


Un file robots.txt è un file di testo inserito nei siti web per informare i robot dei motori di ricerca (come Google) quali pagine di quel dominio possono essere scansionate . Se il tuo sito web ha un file robots.txt, puoi effettuare la verifica con il nostro strumento gratuito Generatore Robots.txt . Puoi integrare un link a una Mappa del sito XML nel file robots.txt.
Prima che i bot dei motori di ricerca eseguano la scansione del tuo sito, individueranno prima il file robots.txt del sito. Pertanto, vedranno le istruzioni su quali pagine del sito possono essere indicizzate e quali non devono essere indicizzate dalla console del motore di ricerca.
Con questo semplice file, puoi impostare le opzioni di scansione e indicizzazione per i bot dei motori di ricerca. E per verificare se il file Robots.txt è configurato sul tuo sito, puoi utilizzare i nostri strumenti gratuiti e semplici Tester Robots.txt. Questo articolo spiegherà come convalidare un file con lo strumento e perché è importante utilizzare Robots.txt Tester sul tuo sito.
Utilizzo dello strumento Robots.txt Checker: una guida passo passo
Il test di Robots.txt ti aiuterà a testare un file robots.txt sul tuo dominio o su qualsiasi altro dominio che desideri analizzare.
Lo strumento di controllo robots.txt rileverà rapidamente gli errori nelle impostazioni del file robots.txt. Il nostro strumento di convalida è molto facile da usare e può aiutare anche un professionista o un webmaster inesperto a controllare un file Robots.txt sul proprio sito. Otterrai i risultati in pochi istanti.
Passaggio 1: inserisci il tuo URL
Per avviare la scansione, tutto ciò che devi fare è inserire l’URL di interesse nella riga vuota e fare clic sul pulsante della freccia blu. Lo strumento avvierà quindi la scansione e genererà risultati. Non è necessario registrarsi sul nostro sito Web per utilizzarlo.
Ad esempio, abbiamo deciso di analizzare il nostro sito Web https://sitechecker.pro. Negli screenshot seguenti, puoi vedere il processo di scansione nel nostro strumento per i siti web.
Fase 2: interpretazione dei risultati del tester Robots.txt
Successivamente, al termine della scansione, vedrai se il file Robots.txt consente la scansione e l’indicizzazione di una particolare pagina disponibile. Pertanto, puoi verificare se la tua pagina web riceverà traffico dal motore di ricerca. Qui puoi anche ottenere alcuni consigli utili per il monitoraggio.

Casi in cui è necessario il controllo Robots.txt
I problemi con il file robots.txt, o la sua mancanza, possono influire negativamente sul posizionamento nei motori di ricerca. Potresti perdere punti in classifica nelle SERP. Analizzare questo file e il suo significato prima di eseguire la scansione del tuo sito web significa che puoi evitare problemi con la scansione. Inoltre, puoi impedire di aggiungere i contenuti del tuo sito web alle pagine di esclusione dell’indice di cui non desideri eseguire la scansione. Utilizza questo file per limitare l’accesso a determinate pagine del tuo sito. Se è presente un file vuoto, puoi ottenere un Problema di Robots.txt non trovato in SEO-crawler.
Puoi creare un file con un semplice editor di testo. Innanzitutto, specifica l’agente personalizzato per eseguire l’istruzione e posizionare la direttiva di blocco come disallow, noindex. Successivamente, elenca gli URL di cui stai limitando la scansione. Prima di eseguire il file, verifica che sia corretto. Anche un errore di battitura può far sì che Googlebot ignori le tue istruzioni di convalida.
Cosa possono aiutare gli strumenti di controllo robots.txt
Quando generi il file robots.txt, devi verificare se contengono errori. Ci sono alcuni strumenti che possono aiutarti a far fronte a questo compito.
Console di ricerca di Google
Ora solo la vecchia versione di Google Search Console dispone di uno strumento per testare il file robots. Accedi all’account con il sito corrente confermato sulla sua piattaforma e utilizza questo percorso per trovare il validatore.
Versione precedente di Google Search Console > Scansione > Tester di Robots.txt
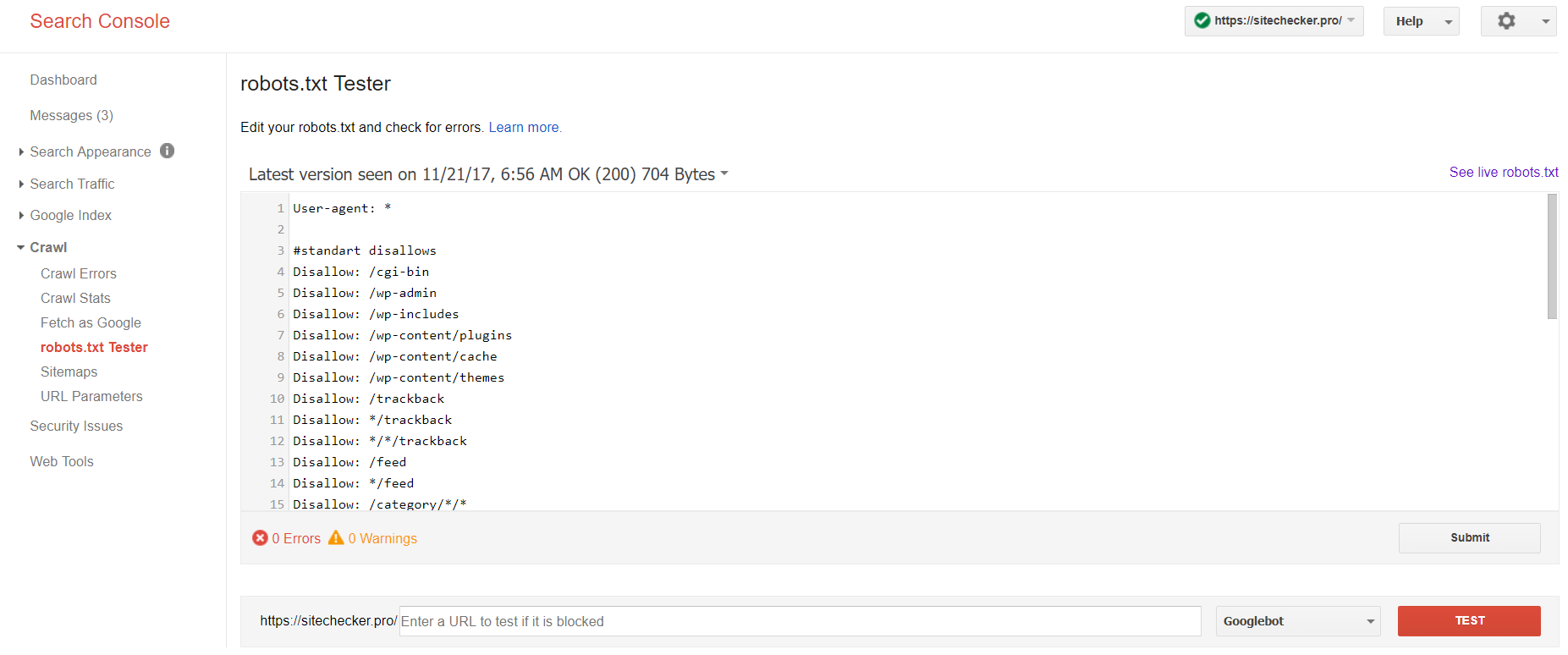
Questo test robot.txt ti consente di:
- rileva contemporaneamente tutti i tuoi errori e possibili problemi;
- verifica la presenza di errori e apporta le correzioni necessarie proprio qui per installare il nuovo file sul tuo sito senza ulteriori verifiche;
- esamina se hai chiuso in modo appropriato le pagine di cui desideri evitare la scansione e se quelle che dovrebbero subire l’indicizzazione sono state aperte in modo appropriato.
Webmaster Yandex
Accedi all’account Yandex Webmaster con la conferma del sito corrente confermato sulla sua piattaforma e utilizzare questo percorso per trovare lo strumento.
Webmaster Yandex > Strumenti > Analisi Robots.txt
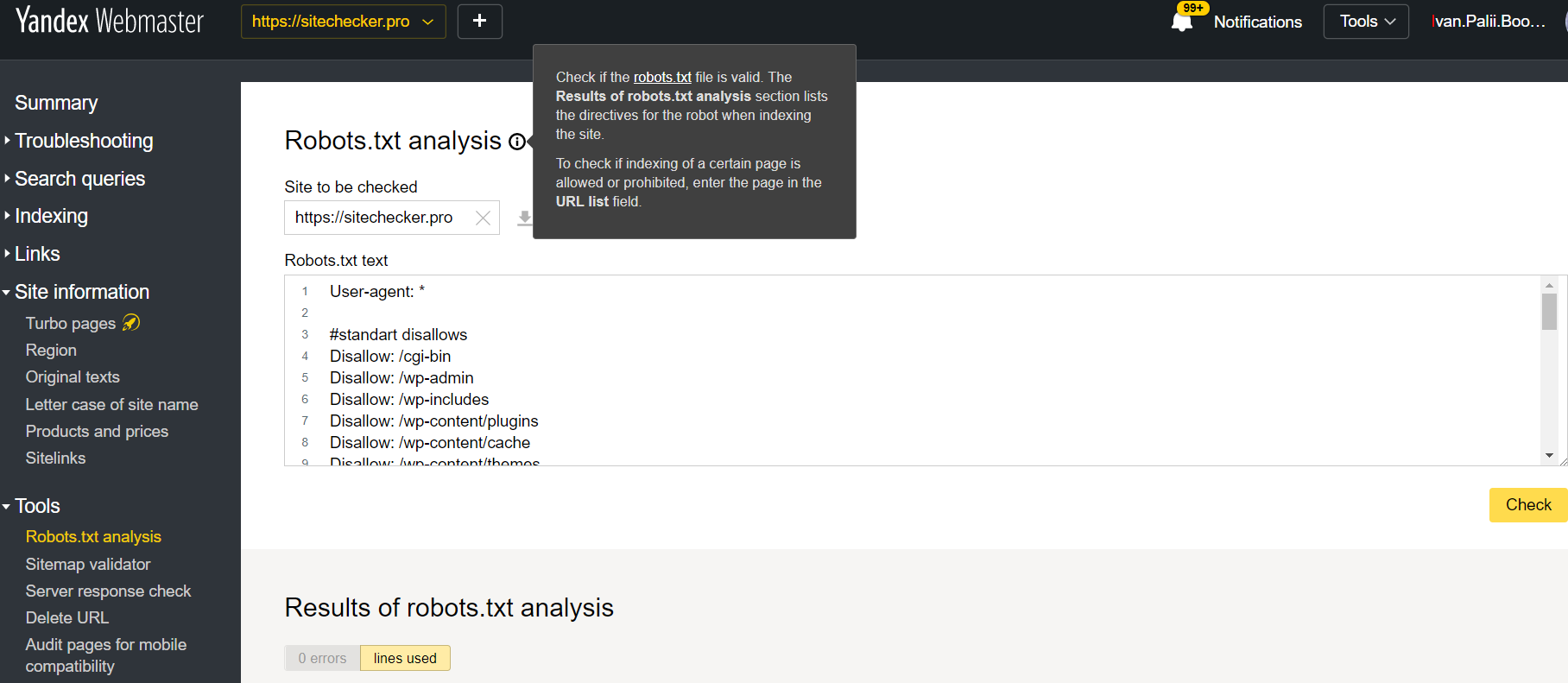
Questo tester offre opportunità di verifica quasi uguali a quelle sopra descritte. La differenza sta in:
- qui non è necessario autorizzare e dimostrare i diritti per un sito che offre una verifica immediata del file robots.txt;
- non è necessario inserire per pagina: è possibile controllare l’intero elenco di pagine in una sessione;
- puoi assicurarti che Yandex abbia identificato correttamente le tue istruzioni.
Crawler di Sitechecker
Questa è una soluzione per il controllo collettivo se è necessario eseguire la scansione del sito Web. Il nostro crawler aiuta a controllare l’intero sito Web e rilevare quali URL non sono consentiti in robots.txt e quali sono chiusi dall’indicizzazione tramite il meta tag noindex.
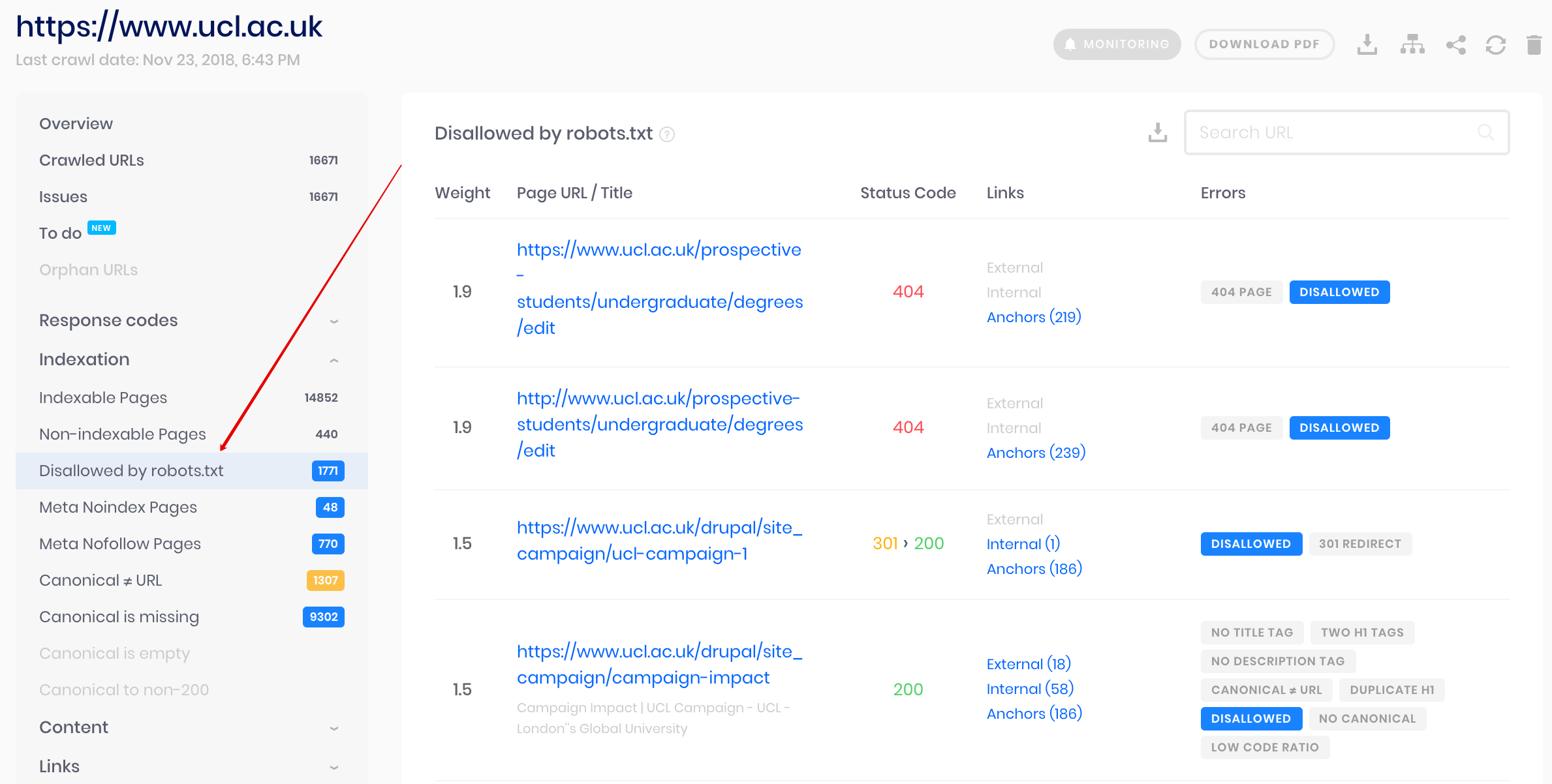
Fai attenzione: per rilevare le pagine non consentite dovresti eseguire la scansione del sito web con l’impostazione “ignore robots.txt”.
Rileva e analizza non solo il file robots.txt ma anche altri tipi di problemi SEO sul tuo sito!
Esegui un audit completo per scoprire e risolvere i problemi del tuo sito Web al fine di migliorare i risultati della SERP.
Perché devo controllare il mio file Robots.txt?
Robots.txt mostra ai motori di ricerca quali URL del tuo sito possono scansionare e indicizzare, principalmente per evitare di sovraccaricare il tuo sito con le query. Si consiglia di controllare questo file valido per assicurarsi che funzioni correttamente.







