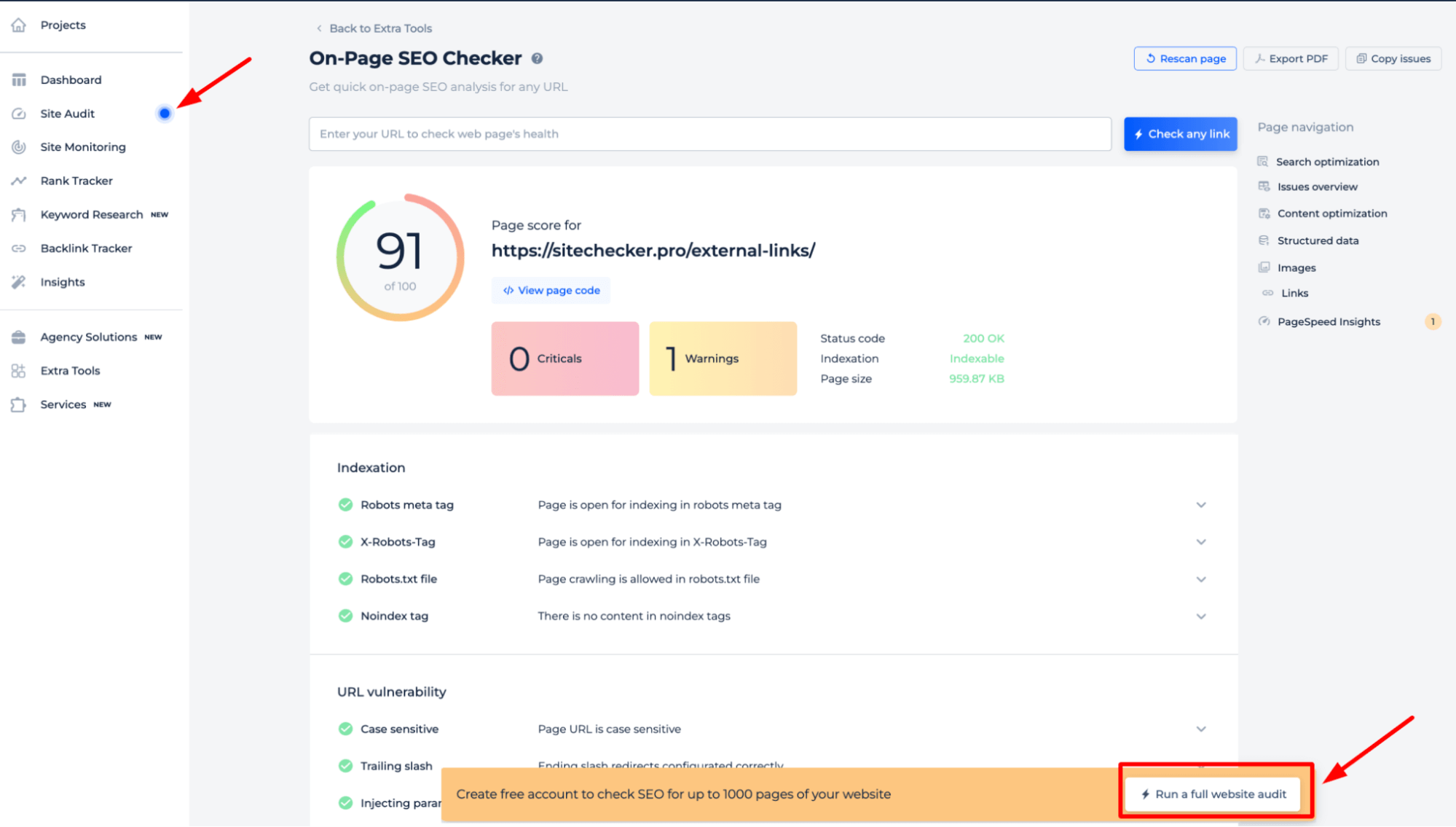
To gain a comprehensive understanding of your site’s robots.txt directives, it’s best to perform a full website audit. This will uncover any indexing issues throughout your site. To begin the audit, simply click the “Start full website audit” banner. A demo version of the tool is accessible via the Site Audit section, allowing you to sample its capabilities.
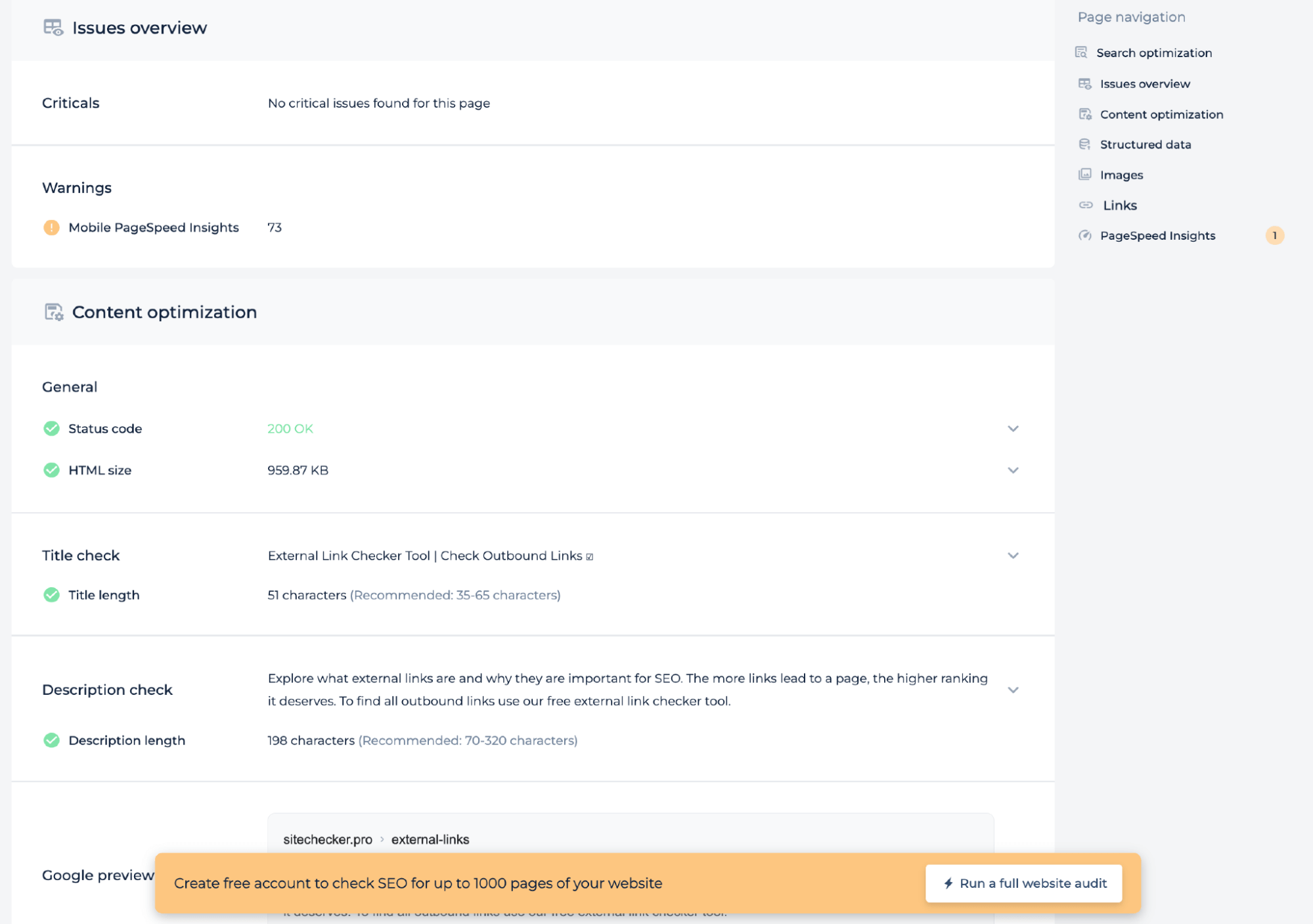
Additional feauters
In addition to testing server directive file for a specific page, the technical audit provides insights into page health such as mobile PageSpeed score, status code, and HTML size. It checks whether the title and description lengths meet recommended standards and offers a Google preview to ensure the page is optimized for search engines. This analysis aids in enhancing the technical SEO of the page.
Check indexation & robots info in few clicks
The Sitechecker Chrome Extension gives you an instant look at a page’s indexation status and robots directives without switching tools.
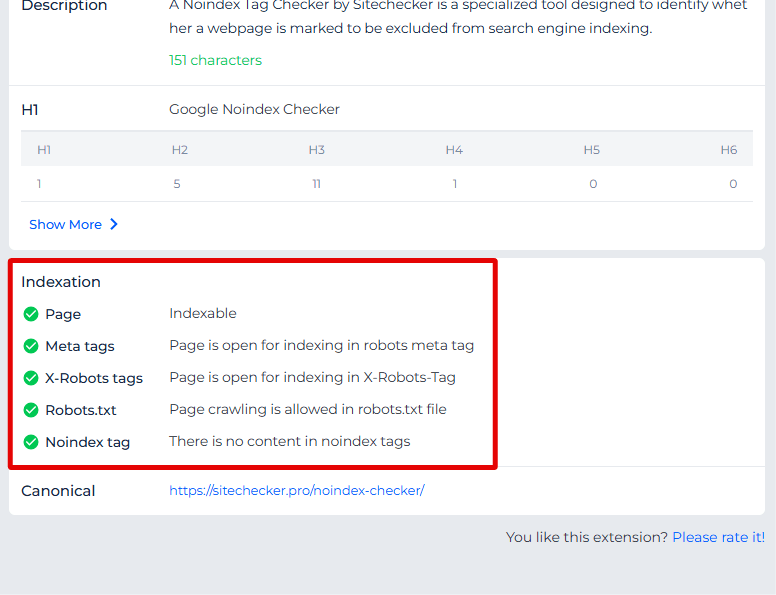
Right in the browser, it shows whether the page is allowed to be indexed, what robots rules are applied (like noindex/nofollow), and key HTTP header info that affects crawling.
This lets you quickly verify indexability and robots settings while you’re reviewing pages, saving time before running a full robots test.
Final Idea
The Robots.txt Tester is a robust SEO diagnostic tool that ensures a website’s server directive file is directing search engine bots correctly. It offers both full-site and page-specific scans, revealing any indexing barriers. Users benefit from a user-friendly interface, an extensive suite of SEO tools, and a unified dashboard for monitoring. The tool’s comprehensive audit capabilities allow for the identification of a wide range of technical SEO issues, including content optimization and page health metrics, ensuring each page is primed for search engine discovery and ranking.







