


What is the Google Index Checker?
The Indexing Checker by Sitechecker is an online tool that allows users to audit the index status of a website or individual pages. It provides insights into indexed pages, meta noindex tags, and crawlability issues. You can analyze all pages, or test an instant report for a single page.
How the tool can assist you
Instant Index Check: quickly verifies whether Google indexes a website or page.
Identify indexing issues: detects pages that are not indexed due to technical errors, meta noindex tags, or other SEO problems.
Monitor site changes: provides continuous tracking and alerts about crawling status changes, helping users maintain a strong online presence.
Key features of the tool
Unified Dashboard: provides a centralized hub for monitoring website health, SEO performance, and crawling status in one place.
User-friendly Interface: designed for beginners and experts, offering intuitive navigation, clear insights, and actionable recommendations.
Complete SEO Toolset: includes site audits, rank tracking, on-page SEO checks, and crawling status changes monitoring to enhance search visibility.
How to Use the Tool
You can perform a full site audit or run an instant page check. Simply select the option that best suits your needs and run the audit.

Full Site Index Check
Step 1: Choose a site check option
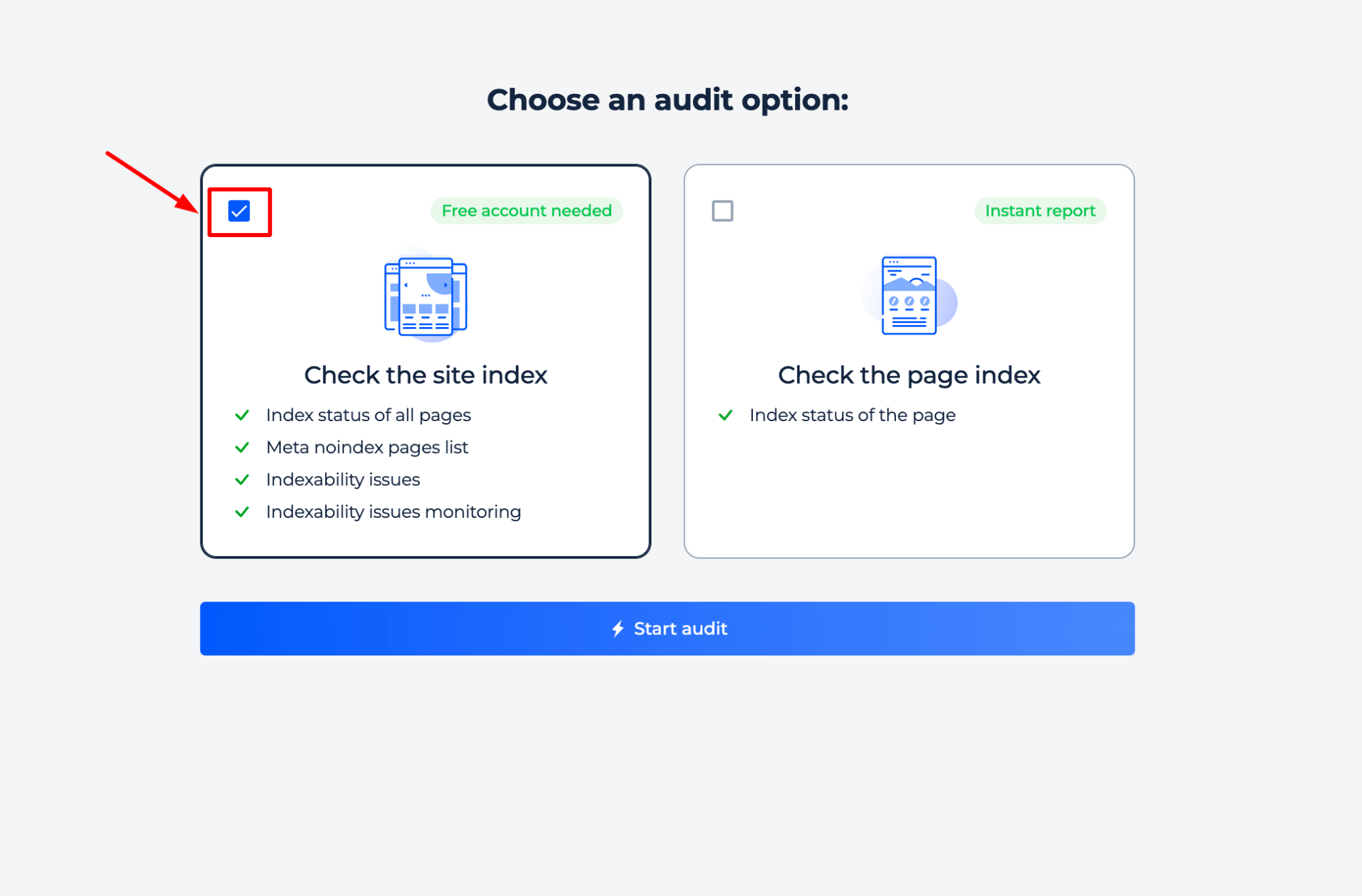
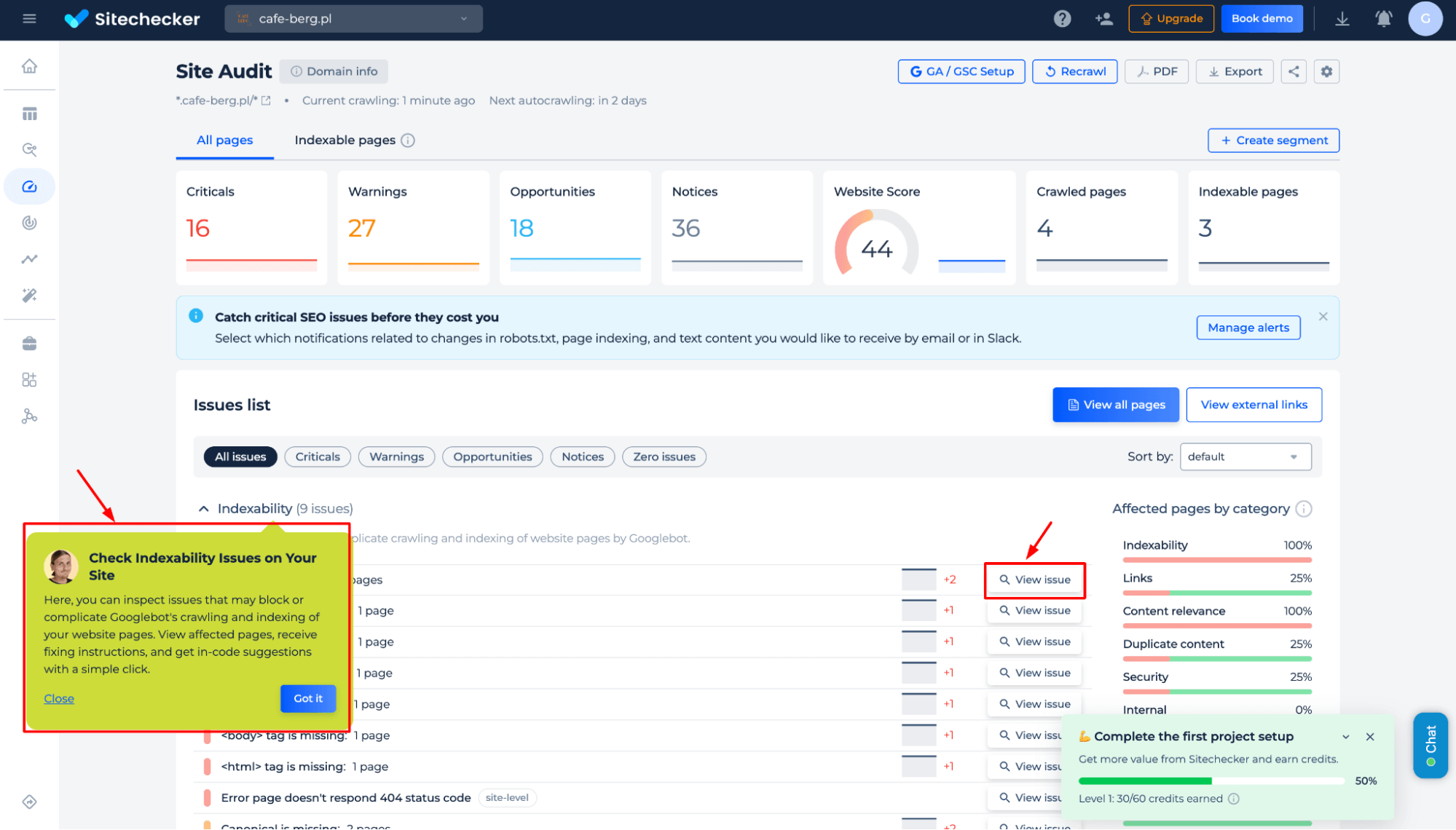
Step 2: Get results
Get a detailed analysis of your site’s crawlability, including critical SEO issues, warnings, opportunities, and crawling status changes. Identify blocked pages, missing tags, and technical errors that affect search visibility, with actionable fixes.
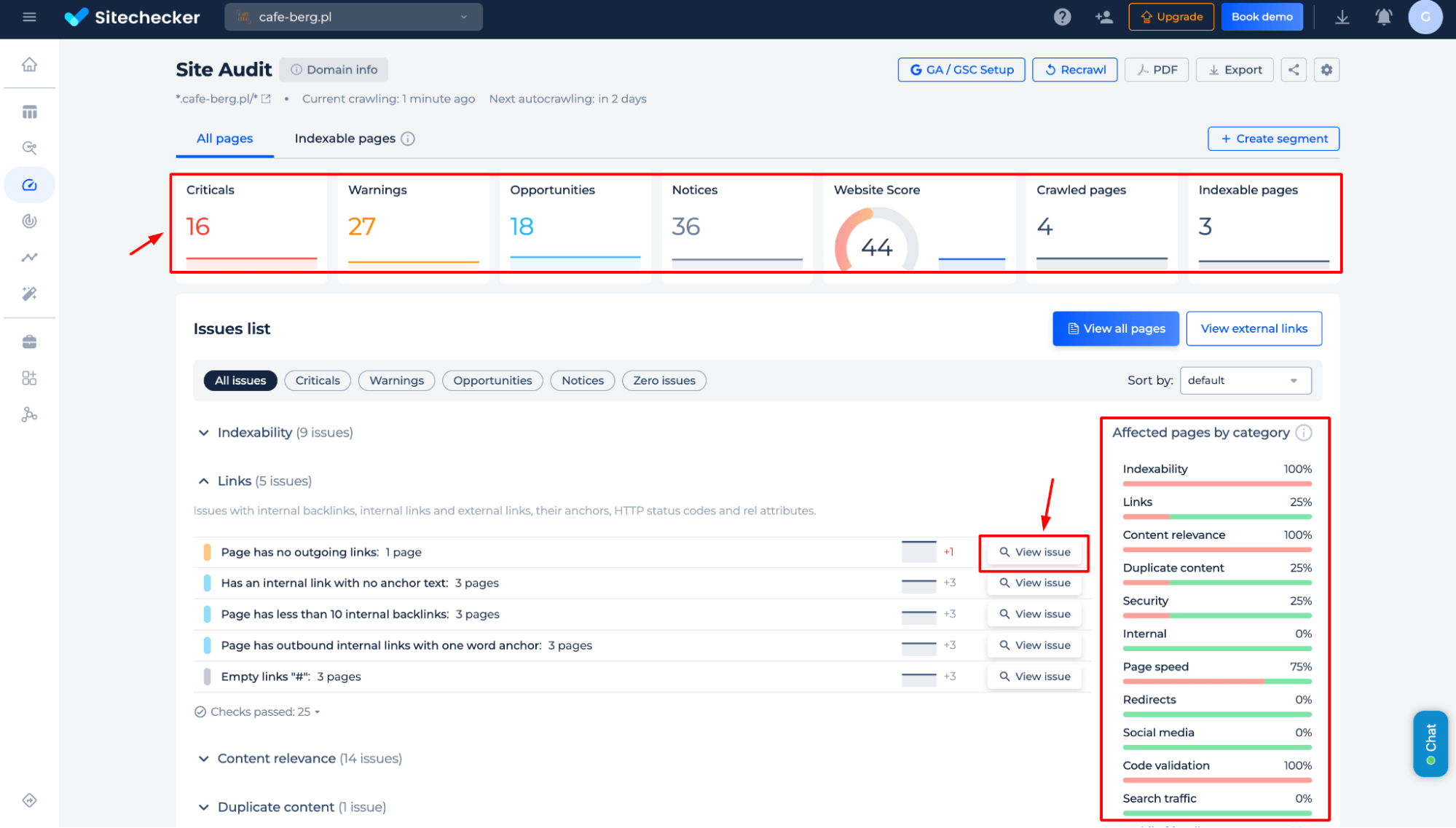
Additional features
Gain in-depth SEO insights beyond crawling status changes, including critical errors, warnings, opportunities, and overall website health. Analyze affected pages by category, detect technical issues, and access detailed reports with actionable fixes to optimize search performance.
Google Page Index Checker
Step 1: Choose a page check option
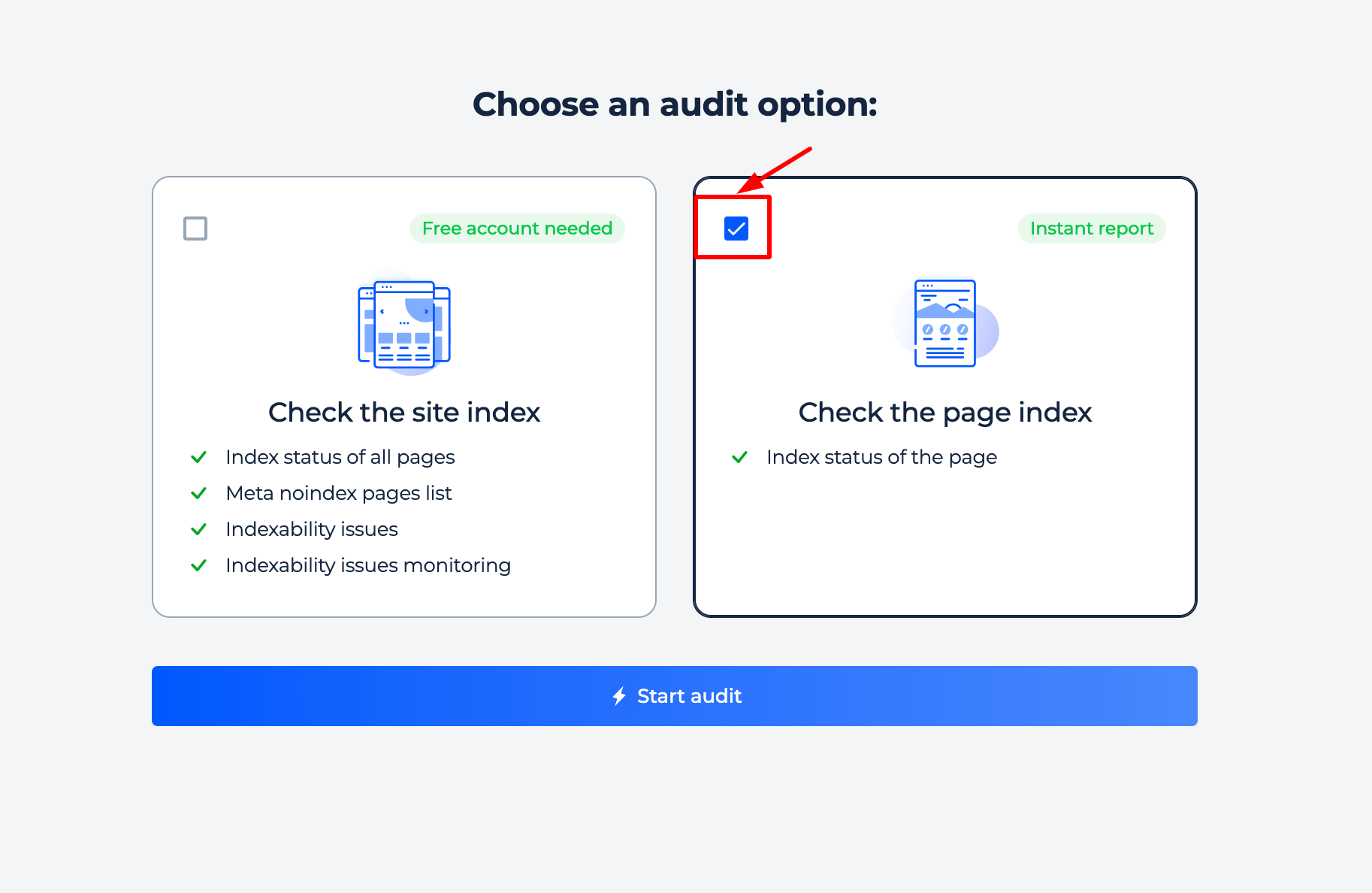
Step 2: Get the results
Get instant insights into a page’s crawlability, including status codes, meta tags, robots.txt settings, and noindex directives. Identify crawling status issues and ensure search engines can properly crawl and rank your page.
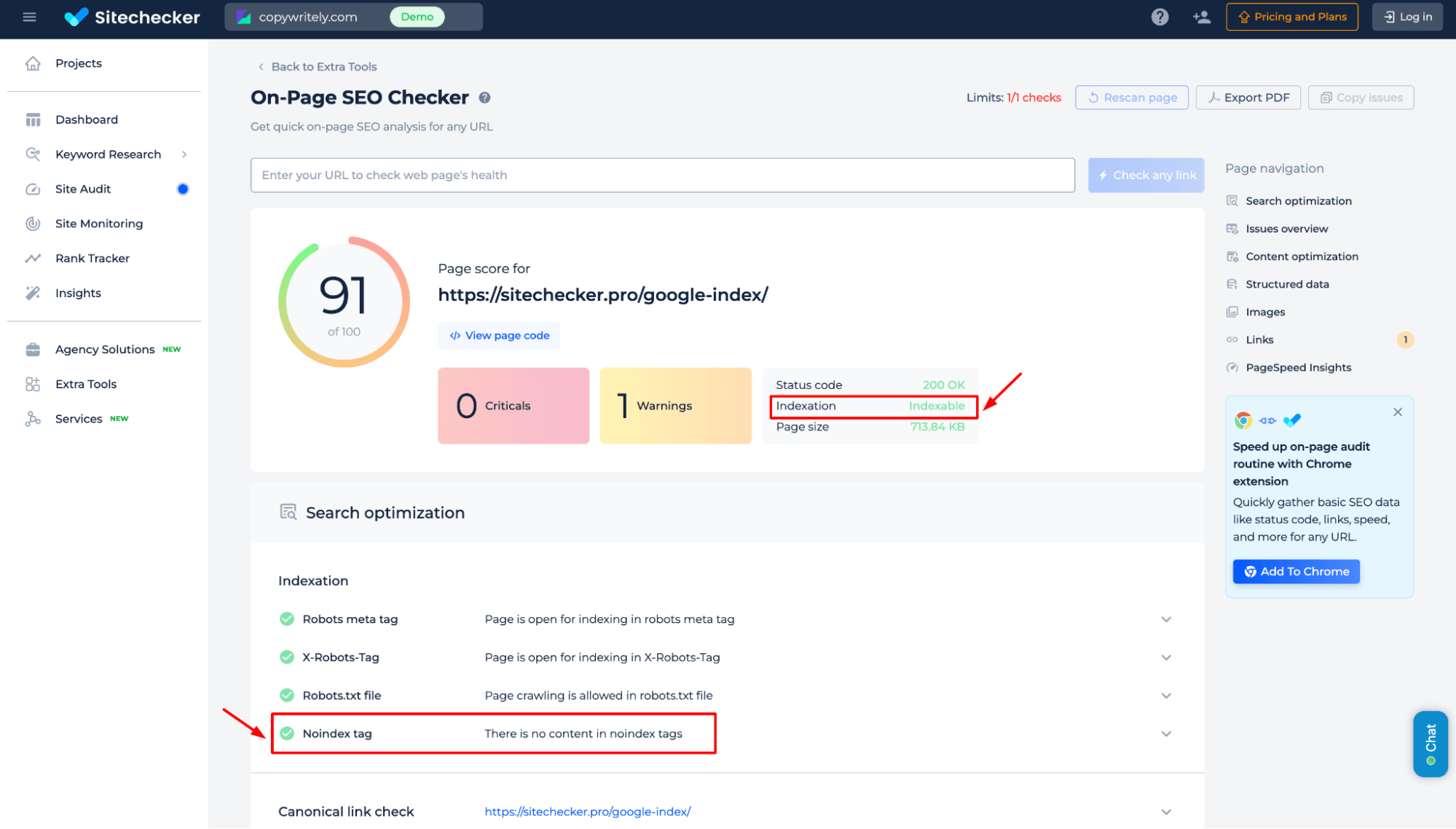
To explore all the tool’s features, go to the Site Audit section. There, you can view the demo version and see which technical SEO tasks Sitechecker can solve.
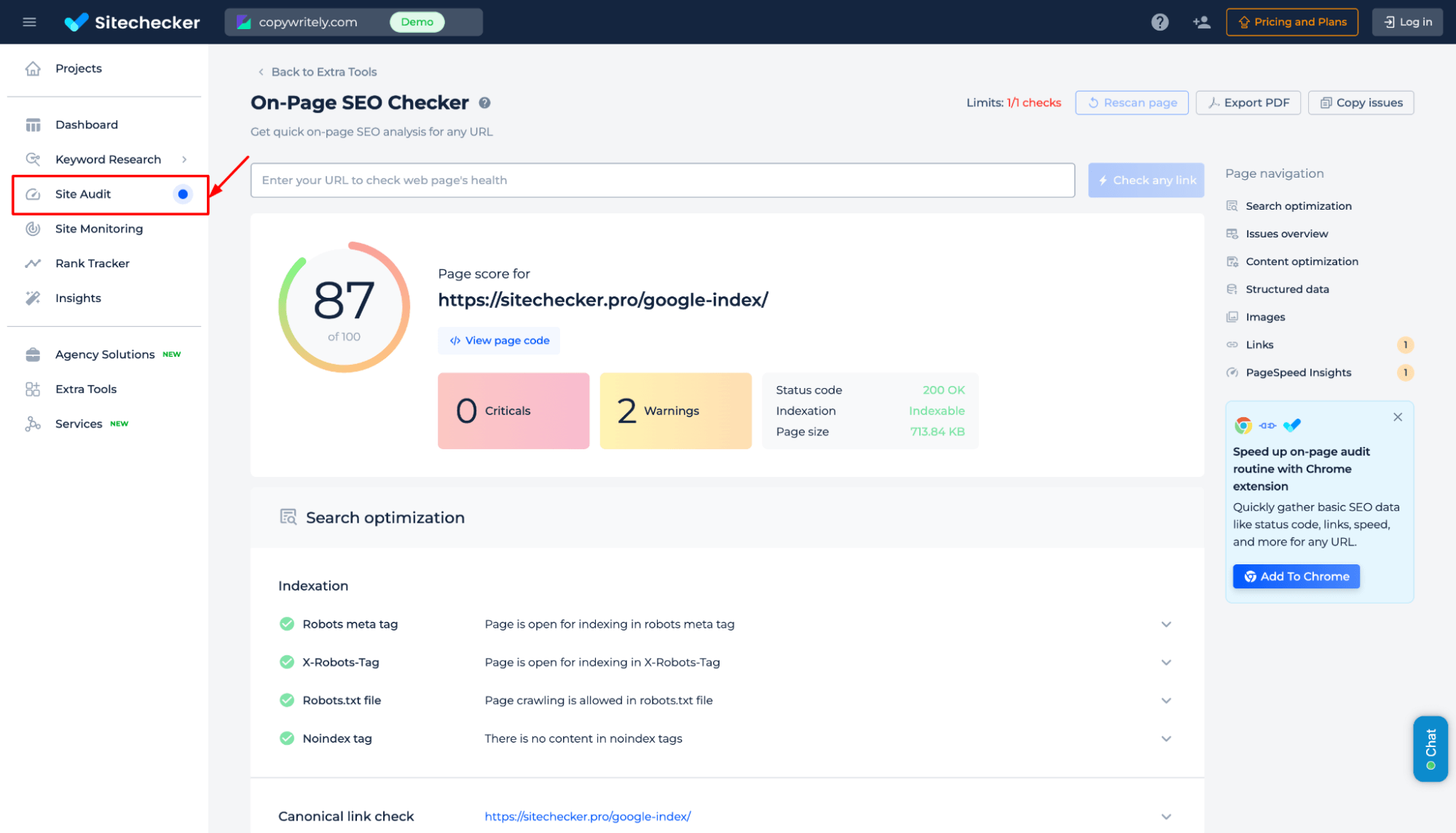
Additional features of the page check
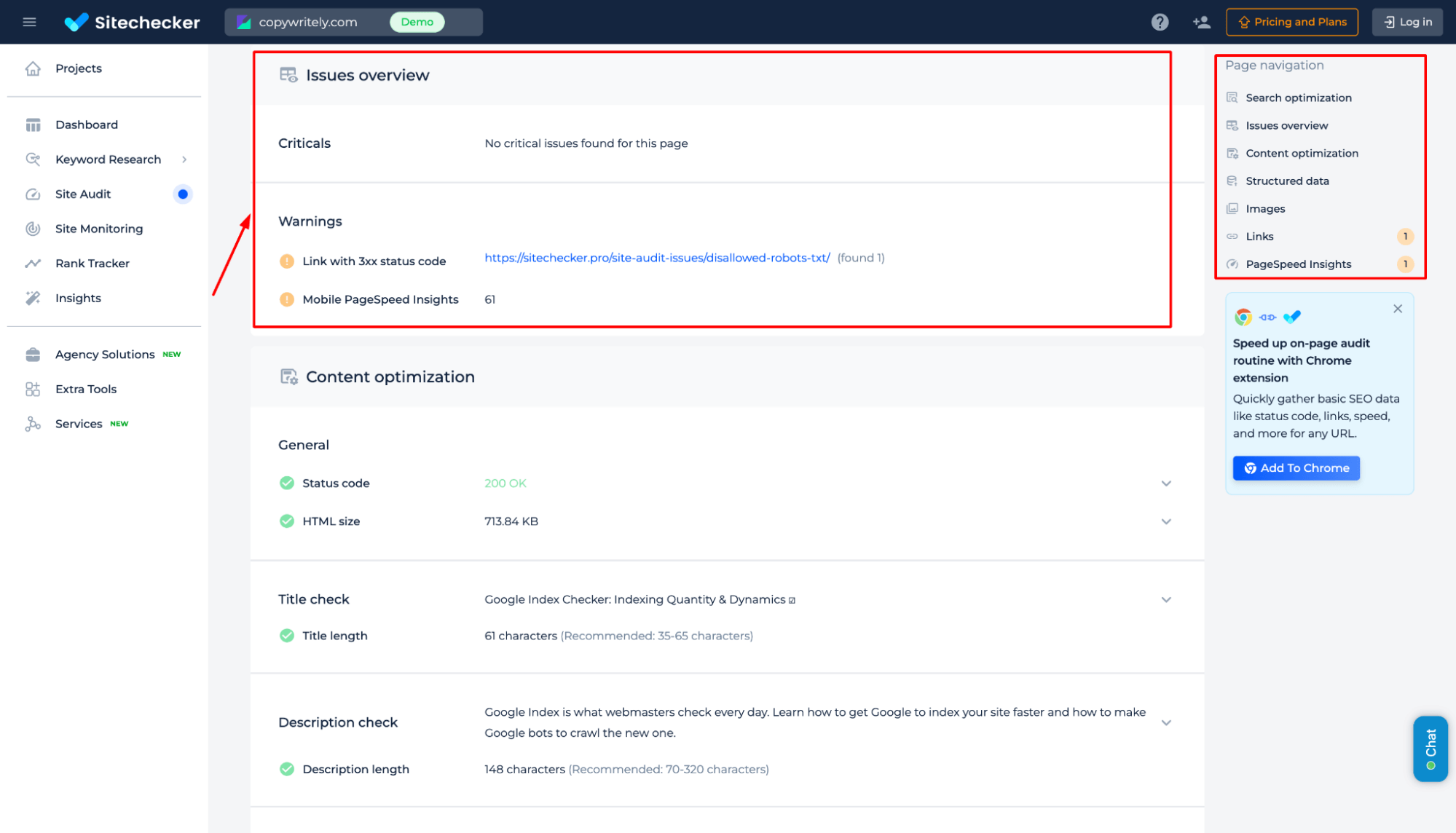
Gain a comprehensive SEO analysis beyond crawling status, including critical issues, warnings, and performance insights. Identify broken links, slow page speed, content optimization gaps, and structured data errors. Access detailed recommendations to enhance visibility, improve user experience, and boost search rankings.
Final Idea
The Google Indexing Checker helps users analyze website and page crawlability, identifying SEO issues affecting search visibility. It offers instant page checks or full site audits, detecting indexing errors, meta noindex tags, and technical problems. With a unified dashboard, user-friendly interface, and complete SEO toolset, it provides continuous tracking, performance insights, and actionable fixes. Users can access detailed reports on indexing, site health, and content optimization.







