


Een robots.txt-bestand is een tekstbestand dat op websites wordt geplaatst om robots van zoekmachines (zoals Google) te laten weten welke pagina’s op dat domein kunnen worden gecrawld . Als uw website een robots.txt-bestand heeft, kunt u verificatie uitvoeren met onze gratis Robots.txt-generator tool. U kunt een link naar een XML-sitemap integreren in het robots.txt-bestand.
Voordat zoekmachinebots uw site crawlen, zullen ze eerst het robots.txt-bestand van de site vinden. Ze zullen dus instructies zien op welke sitepagina’s kunnen worden geïndexeerd en welke niet geïndexeerd door de console van de zoekmachine.
Met dit eenvoudige bestand kunt u opties voor crawlen en indexeren instellen voor bots van zoekmachines. En om te controleren of het Robots.txt-bestand is geconfigureerd op uw site, u kunt onze gratis en eenvoudige Robots.txt-testtools gebruiken. In dit artikel wordt uitgelegd hoe u een bestand valideert met de tool en waarom het belangrijk is om Robots.txt Tester op uw site te gebruiken.
Gebruik van Robots.txt Checker Tool: een stapsgewijze handleiding
Met Robots.txt-testen kunt u een robots.txt-bestand testen op uw domein of een ander domein dat u wilt analyseren.
De robots.txt-controletool zal snel fouten detecteren in de instellingen van het robots.txt-bestand. Onze validatietool is zeer eenvoudig te gebruiken en kan zelfs een onervaren professional of webmaster helpen om een Robots.txt-bestand op hun site te controleren. U krijgt binnen enkele ogenblikken de resultaten .
Stap 1: Voer uw URL in
Om te beginnen met scannen, hoeft u alleen maar de gewenste URL in de lege regel in te voeren en op de blauwe pijlknop te klikken. De tool begint dan met scannen en genereert resultaten. U hoeft zich niet te registreren op onze website om deze te gebruiken.
Als voorbeeld hebben we besloten om onze website https://sitechecker.pro te analyseren. In de onderstaande schermafbeeldingen ziet u het scanproces in onze websitetool.
Stap 2: Interpretatie van de Robots.txt-testerresultaten
Vervolgens, wanneer de scan is voltooid, zult u zien of het Robots.txt-bestand het crawlen en indexeren van een bepaalde beschikbare pagina toestaat. Zo kunt u controleren of uw webpagina verkeer van de zoekmachine ontvangt. Hier kunt u ook nuttig monitoringadvies krijgen.

Gevallen waarin Robots.txt Checker nodig is
Problemen met het robots.txt-bestand, of het ontbreken daarvan, kunnen een negatieve invloed hebben op uw positie in de zoekmachines. U kunt rankingpunten verliezen in de SERP’s. Als u dit bestand en de betekenis ervan analyseert voordat u uw website gaat crawlen, kunt u problemen met crawlen voorkomen. U kunt ook voorkomen dat de inhoud van uw website wordt toegevoegd aan de pagina’s met uitsluitingsindexen die u niet wilt laten crawlen. Gebruik dit bestand om de toegang tot bepaalde pagina’s op uw site te beperken. Als er een leeg bestand is, kunt u een Robots.txt not Found-probleem krijgen in SEO-crawler.
U kunt een bestand maken met een eenvoudige teksteditor. Geef eerst de aangepaste agent op om de instructie uit te voeren en plaats de blokkeringsrichtlijn zoals disallow, noindex. Vermeld daarna de URL’s die u het crawlen beperkt. Controleer voordat u het bestand uitvoert of het correct is. Zelfs een typefout kan ertoe leiden dat Googlebot je validatie-instructies negeert.
Welke tools voor het controleren van robots.txt kunnen helpen
Wanneer u het robots.txt-bestand genereert, moet u controleren of ze fouten bevatten. Er zijn een paar hulpmiddelen die u kunnen helpen om met deze taak om te gaan.
Google Search Console
Nu heeft alleen de oude versie van Google Search Console een tool om robots-bestanden te testen. Meld u aan bij het account met de huidige site die op het platform is bevestigd en gebruik dit pad om de validator te vinden.
Oude versie van Google Search Console > Kruipen > Robots.txt-tester
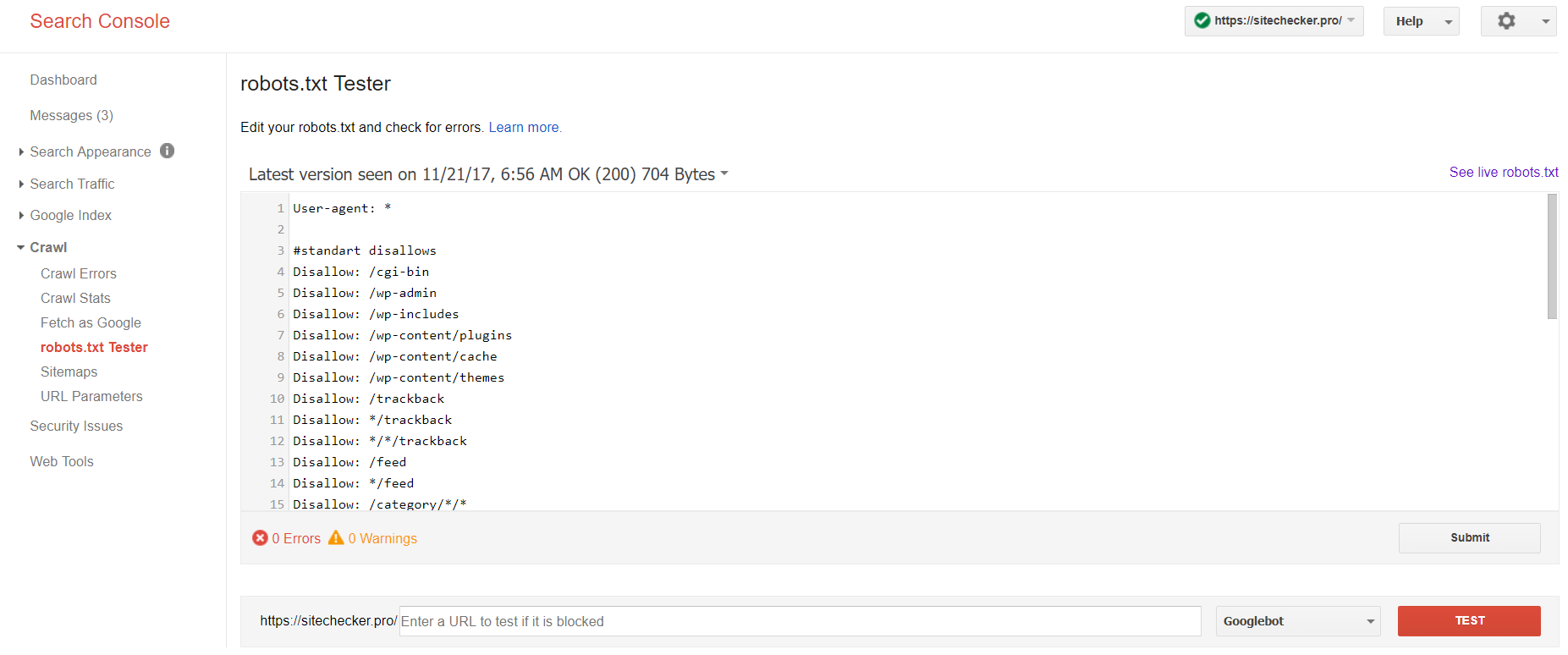
Met deze robot.txt-test kunt u:
- detecteer al uw fouten en mogelijke problemen tegelijk;
- controleer op fouten en breng hier de nodige correcties aan om het nieuwe bestand op uw site te installeren zonder aanvullende verificaties;
- bekijk of u de pagina’s die u niet wilt laten crawlen op de juiste manier heeft gesloten en of de pagina’s die indexatie zouden moeten ondergaan, op de juiste manier zijn geopend.
Yandex-webmaster
Log in op Yandex Webmaster-account met de huidige site bevestigen bevestigd op zijn platform en gebruik dit pad om de tool te vinden.
Yandex-webmaster > Gereedschap > Robots.txt-analyse
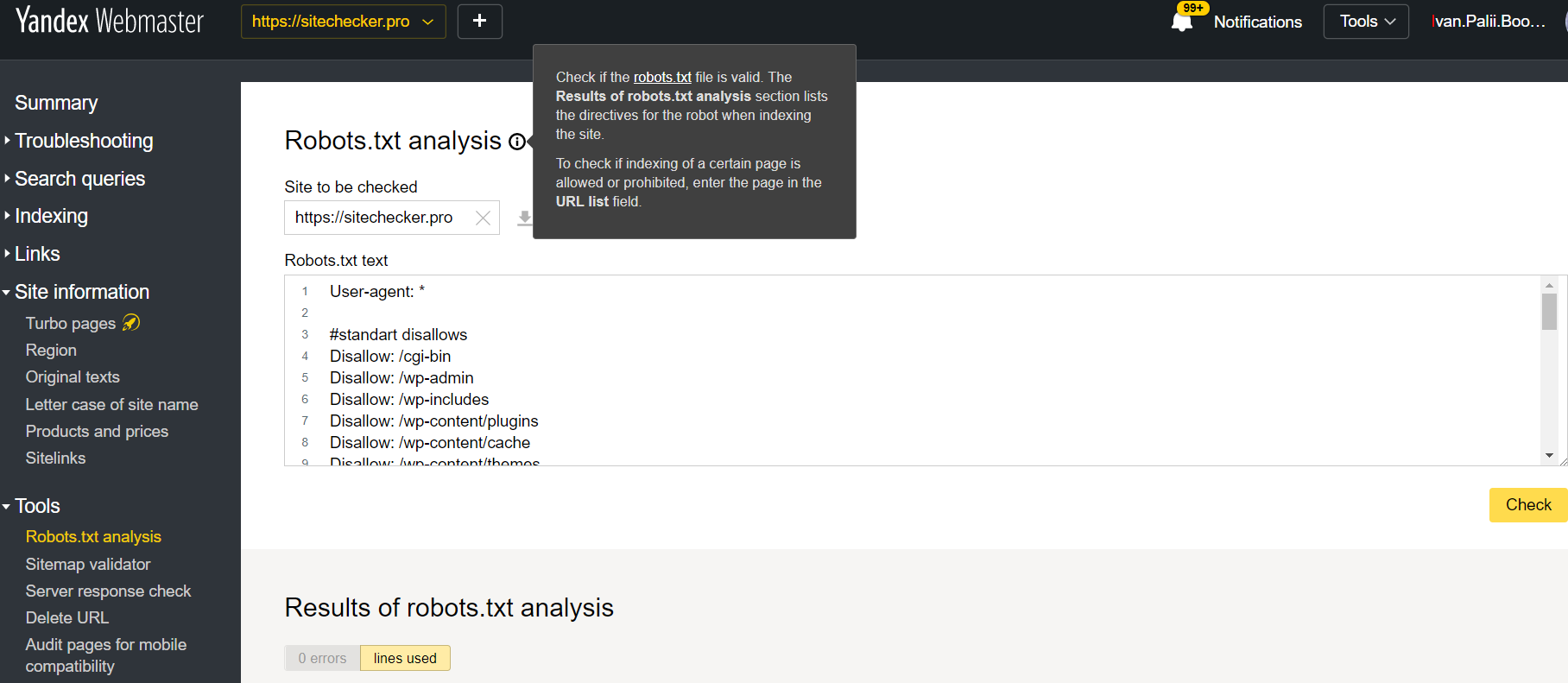
Deze tester biedt bijna gelijke mogelijkheden voor verificatie als hierboven beschreven. Het verschil zit in:
- hier hoeft u geen toestemming te geven en de rechten te bewijzen voor een site die een directe verificatie van uw robots.txt-bestand biedt;
- het is niet nodig om per pagina in te voegen: de volledige lijst met pagina’s kan binnen één sessie worden gecontroleerd;
- u kunt er zeker van zijn dat Yandex uw instructies correct heeft geïdentificeerd.
Sitechecker-crawler
Dit is een oplossing voor bulkcontrole als u website moet crawlen. Onze crawler helpt de hele website te controleren en te detecteren welke URL’s niet zijn toegestaan in robots.txt en welke URL’s zijn uitgesloten van indexering via noindex-metatag.
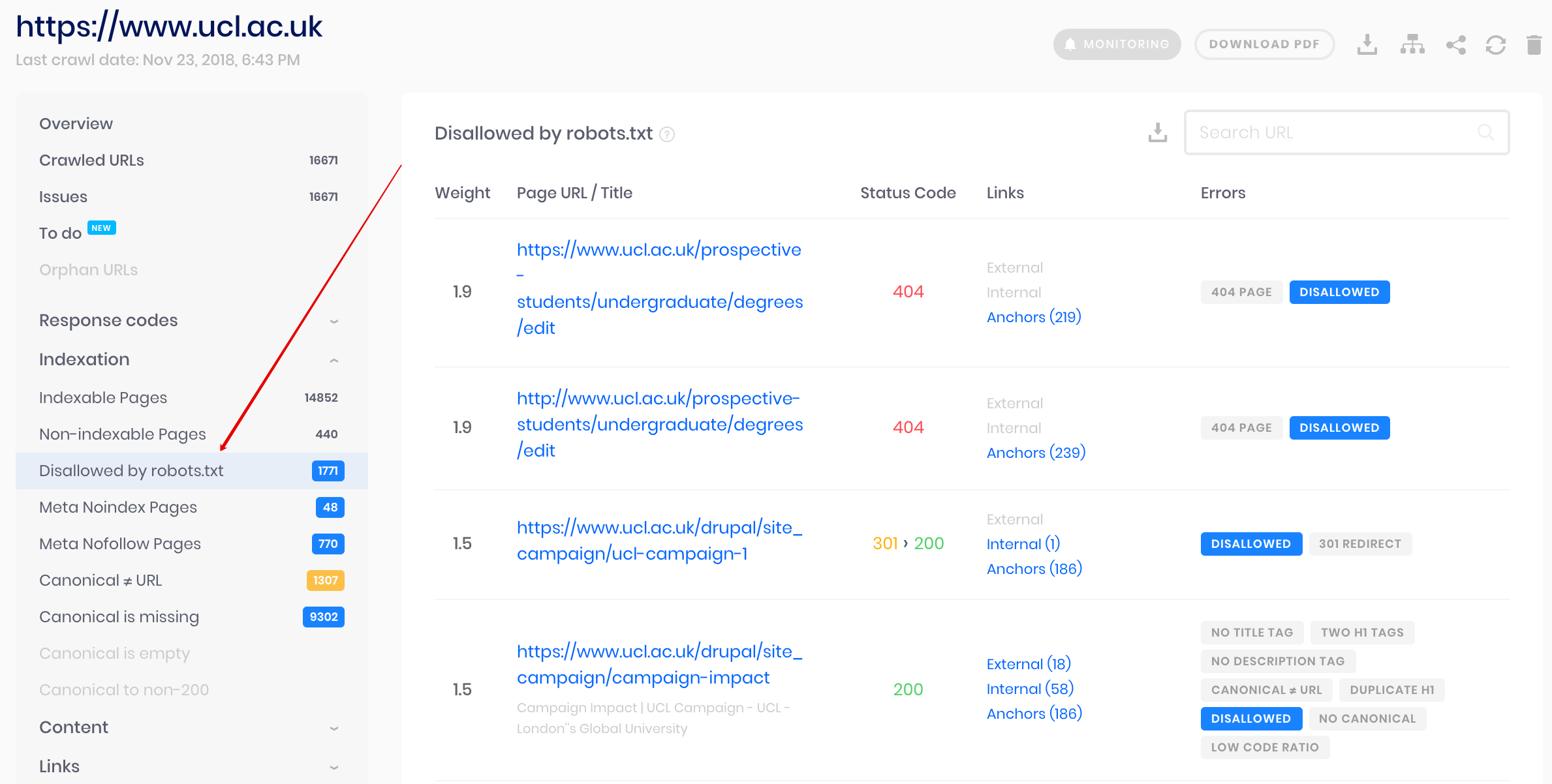
Let op: om niet-toegestane pagina’s te detecteren, moet u de website crawlen met de instelling ‘negeer robots.txt’.
Detecteer en analyseer niet alleen het robots.txt-bestand, maar ook andere soorten SEO-problemen op uw site!
Voer een volledige audit uit om uw websiteproblemen te achterhalen en op te lossen om uw SERP-resultaten te verbeteren.
Waarom moet ik mijn Robots.txt-bestand controleren?
Robots.txt laat zoekmachines zien welke URL's op uw site ze kunnen crawlen en indexeren, voornamelijk om te voorkomen dat uw site overladen wordt met zoekopdrachten. Het wordt aanbevolen om dit geldige bestand te controleren om er zeker van te zijn dat het correct werkt.







