


Файл robots.txt – это текстовый файл, размещаемый на веб-сайтах для информирования роботов поисковых систем (таких как Google), какие страницы в этом домене можно сканировать. . Если на вашем веб-сайте есть файл robots.txt, вы можете выполнить проверку с помощью нашего бесплатного генератора Robots.txt инструмента. Вы можете интегрировать ссылку на XML карту сайта в файл robots.txt.
Прежде чем боты поисковых систем просканируют ваш сайт, они сначала найдут файл robots.txt сайта. Таким образом, они увидят инструкции, какие страницы сайта можно индексировать, а какие не следует индексировать консолью поисковой системы.
С помощью этого простого файла вы можете настроить параметры сканирования и индексирования для роботов поисковых систем. И чтобы проверить, настроен ли на вашем сайте файл robots.txt, вы можете использовать наши бесплатные и простые инструменты для тестирования Robots.txt. В этой статье объясняется, как проверить файл с помощью этого инструмента и почему важно использовать Robots.txt Tester на своем сайте.
Использование средства проверки robots.txt: пошаговое руководство
Тестирование файла robots.txt поможет вам протестировать файл robots.txt в вашем домене или любом другом домене, который вы хотите проанализировать.
Средство проверки robots.txt быстро обнаружит ошибки в настройках файла robots.txt. Наш инструмент проверки очень прост в использовании и может помочь даже неопытному профессионалу или веб-мастеру проверить файл Robots.txt на своем сайте. Вы получите результаты через несколько минут.
Шаг 1. Вставьте URL-адрес
Чтобы начать сканирование, все, что вам нужно сделать, это ввести интересующий URL-адрес в пустую строку и нажать кнопку с синей стрелкой. Затем инструмент начнет сканирование и выдаст результаты. Вам не нужно регистрироваться на нашем сайте, чтобы использовать его.
В качестве примера мы решили проанализировать наш сайт https://sitechecker.pro. На приведенных ниже снимках экрана вы можете увидеть процесс сканирования в нашем инструменте веб-сайта.
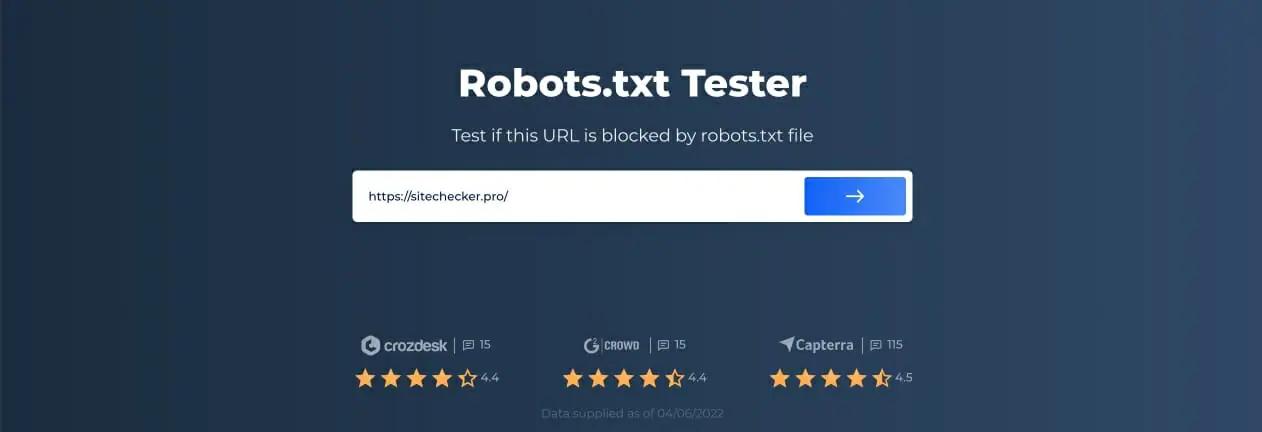
Шаг 2. Интерпретация результатов тестера Robots.txt
Затем, когда сканирование завершится, вы увидите, разрешает ли файл Robots.txt сканирование и индексирование конкретной доступной страницы. Таким образом, вы можете проверить, будет ли ваша веб-страница получать трафик из поисковой системы. Здесь вы также можете получить несколько полезных советов по мониторингу.

Случаи, когда требуется проверка robots.txt
Проблемы с файлом robots.txt или его отсутствие могут негативно повлиять на ваш рейтинг в поисковых системах. Вы можете потерять рейтинговые очки в SERP. Анализ этого файла и его значения перед сканированием веб-сайта позволяет избежать проблем с сканированием. Кроме того, вы можете предотвратить добавление контента вашего веб-сайта на страницы исключения из индекса, которые вы не хотите сканировать. Используйте этот файл, чтобы ограничить доступ к определенным страницам вашего сайта. Если есть пустой файл, вы можете получить сообщение Robots.txt не найден в SEO-краулер.
Вы можете создать файл с помощью простого текстового редактора. Во-первых, укажите пользовательский агент для выполнения инструкции и поместите директиву блокировки, например, disallow, noindex. После этого перечислите URL-адреса, для которых вы ограничиваете сканирование. Перед запуском файла убедитесь, что он правильный. Даже опечатка может привести к тому, что бот Googlebot проигнорирует ваши инструкции по проверке.
Какие инструменты проверки robots.txt могут помочь
Когда вы создаете файл robots.txt, вам необходимо проверить, не содержат ли они ошибок. Есть несколько инструментов, которые помогут вам справиться с этой задачей.
Консоль поиска Google
Теперь только в старой версии Google Search Console есть инструмент для тестирования файла robots. Войдите в учетную запись с текущим сайтом, подтвержденным на его платформе, и используйте этот путь, чтобы найти валидатор.
Старая версия Google Search Console > Сканировать > Тестер robots.txt
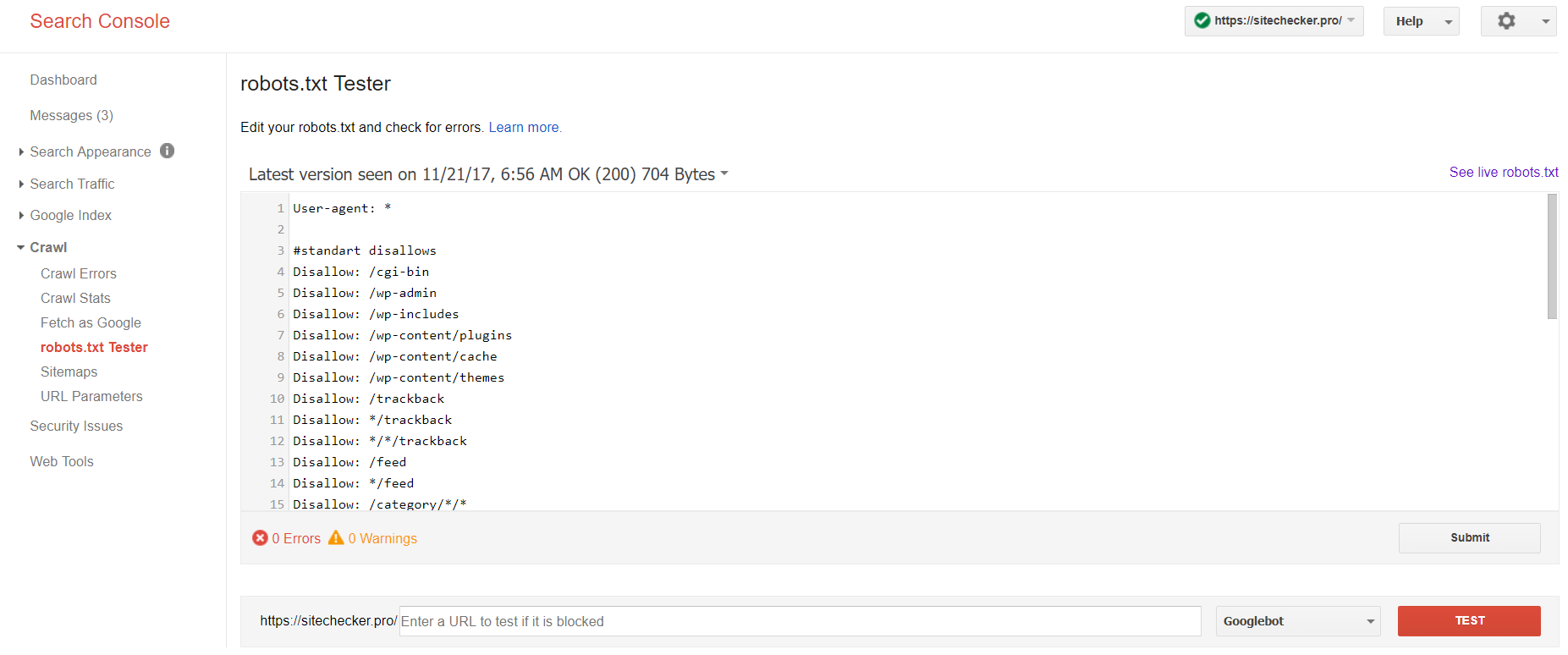
Этот тест robot.txt позволяет:
<ул>
Веб-мастер Яндекса
Войдите в аккаунт Яндекс Вебмастер с текущим сайтом и подтвержден на своей платформе и используйте этот путь, чтобы найти инструмент.
Яндекс для веб-мастеров > Инструменты > Анализ robots.txt
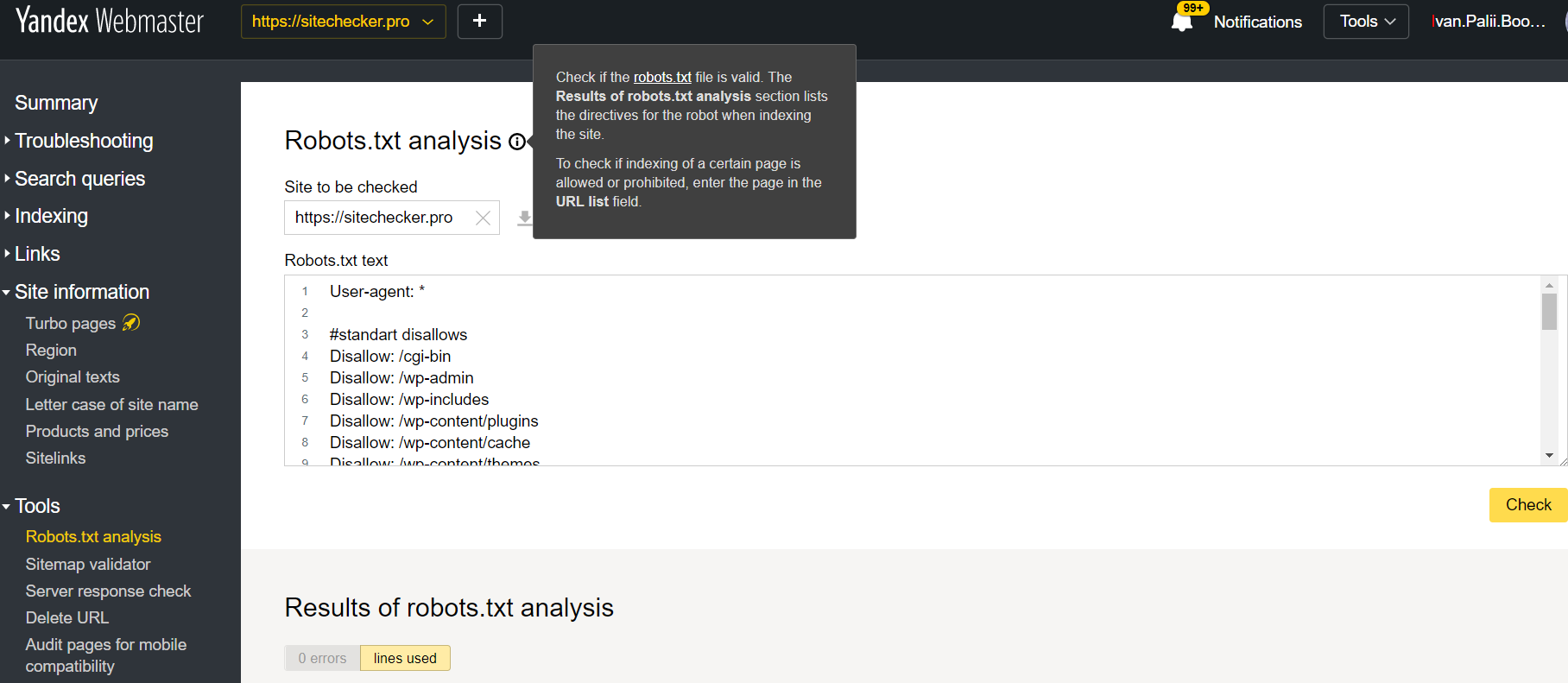
Этот тестер предлагает почти такие же возможности для проверки, как и описанный выше. Разница заключается в:
<ул>
Сканер проверки сайта
Это решение для массовой проверки, если вам нужно просканировать веб-сайт. Наш краулер помогает проверить весь сайт и определить, какие URL-адреса запрещены в robots.txt, а какие закрыты от индексации с помощью метатега noindex.
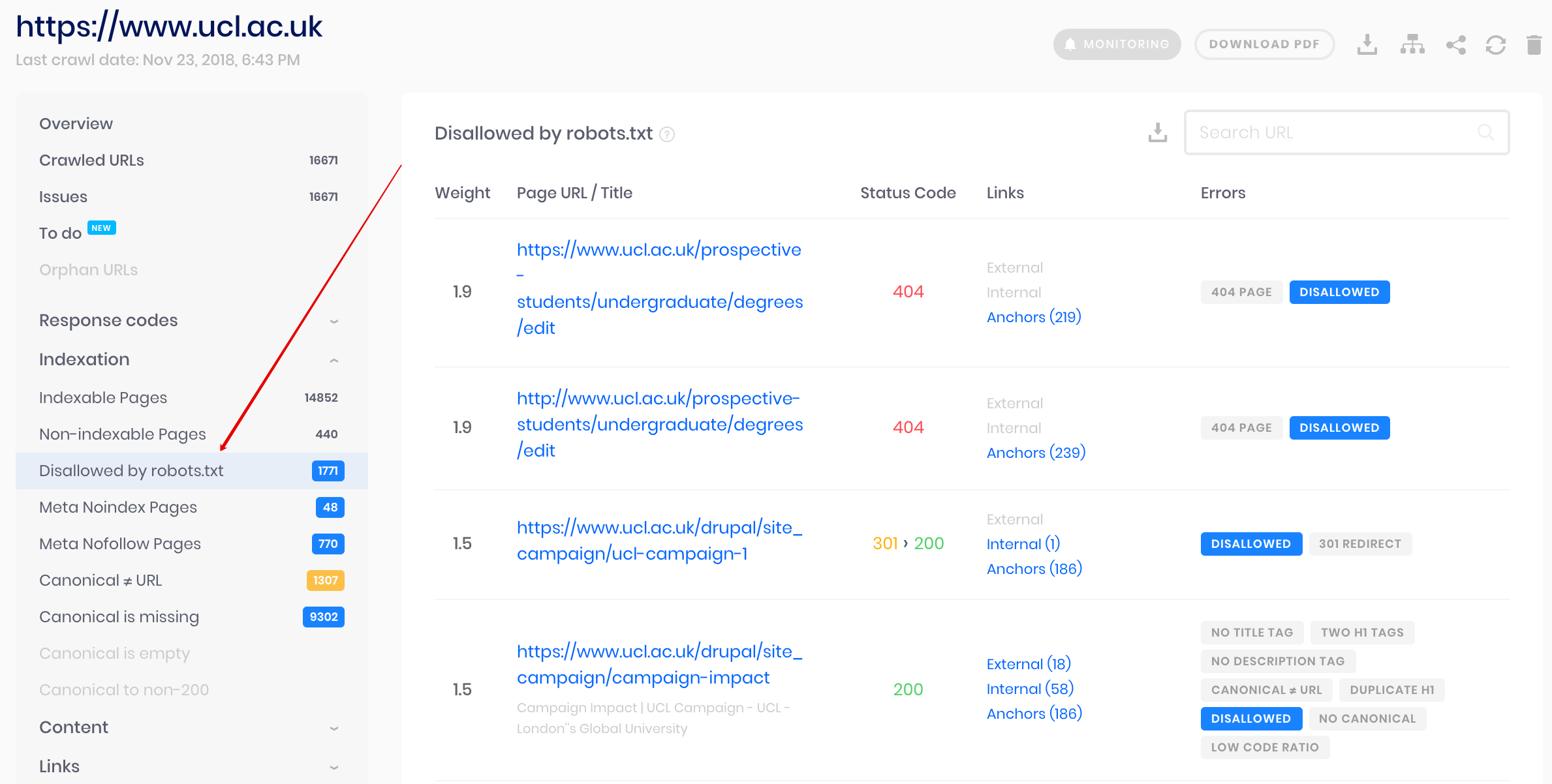
Внимание: для обнаружения запрещенных страниц необходимо просканировать веб-сайт с настройкой игнорировать robots.txt.
Обнаружение и анализ не только файла robots.txt, но и других проблем SEO на вашем сайте!
Проведите полный аудит, чтобы выяснить и исправить проблемы с вашим сайтом, чтобы улучшить результаты поисковой выдачи.







