


¿Qué es Robots.txt Tester?
La herramienta Robots.txt Tester de Sitechecker está diseñada para validar el archivo robots.txt de un sitio web, lo que garantiza que los bots de motores de búsqueda comprendan qué páginas deben indexarse o ignorarse. Esto facilita la gestión eficiente de la visibilidad de un sitio en los resultados de búsqueda. La herramienta ofrece comprobaciones integrales del sitio para identificar problemas de indexación y también proporciona análisis específicos de la página para determinar si una página está indexada. Esto mejora la precisión de la indexación del motor de búsqueda al identificar y corregir rápidamente cualquier error en la configuración del archivo robots.txt.
¿Cómo puede ayudarle la herramienta?
Validación del archivo robots.txt: verifica la exactitud del archivo robots.txt de un sitio web, lo que garantiza que dirija con precisión a los robots de los motores de búsqueda.
Análisis específicos de páginas: ofrece la posibilidad de comprobar si las páginas individuales están indexadas correctamente o no, lo que permite la resolución de problemas específicos.
Identificación de problemas de indexación: ofrece comprobaciones exhaustivas para detectar cualquier problema de indexación en todo el sitio.
Características clave de la herramienta
Panel de control unificado: ofrece una descripción general completa de las métricas de SEO para un fácil monitoreo.
Interfaz fácil de usar: diseñada para una navegación intuitiva y fácil de usar.
Conjunto completo de herramientas de SEO: ofrece una amplia gama de herramientas para optimizar el rendimiento del sitio web en los motores de búsqueda.
Cómo utilizar la herramienta
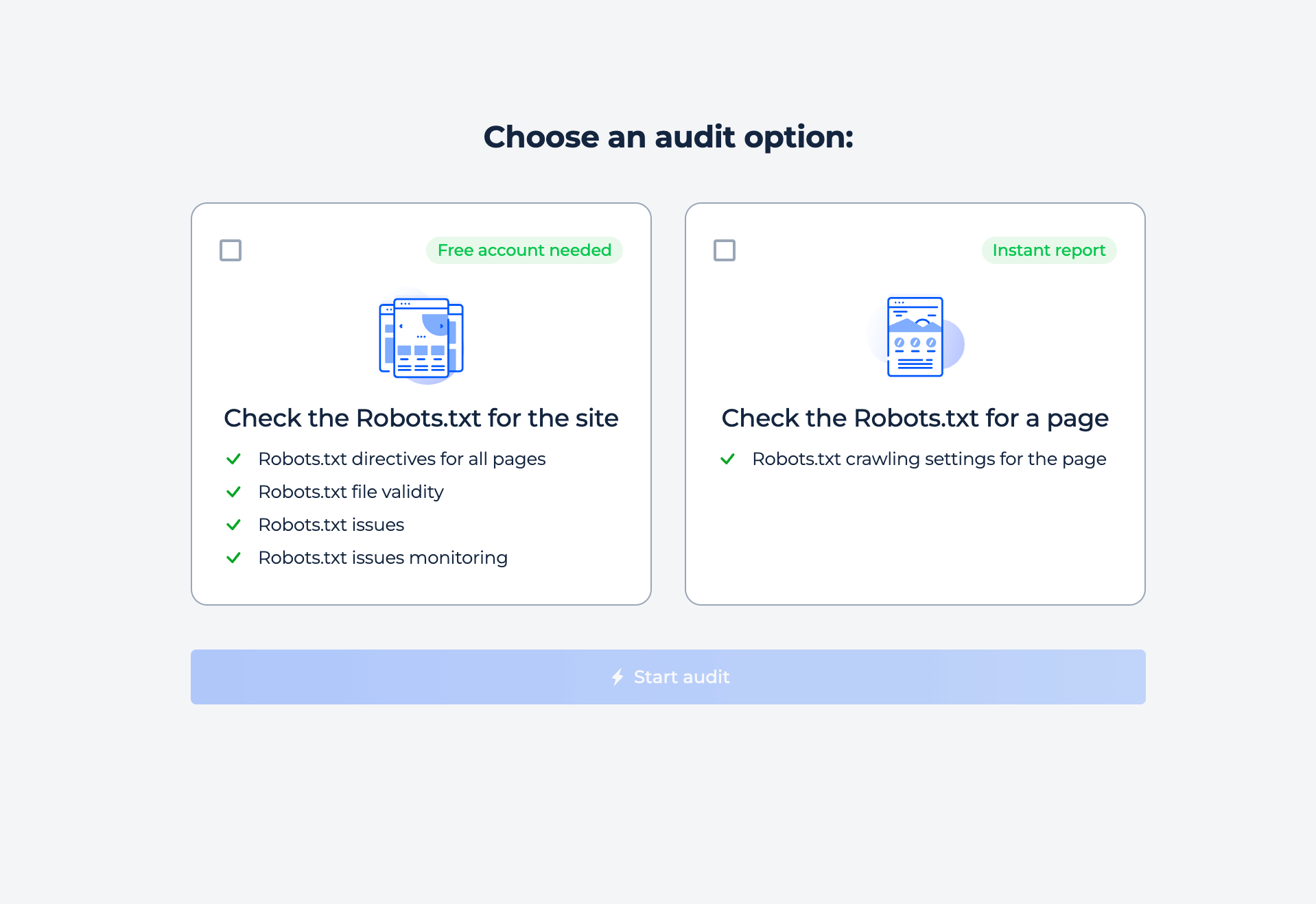
La herramienta ofrece dos tipos de análisis en línea: sitio completo y página individual. Simplemente seleccione la opción que le interese e inicie el análisis.
Prueba del archivo Robots.txt del sitio
Para comprobar la configuración del robot de su sitio y descubrir cualquier problema de indexación, simplemente seleccione la opción de inspección del sitio. En unos minutos, recibirá un informe completo.
Paso 1: Elija la verificación del sitio
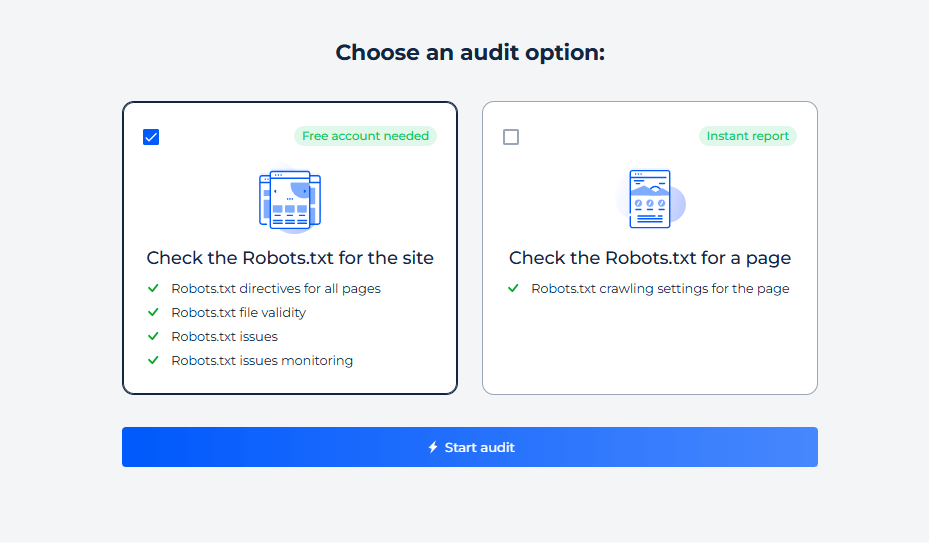
Paso 2: Obtenga los resultados
El analizador Robots.txt evalúa la configuración del archivo de directivas del servidor y le brinda datos valiosos sobre cómo las directivas de su sitio web influyen en la indexación de los motores de búsqueda. El informe incluye la identificación de páginas bloqueadas para el rastreo, directivas específicas como “noindex” y “nofollow” y cualquier retraso de rastreo establecido para los robots de los motores de búsqueda. Esto ayuda a garantizar que el archivo de política de rastreo del sitio web facilite la visibilidad óptima del sitio web y la accesibilidad de los motores de búsqueda.
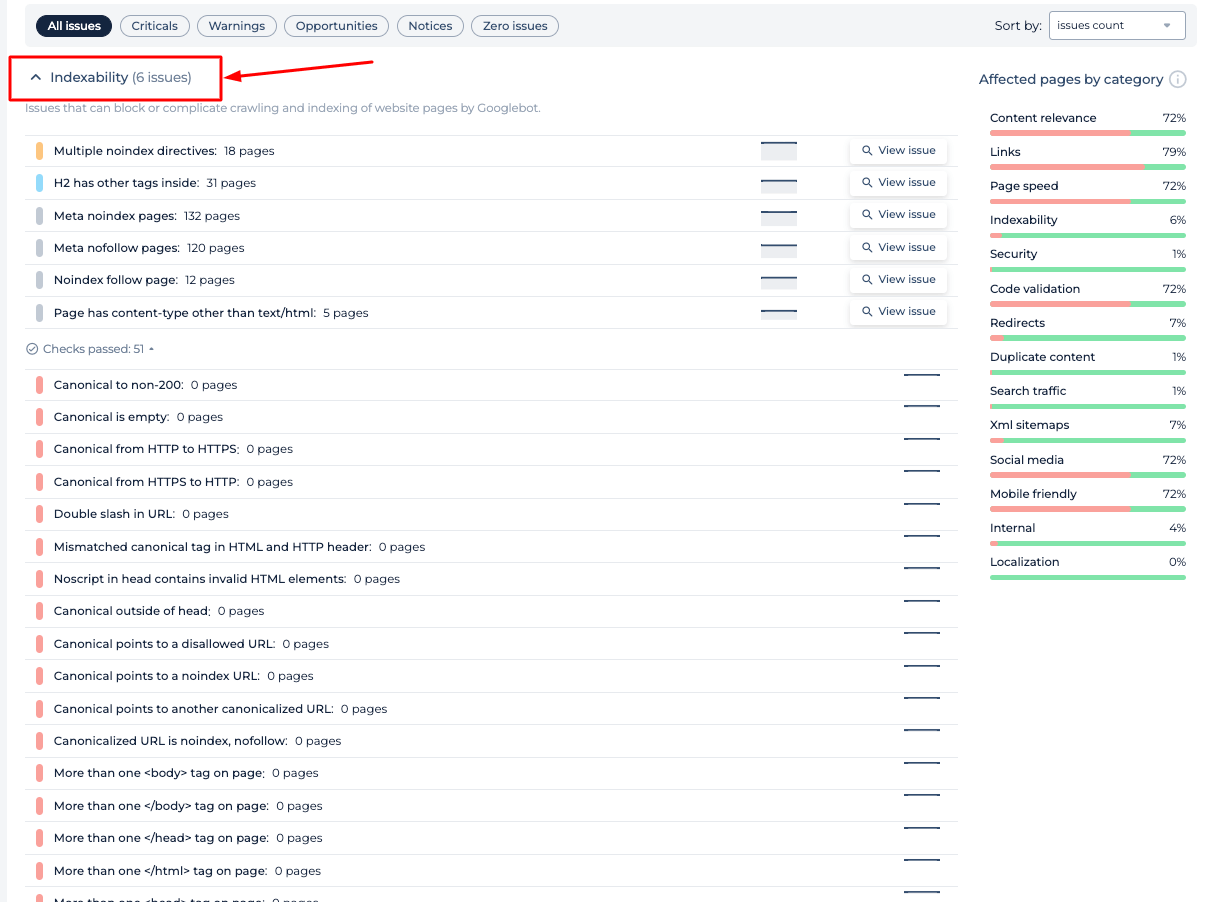
Funciones adicionales
El verificador Robots.txt ofrece un análisis integral del estado de SEO de un sitio web. Identifica problemas críticos, advertencias, oportunidades de mejora y avisos generales. Se proporcionan información detallada sobre la relevancia del contenido, la integridad de los enlaces, la velocidad de la página y la indexabilidad. La auditoría clasifica las páginas afectadas, lo que permite a los usuarios priorizar las optimizaciones para lograr una mejor visibilidad en los motores de búsqueda. Esta función complementa al verificador de robots.txt al garantizar que también se aborden elementos de SEO más amplios.
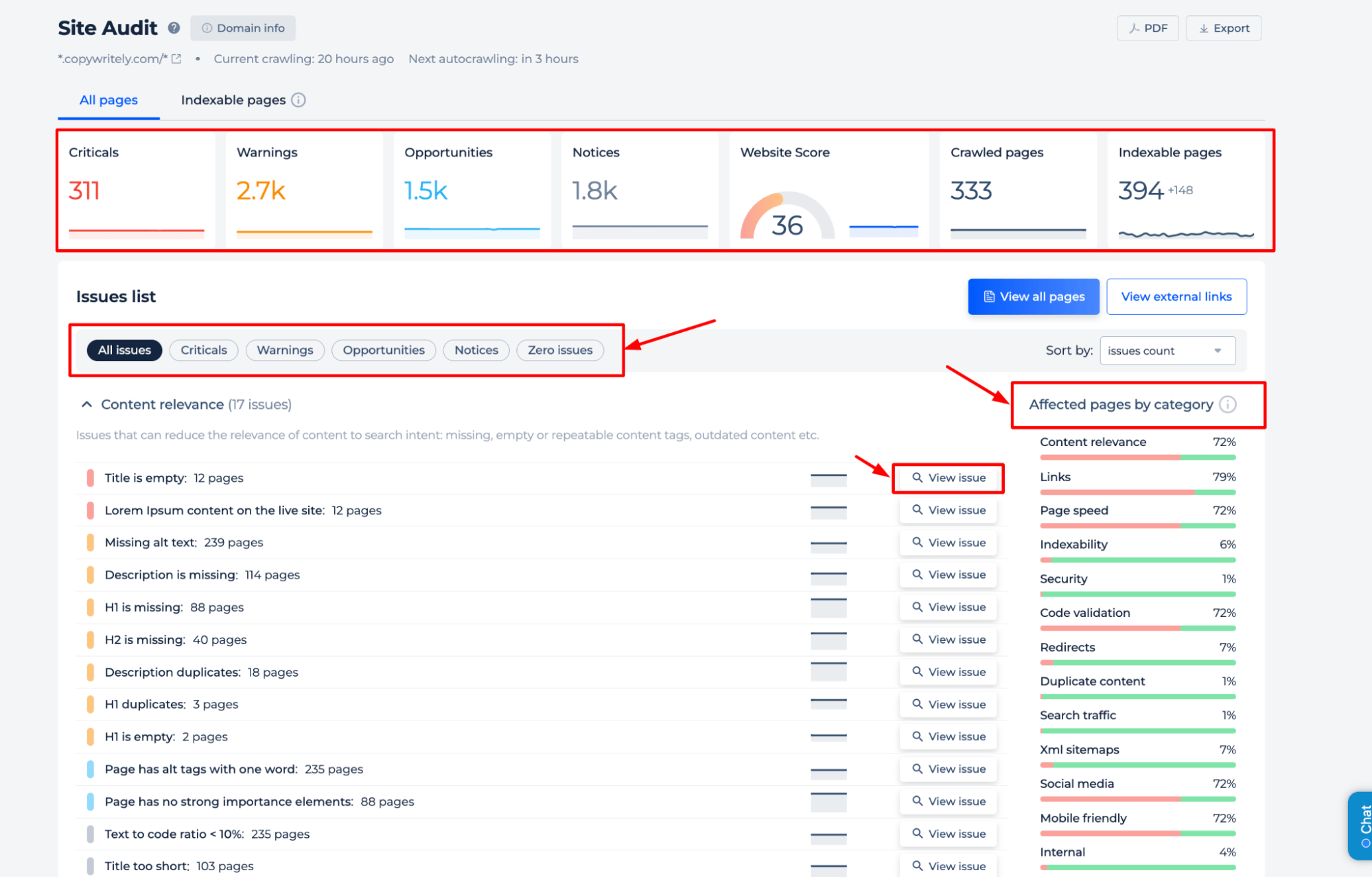
Prueba de Robots.txt para una página específica
Paso 1: Inicia una comprobación para una página específica
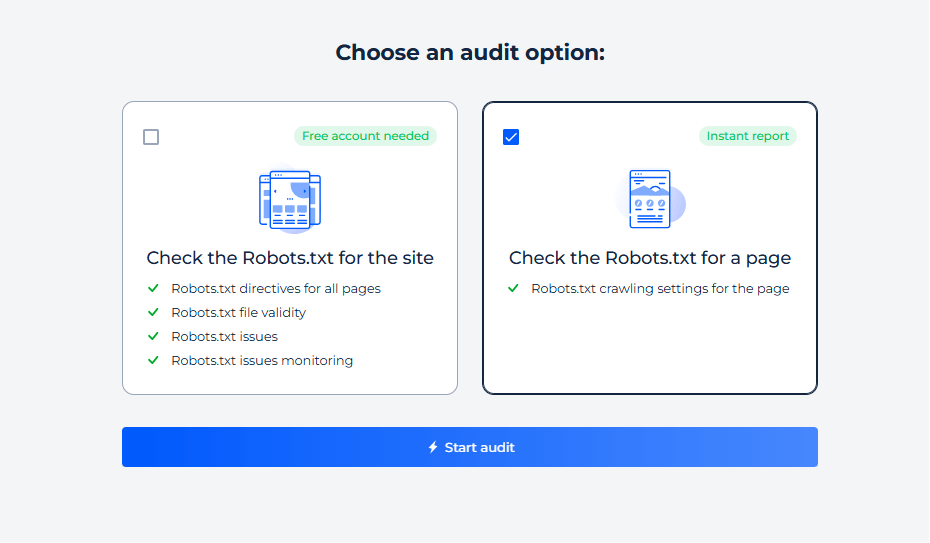
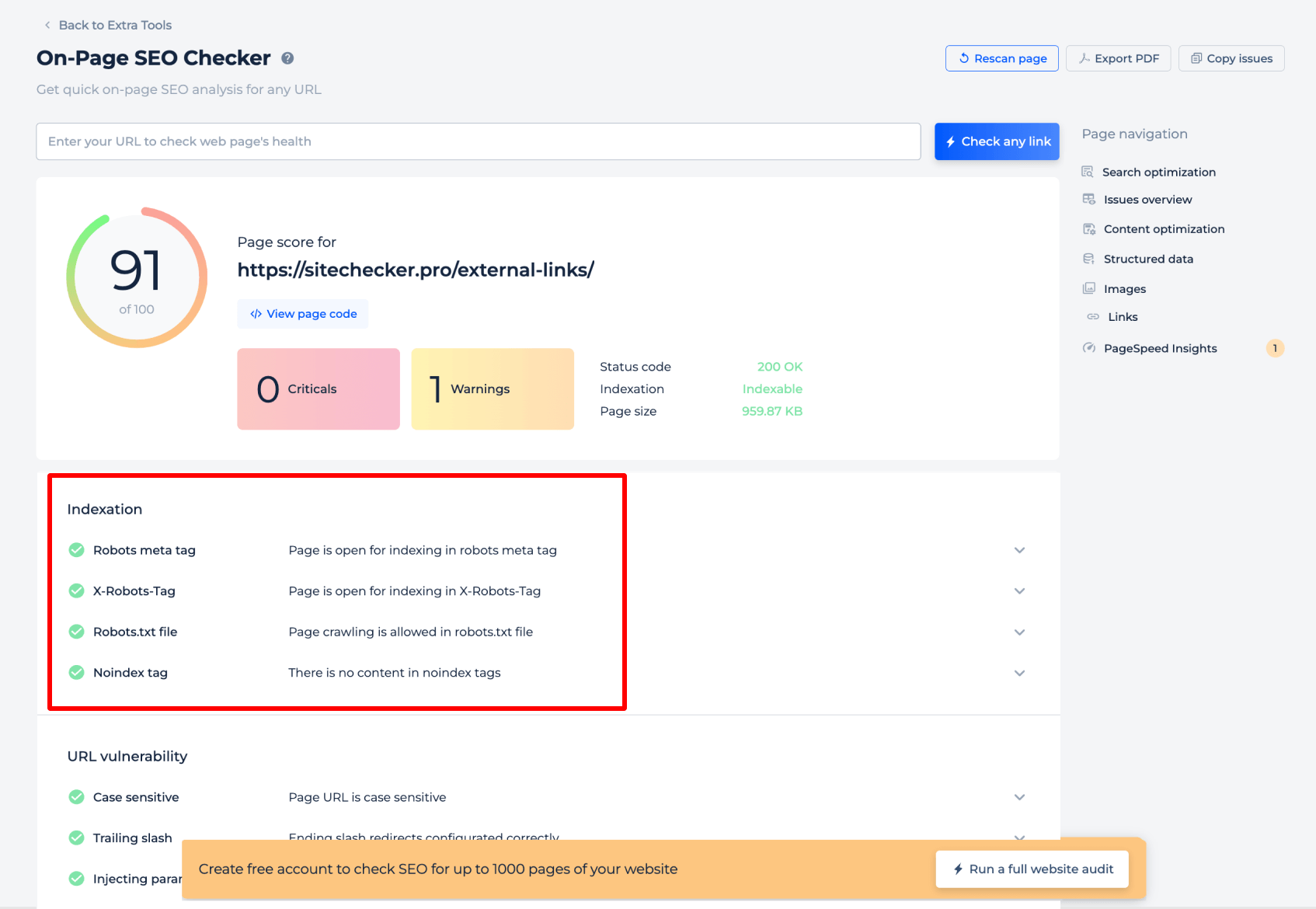
Paso 2: Obtén los resultados
El comprobador de Robots.txt para una página específica proporciona información fundamental sobre cómo los motores de búsqueda interpretan las directivas de robots.txt para esa página. Analiza la etiqueta meta robots y la etiqueta X-Robots-Tag para confirmar si la página está abierta para indexación. Además, verifica si el archivo de política de rastreo del sitio web permite el rastreo y comprueba la presencia de etiquetas “noindex” que podrían impedir la indexación. Esta evaluación específica garantiza que cada página esté configurada correctamente para que los robots de los motores de búsqueda puedan acceder a ella.
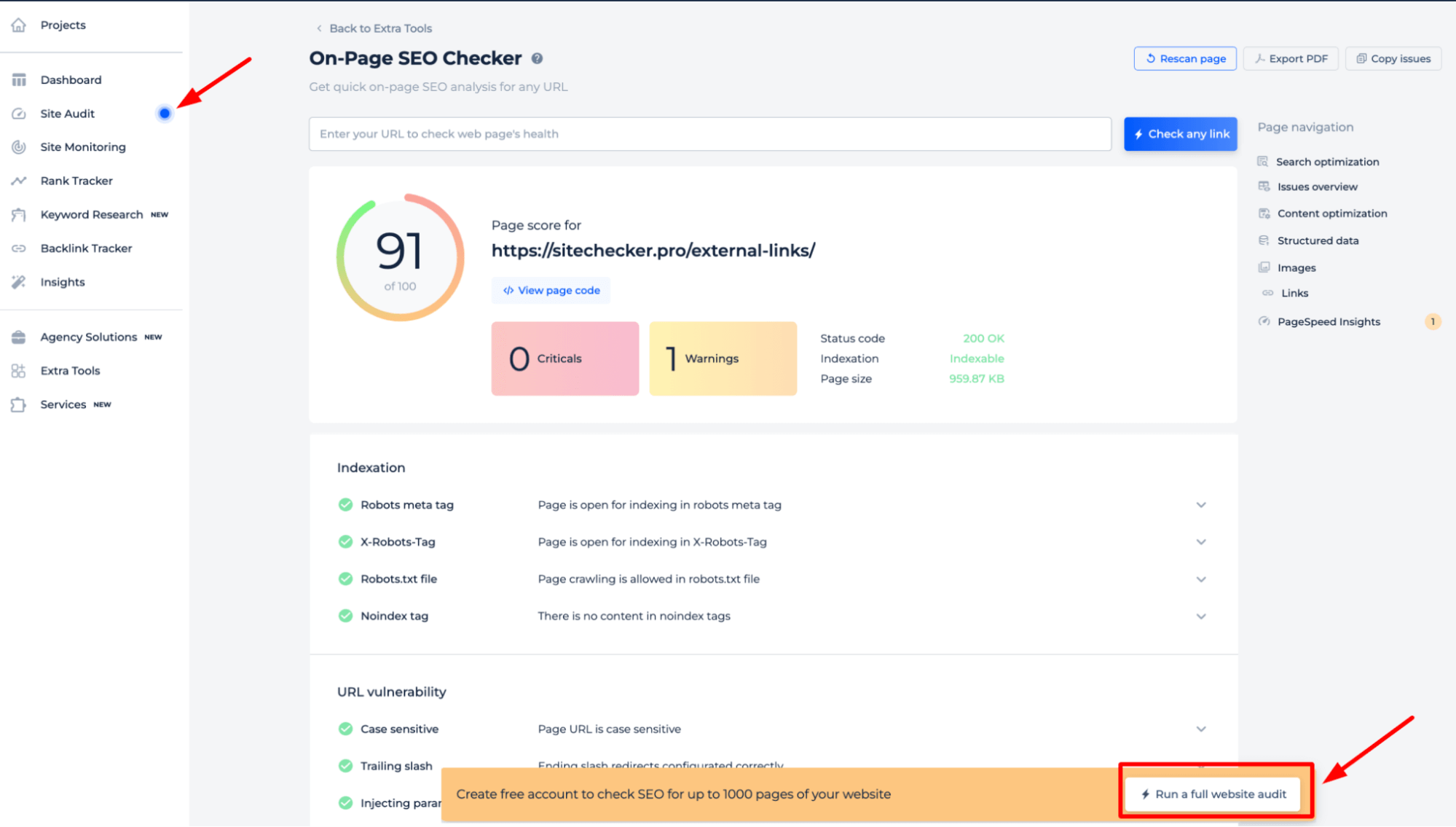
Para comprender en profundidad las directivas robots.txt de su sitio, es mejor realizar una auditoría completa del sitio web. Esto descubrirá cualquier problema de indexación en todo el sitio. Para comenzar la auditoría, simplemente haga clic en el banner “Iniciar auditoría completa del sitio web”. Se puede acceder a una versión de demostración de la herramienta a través de la sección Auditoría del sitio, lo que le permite probar sus capacidades.
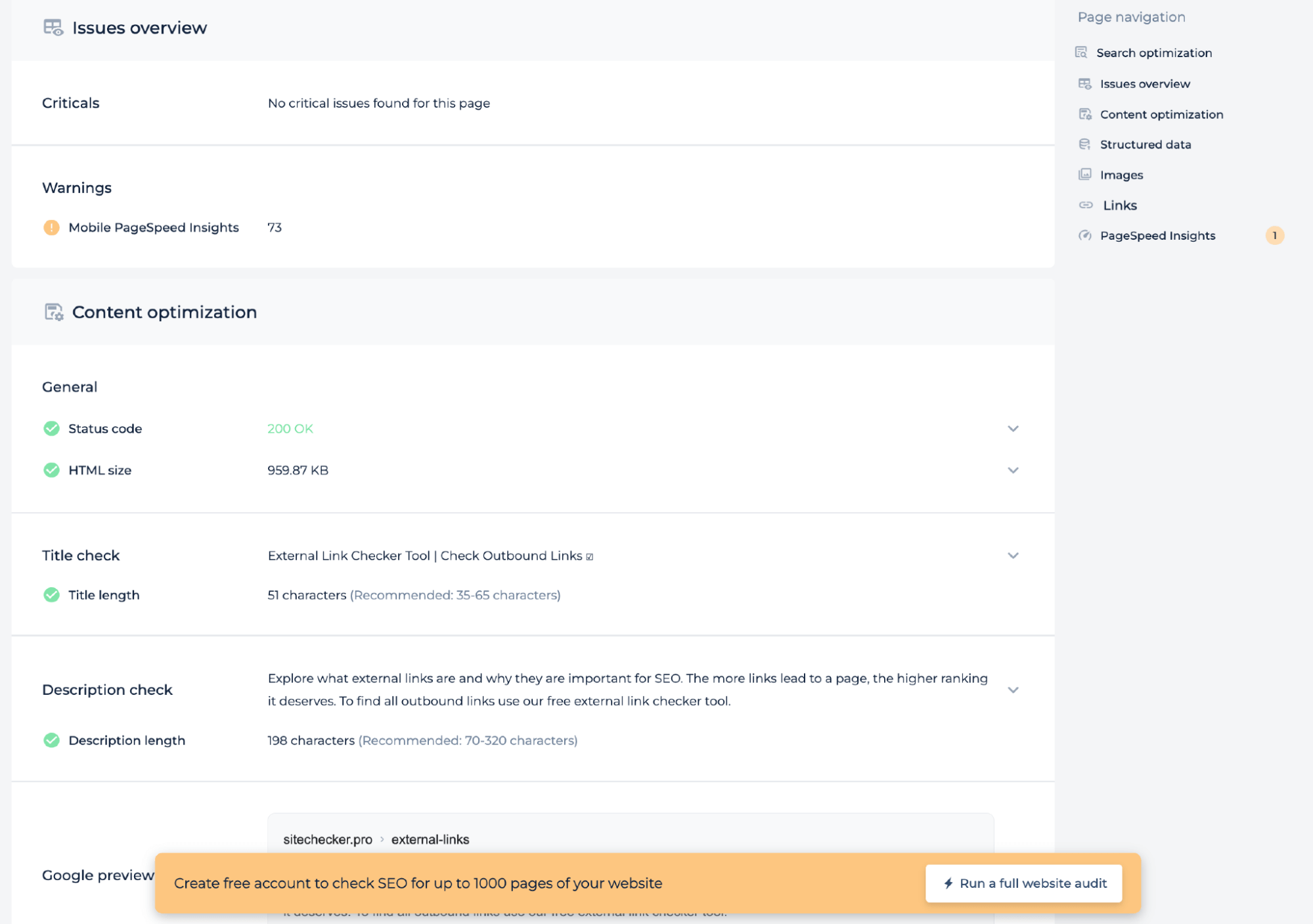
Funciones adicionales
Además de probar el archivo de directivas del servidor para una página específica, la auditoría técnica proporciona información sobre el estado de la página, como la puntuación de PageSpeed para dispositivos móviles, el código de estado y el tamaño del HTML. Comprueba si la longitud del título y la descripción cumple con los estándares recomendados y ofrece una vista previa de Google para garantizar que la página esté optimizada para los motores de búsqueda. Este análisis ayuda a mejorar el SEO técnico de la página.
Idea final
El comprobador de robots.txt es una herramienta de diagnóstico de SEO sólida que garantiza que el archivo de directivas del servidor de un sitio web esté dirigiendo correctamente a los robots de los motores de búsqueda. Ofrece análisis tanto de sitios completos como de páginas específicas, lo que revela cualquier barrera de indexación. Los usuarios se benefician de una interfaz fácil de usar, un amplio conjunto de herramientas de SEO y un panel de control unificado para el monitoreo. Las capacidades de auditoría integrales de la herramienta permiten la identificación de una amplia gama de problemas técnicos de SEO, incluida la optimización de contenido y las métricas de salud de la página, lo que garantiza que cada página esté preparada para el descubrimiento y la clasificación de los motores de búsqueda.







