



Robots.txt is an important file for the proper operation of the site. This is where search engine crawlers find information about the pages of the web resource that should be scanned in the first place and which one should not be paid attention to at all. The robots.txt file is used when necessary to hide some parts of the site or the entire website from search engines. For example, a location with user personal information or a mirror of the site.
What should I do if the system auditor does not see this file? Read about this and other issues related to the robots.txt file in our article.
How Does robots.txt Work?
A robots.txt is a txt document with UTF-8 encoding. This file works for http, https, and FTP protocols. The encoding type is very important: if the robots.txt file is encoded in a different format, the search engine will not be able to read the document and determine which pages should be recognized or not. Other requirements for the robots.txt file are as follows:
- all settings in the file are relevant only for the site where the robots.txt is located;
- the file location is the root directory; the URL should look like this: https://site.com.ua/robots.txt;
- the file size should not exceed 500 Kb.
When scanning the robots.txt file, search crawlers are granted permission to crawl all or some web pages; they can also be prohibited from doing so.
You can about this here.
Search Engine Response Codes
A web crawler scans the robots.txt file and gets the following responses:
- 5XX – markup of a temporary server error, at which, the scanning stops;
- 4XX – permission to scan each page of the site;
- 3XX – redirect until the crawler gets another answer. After 5 attempts, a 404 error is fixed;
- 2XX – successful scanning; all pages that need to be read are recognized.
If when navigating to https://site.com.ua/robots.txt, the search engine does not find or see the file, the response will be “robots.txt not Found”.
Reasons for the “robots.txt not Found” Response
Causes of the “robots.txt not Found” search crawler response may be the following:
- the text file is located at a different URL;
- the robots.txt file is not found on the website.
More information on this video by John Muller from Google.
Please note! The robots.txt file is located in the main domain directory as well as in subdomains. If you have included subdomains in the site audit, the file must be available; otherwise, the crawler will report an error stating that robots.txt is not found.
How to Check the Issue?
If a web crawler cannot find the robots.txt file, it might be due to the file not being placed in the correct location or it might not exist at all. To check this issue, first, make sure that the robots.txt file is located at the root of your website domain (e.g., https://www.yoursite.com/robots.txt). You can manually enter this URL in your web browser to see if the file can be accessed. If the file isn’t found, you need to create a robots.txt file and upload it to your root directory. This file tells crawlers which pages or sections of your site should not be processed or scanned.
Also, ensure that your server permissions allow search engines to access the robots.txt file. If it’s correctly placed and still not detectable, check your server’s configuration or contact your hosting provider for further assistance.
The Sitechecker SEO tool provides an insightful feature that identifies issues related to an invalid robots.txt file on your website. By navigating to the “Site Audit” section and focusing on the “Indexability” issues, users can specifically pinpoint the problem labeled “Site has an invalid robots.txt file.”
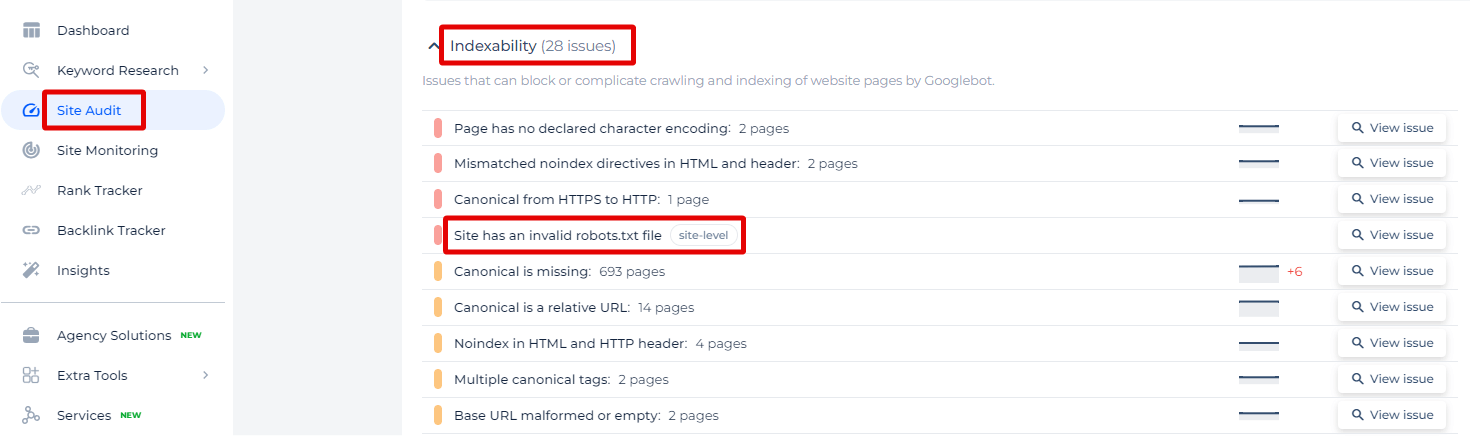
By clicking on “View issue,” you can access a detailed list of specific problems detected within your robots.txt file.
Unlock Better SEO: Validate Your Robots.txt Now!
Use our comprehensive site audit tool to identify and fix issues with your robots.txt file today!
Why is This Important?
Failure to fix the “robots.txt not Found” error will result in incorrect work of search crawlers due to incorrect commands from the file. This, in turn, may lead to a drop in site ranking, incorrect data on site traffic. Also, if search engines do not see robots.txt, all pages of your site will be crawled, which is undesirable. As a result, you can miss the following problems:
- server overload;
- purposeless crawling of pages with the same content by search engines;
- longer time to process visitor requests.
The smooth operation of the robots.txt file is crucial for the smooth operation of your web resource. Therefore, let’s examine how to fix errors in the work of this test document.
How to Fix This Issue
The issue “robots.txt not found” occurs when search engine crawlers attempt to access your website’s crawler directive, but it doesn’t exist. This document manages and controls how search engines index your website. Here’s how you can fix this issue:
1. Create a robots.txt File
Create a text document named robots.txt in the root directory of your website. This file should be accessible at https://yourdomain.com/robots.txt.
2. Add Basic Directives
Add the basic directives. Here’s a simple example:
User-agent: *
Disallow: /private/
Allow: /
This file instructs all search engine crawlers (User-agent: *) to avoid indexing the /private/ directory but allows everything else.
3. Upload the robots.txt File
Upload the crawler directive to the root directory of your website using an FTP client or through your web hosting control panel.
4. Verify Accessibility
Ensure the the bot access directive is accessible by visiting https://yourdomain.com/robots.txt in a web browser. You should see the contents of the link displayed.

5. Check Server Configuration
Make sure your web server is configured to serve the crawler directives correctly. For example, the .htaccess file should not block access to the bot access directive if you’re using Apache.
6. Test Using Webmaster Tools
Robots.txt Tester by Sitechecker:
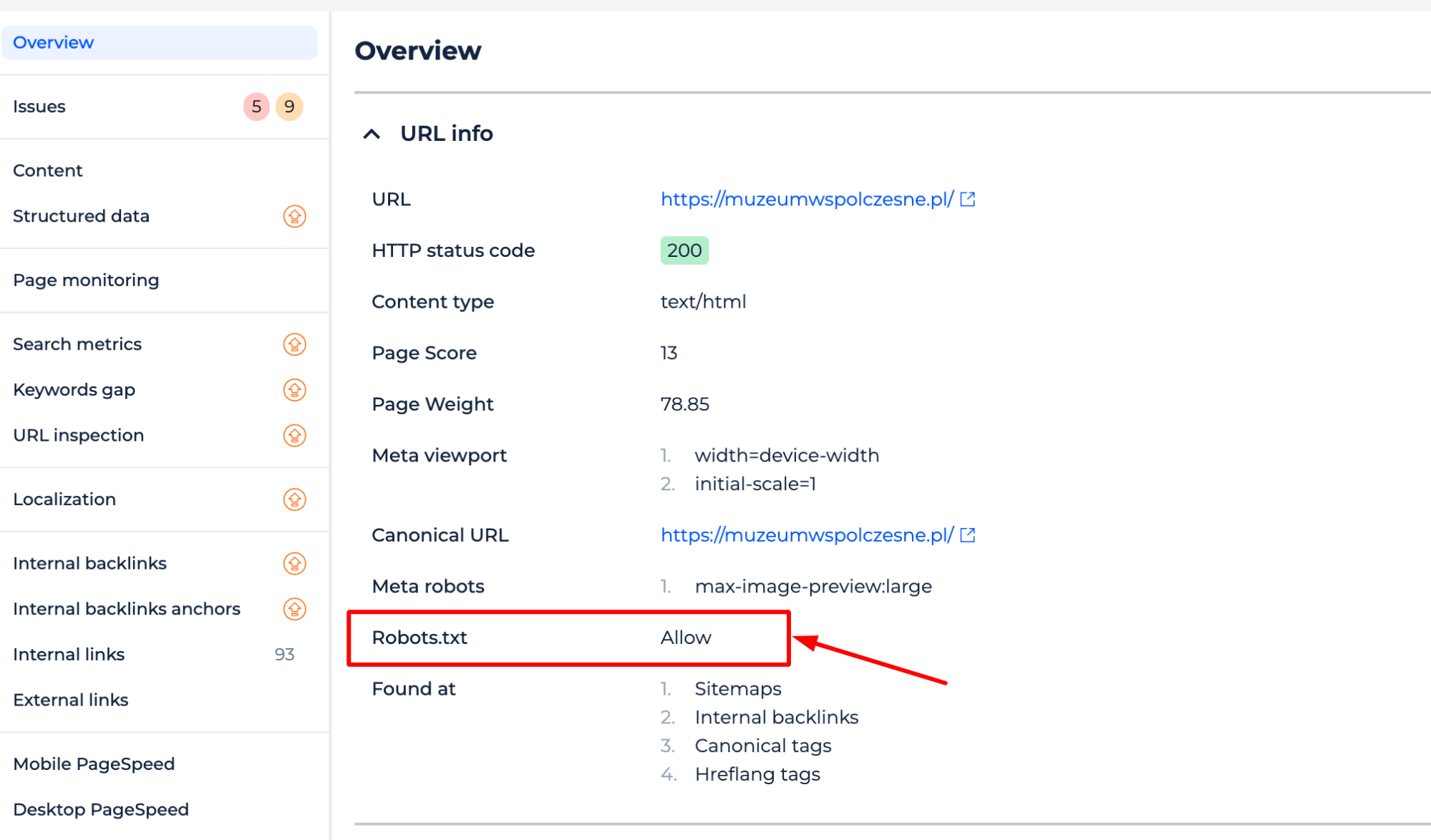
Google Search Console
1. Log in to Google Search Console.
2. Select your website.
3. Navigate to the “Settings”
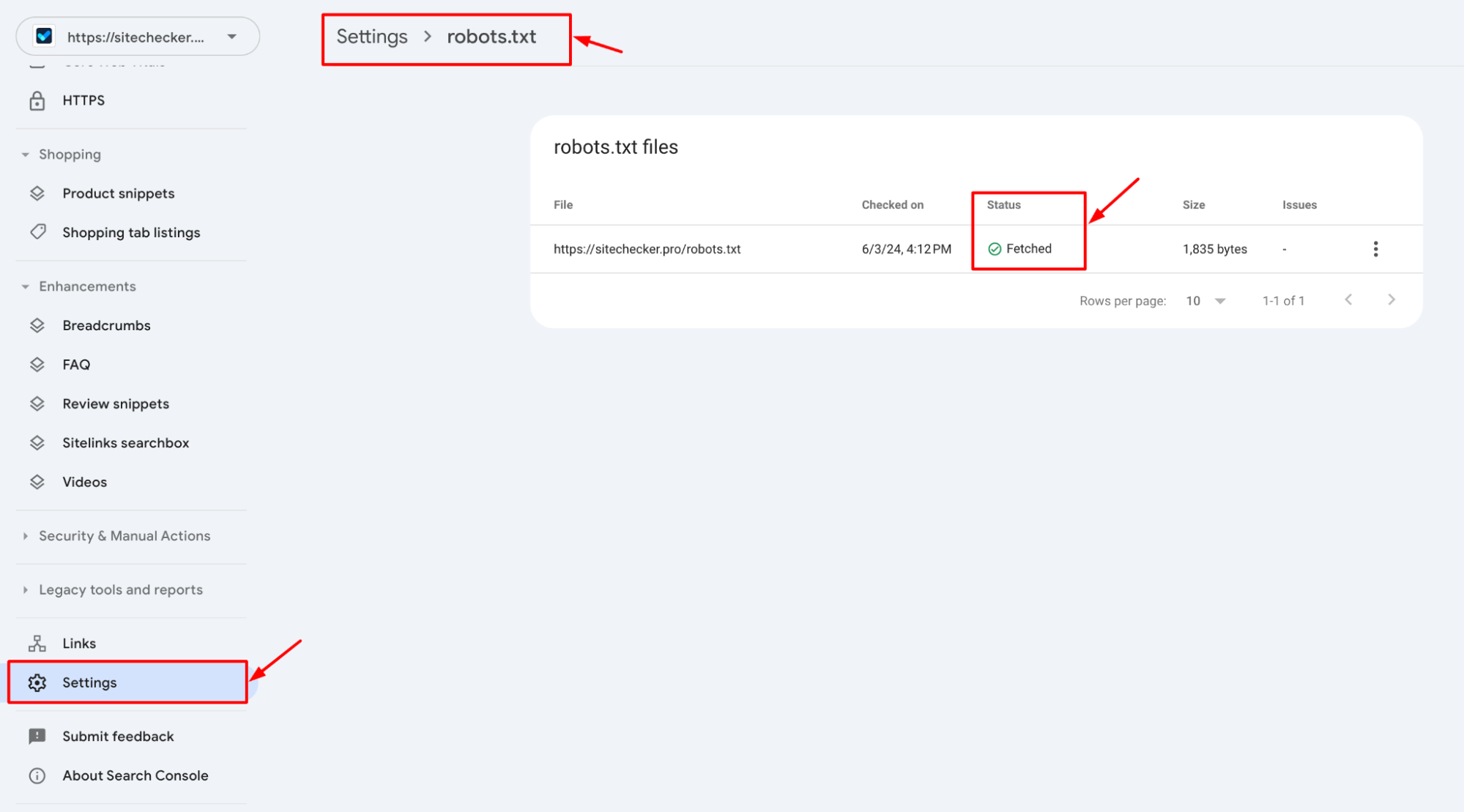
4. Test your robots.txt file and make sure it’s accessible.
Example of a Comprehensive robots.txt File
Here’s an example of a more comprehensive crawler directives with additional directives:
User-agent: *
Disallow: /private/
Disallow: /tmp/
Disallow: /test/
# Allow specific files
Allow: /test/allowed-file.html
# Sitemap location
Sitemap: https://yourdomain.com/sitemap.xml
Troubleshooting
- File Permissions. Ensure the web crawler rules have the correct permissions (generally 644 for read access).
- Rewrite Rules. Check for any URL rewriting rules that might interfere with accessing the bot access directive.
- Caching Issues. Clear any server or browser cache that might be serving an old version of your site without the web crawler rules.
Additionally, using a Robots.txt Monitoring Tool can help you continuously track and manage your robots.txt file to ensure it remains accessible and correctly configured, preventing future issues that could affect your site’s crawling and indexing.
By following these steps, you can resolve the “robots.txt not found” issue.





