


Qu’est-ce que Robots.txt Tester ?
L’outil Robots.txt Tester de Sitechecker est conçu pour valider le fichier robots.txt d’un site Web, garantissant que les robots des moteurs de recherche comprennent quelles pages doivent être indexées ou ignorées. Cela facilite la gestion efficace de la visibilité d’un site dans les résultats de recherche. L’outil propose des vérifications complètes du site pour identifier les problèmes d’indexation et fournit également des analyses spécifiques à la page pour déterminer si une page est indexée. Cela améliore la précision de l’indexation des moteurs de recherche en identifiant et en corrigeant rapidement les erreurs dans les paramètres du fichier robots.txt.
Comment l’outil peut-il vous aider ?
Validation du fichier robots.txt : vérifie l’exactitude du fichier robots.txt d’un site Web, garantissant qu’il dirige avec précision les robots des moteurs de recherche.
Analyses spécifiques à la page : offrent la possibilité de vérifier si les pages individuelles sont correctement indexées ou non, permettant un dépannage ciblé.
Identification des problèmes d’indexation : fournit des vérifications complètes pour repérer tout problème d’indexation sur l’ensemble du site.
Principales fonctionnalités de l’outil
Tableau de bord unifié :offre un aperçu complet des indicateurs SEO pour un suivi facile.
Interface conviviale :conçue pour une navigation intuitive et une utilisation facile.
Ensemble complet d’outils SEO :fournit une large gamme d’outils pour optimiser les performances du site Web dans les moteurs de recherche.
Comment utiliser l’outil
L’outil propose deux types d’analyse en ligne : site entier et page individuelle. Sélectionnez simplement l’option qui vous intéresse et lancez l’analyse.
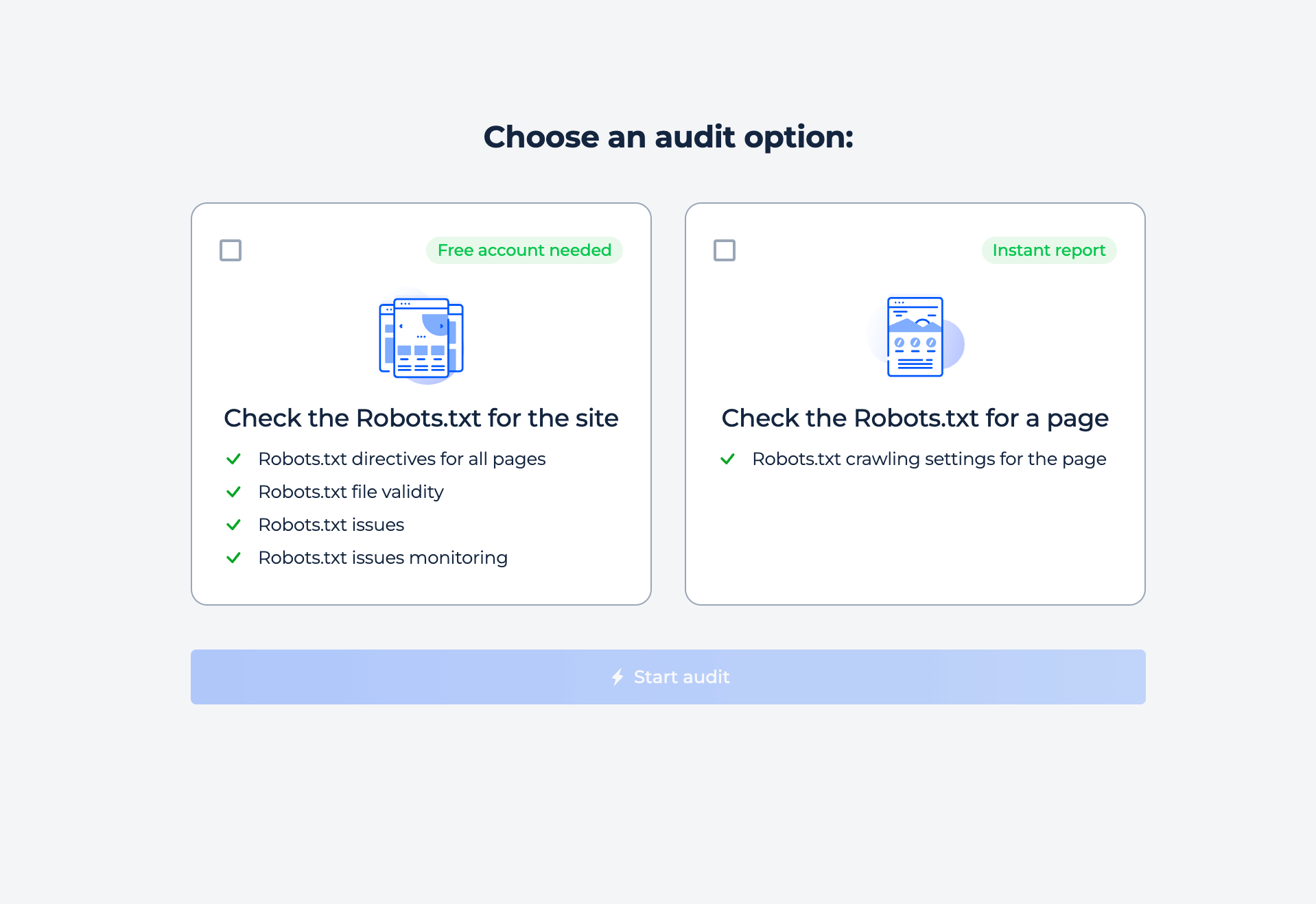
Test du fichier Robots.txt du site
Pour vérifier les paramètres robots de votre site et découvrir d’éventuels problèmes d’indexation, sélectionnez simplement l’option d’inspection du site. En quelques minutes, vous recevrez un rapport complet.
Étape 1 : Choisissez la vérification du site
Étape 2 : Obtenez les résultats
L’analyseur Robots.txt pour évaluer la configuration du fichier de directives du serveur vous fournit des données précieuses sur la manière dont les directives de votre site Web influencent l’indexation des moteurs de recherche. Le rapport comprend l’identification des pages bloquées à l’exploration, des directives spécifiques telles que « noindex » et « nofollow », ainsi que tous les délais d’exploration définis pour les robots des moteurs de recherche. Cela permet de garantir que le fichier de politique d’exploration du site Web facilite une visibilité optimale du site Web et l’accessibilité des moteurs de recherche.
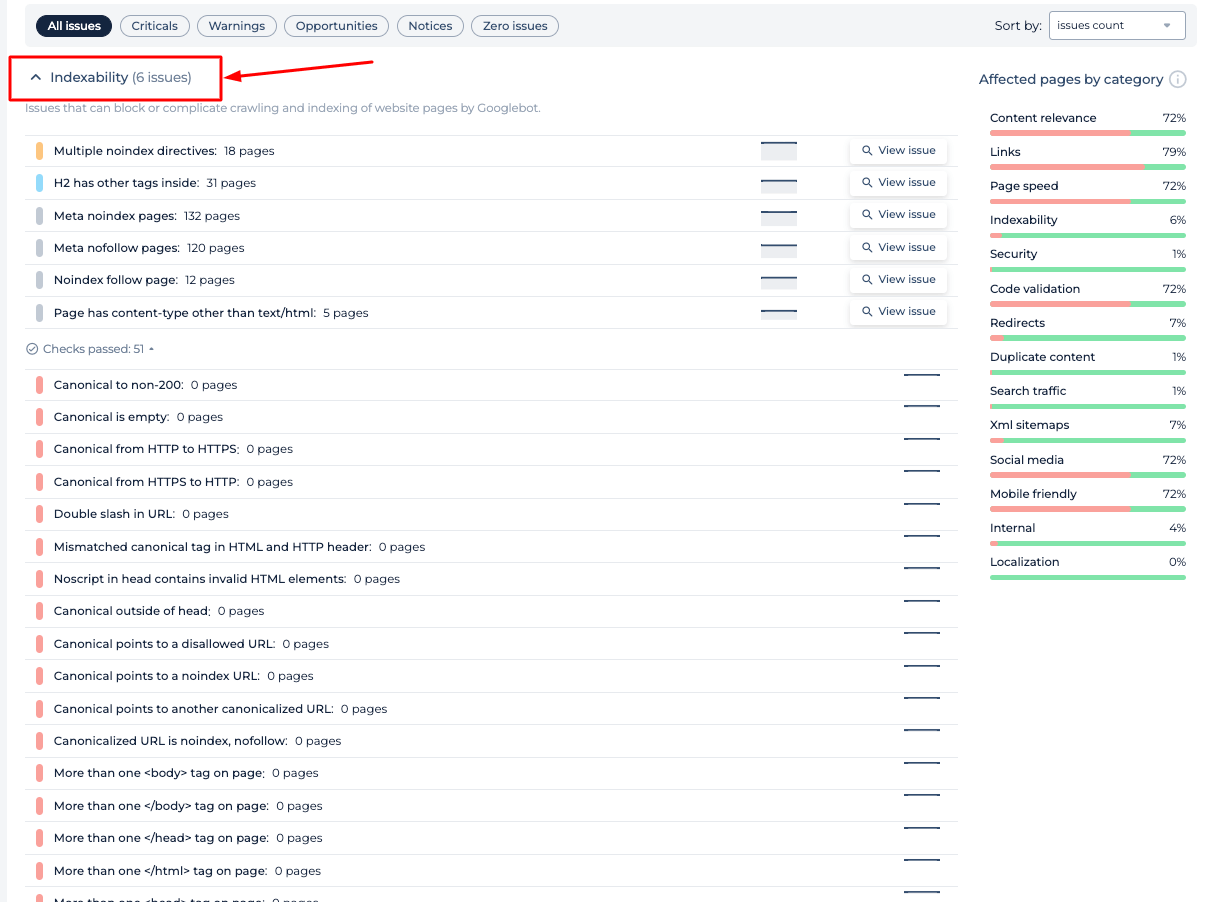
Feauters supplémentaires
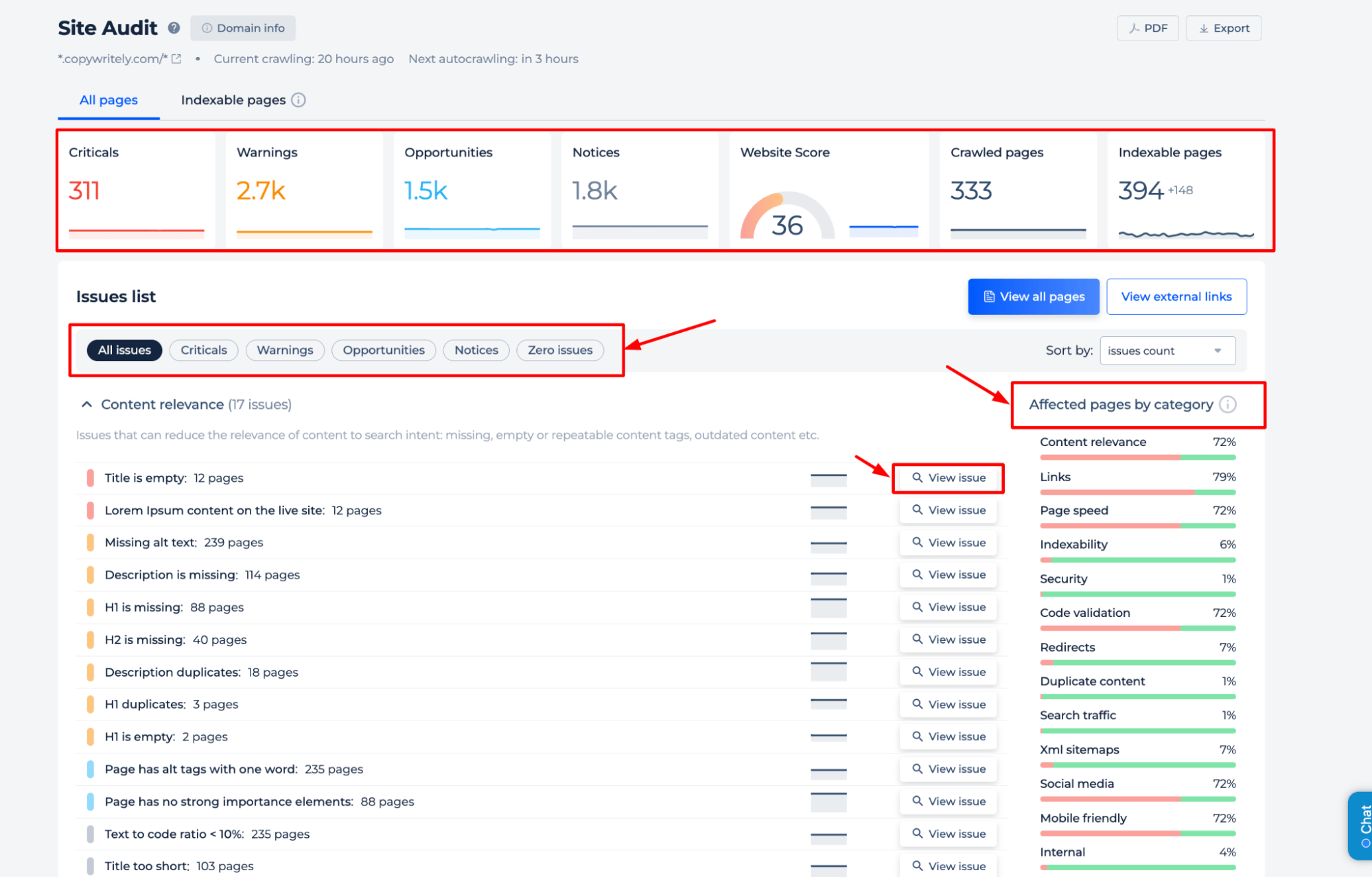
Le vérificateur Robots.txt offre une analyse complète de la santé SEO d’un site Web. Il identifie les problèmes critiques, les avertissements, les opportunités d’amélioration et les avis généraux. Des informations détaillées sont fournies sur la pertinence du contenu, l’intégrité des liens, la vitesse des pages et l’indexabilité. L’audit catégorise les pages concernées, permettant aux utilisateurs de hiérarchiser les optimisations pour une meilleure visibilité sur les moteurs de recherche. Cette fonctionnalité complète le vérificateur Robots.txt en garantissant que des éléments SEO plus larges sont également traités.
Tester Robots.txt pour une page spécifique
Étape 1 : lancer une vérification pour une page spécifique
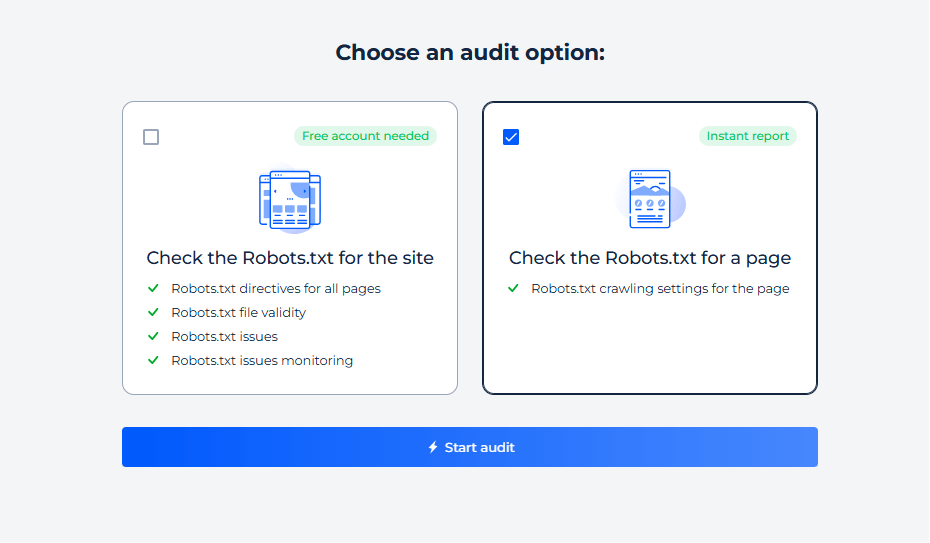
Étape 2 : obtenir les résultats
Le testeur Robots.txt pour une page spécifique fournit des informations essentielles sur la manière dont les moteurs de recherche interprètent les directives robots.txt pour cette page. Il analyse la balise méta robots et la balise X-Robots pour confirmer si la page est ouverte à l’indexation. De plus, il vérifie si l’exploration est autorisée par le fichier de politique d’exploration du site Web et vérifie la présence de balises « noindex » qui pourraient empêcher l’indexation. Cette évaluation ciblée garantit que chaque page est correctement configurée pour être accessible aux robots des moteurs de recherche.
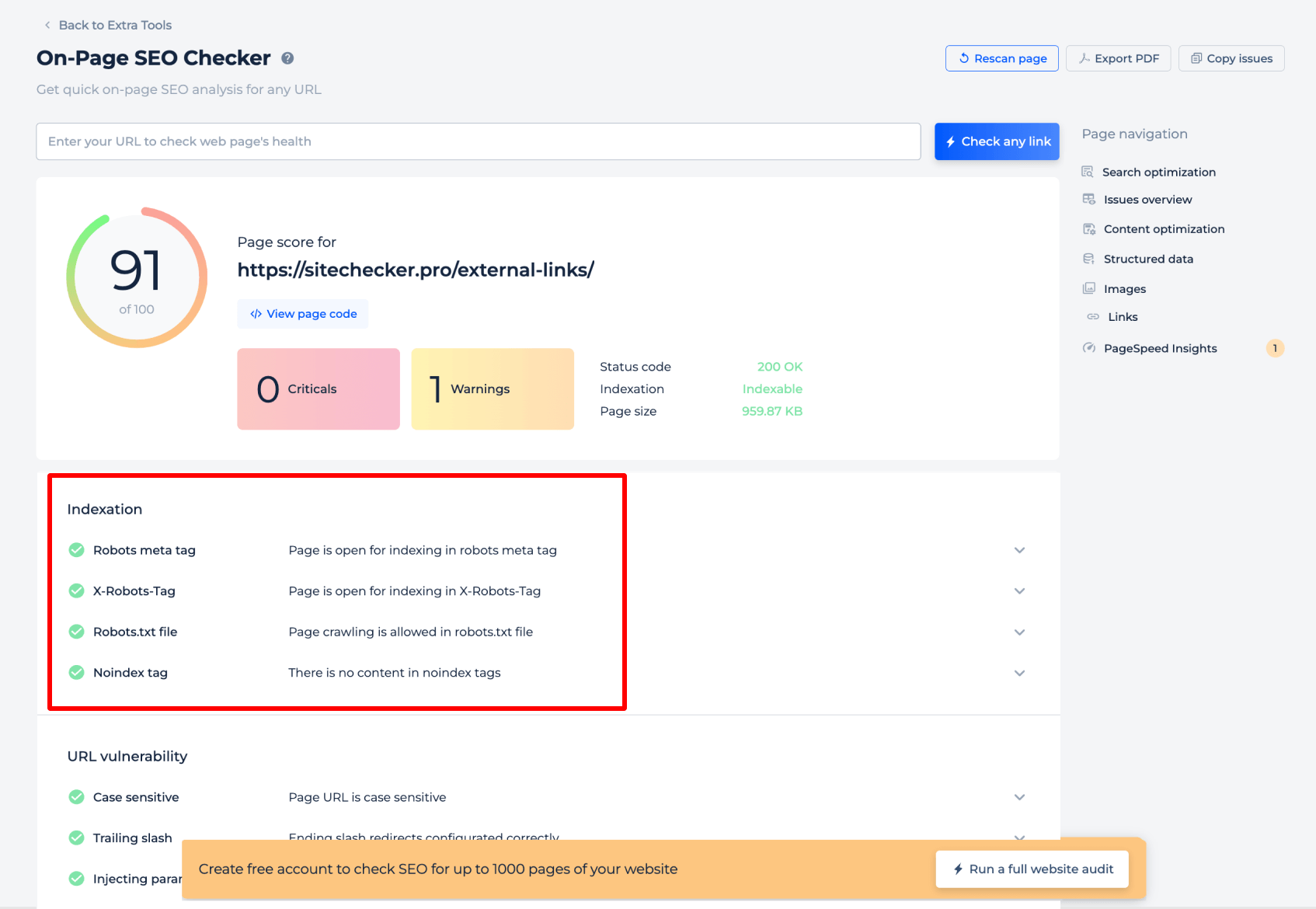
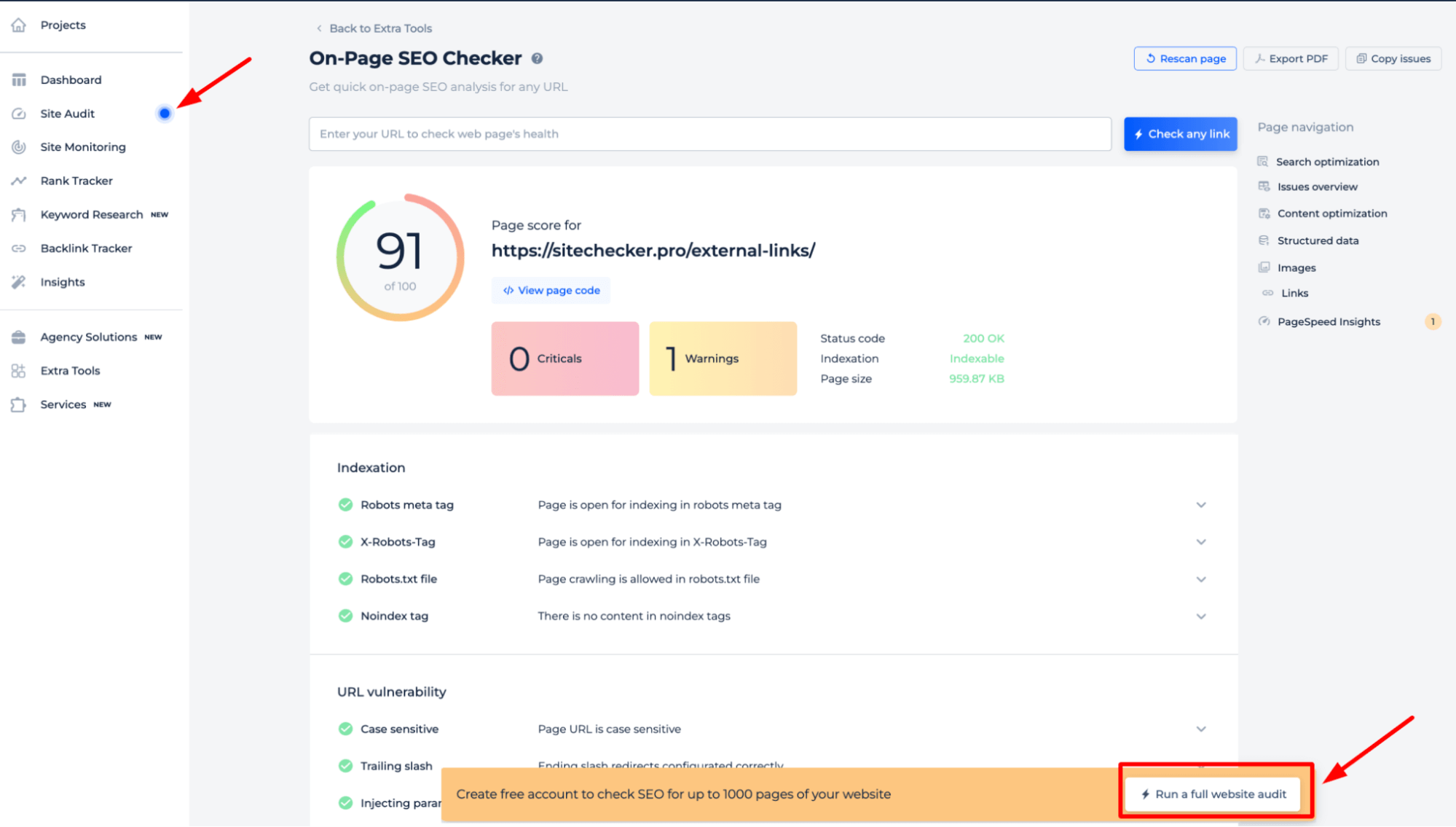
Pour avoir une compréhension complète des directives robots.txt de votre site, il est préférable d’effectuer un audit complet du site Web. Cela permettra de découvrir tous les problèmes d’indexation sur l’ensemble de votre site. Pour commencer l’audit, cliquez simplement sur la bannière « Démarrer l’audit complet du site Web ». Une version de démonstration de l’outil est accessible via la section Audit du site, vous permettant d’échantillonner ses capacités.
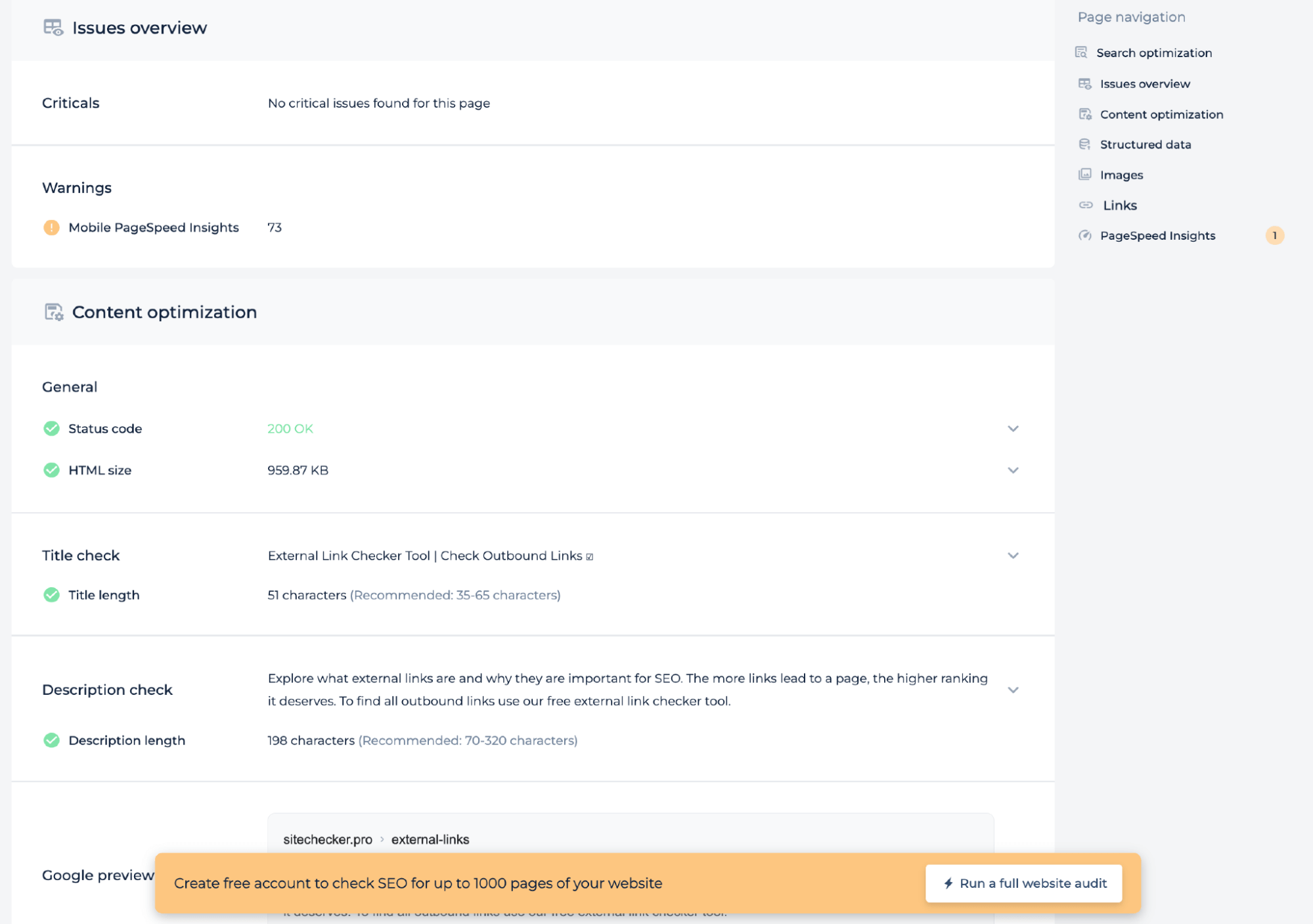
Fonctionnalités supplémentaires
En plus de tester le fichier de directives du serveur pour une page spécifique, l’audit technique fournit des informations sur l’état de la page, telles que le score PageSpeed mobile, le code d’état et la taille HTML. Il vérifie si les longueurs du titre et de la description répondent aux normes recommandées et offre un aperçu Google pour garantir que la page est optimisée pour les moteurs de recherche. Cette analyse contribue à améliorer le référencement technique de la page.
Idée finale
Le testeur Robots.txt est un outil de diagnostic SEO robuste qui garantit que le fichier de directives du serveur d’un site Web dirige correctement les robots des moteurs de recherche. Il propose des analyses complètes du site et des pages spécifiques, révélant les obstacles à l’indexation. Les utilisateurs bénéficient d’une interface conviviale, d’une suite complète d’outils SEO et d’un tableau de bord unifié pour la surveillance. Les capacités d’audit complètes de l’outil permettent d’identifier un large éventail de problèmes techniques de référencement, notamment l’optimisation du contenu et les mesures de santé des pages, garantissant que chaque page est préparée pour la découverte et le classement des moteurs de recherche.







