


¿Qué es un comprobador de sitemaps?
XML Sitemap Finder es una herramienta para comprobar si un sitio tiene un mapa XML.
Puedes utilizar Google Sitemap Checker para comprobar si tu sitio web tiene un mapa XML del sitio web y para identificar cualquiera de sus errores. Si la herramienta encuentra algún error, le indicará cómo solucionarlo.
El Comprobador de Sitemap XML puede ayudarle en varias áreas clave:
- Verifica la presencia de un archivo XML en su sitio.
- Detecta cualquier problema dentro del archivo xml del mapa de tu sitio web.
- Mejora la eficiencia con la que los motores de búsqueda indexan su sitio.
Características principales de Sitemap Tester
Dashboard unificado. Un panel de control unificado proporciona una única vista de los datos técnicos de SEO, lo que facilita el seguimiento y la gestión de su rendimiento.
Interfaz fácil de usar. La interfaz fácil de usar hace que sea fácil de usar Sitechecker, incluso si usted no es un experto técnico.
Completo conjunto de herramientas SEO. The Sitemap Lookup Tool forma parte de un completo conjunto de herramientas SEO que pueden ayudarle a mejorar el posicionamiento de su sitio web en las páginas de resultados de los motores de búsqueda (SERPs).
Cómo utilizar el buscador de sitemaps XML
Afortunadamente, no hay necesidad de comprobar manualmente el código de su sitio web para saber si tiene el archivo que enumera las páginas esenciales de un sitio web. Con la ayuda de Sitemap Detector, puede buscar cualquier sitio para obtener esta información.
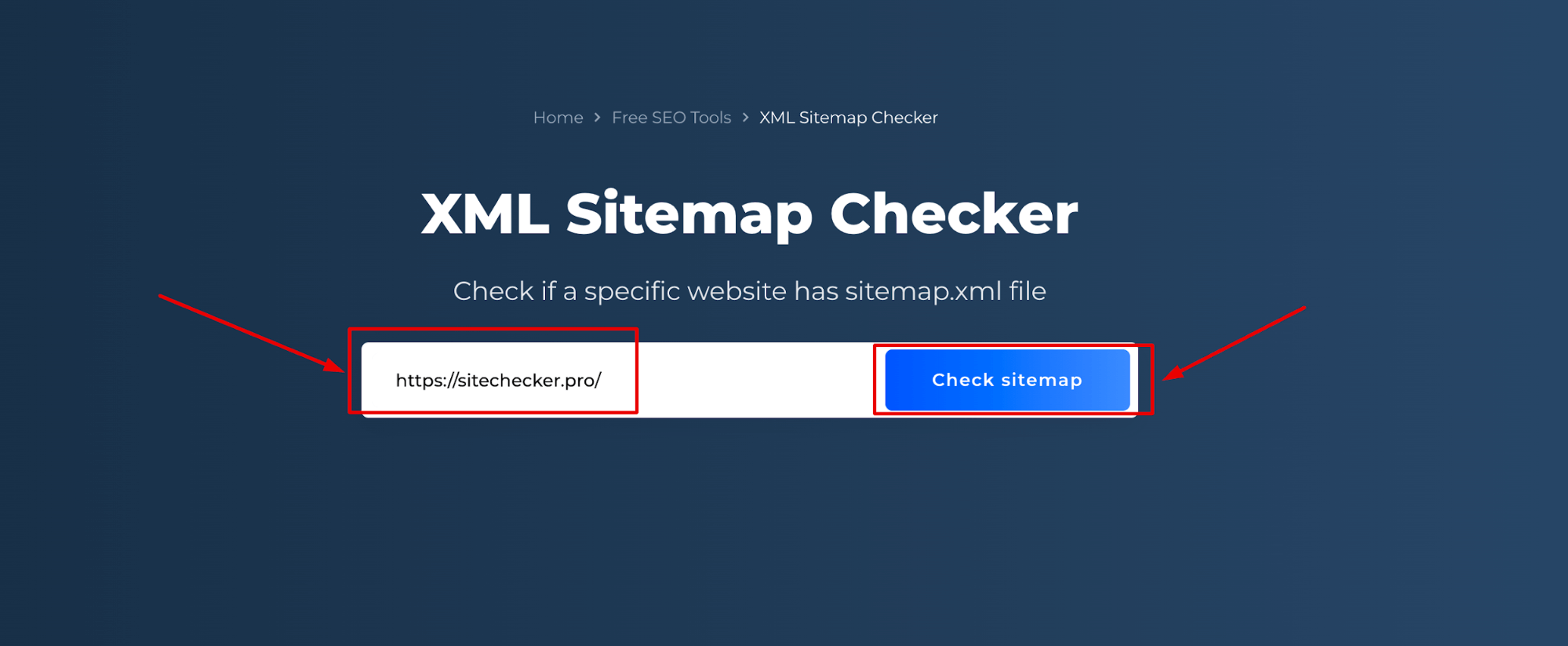
Paso 1: Introduzca su nombre de dominio
El primer paso es introducir la URL de tu sitio web:
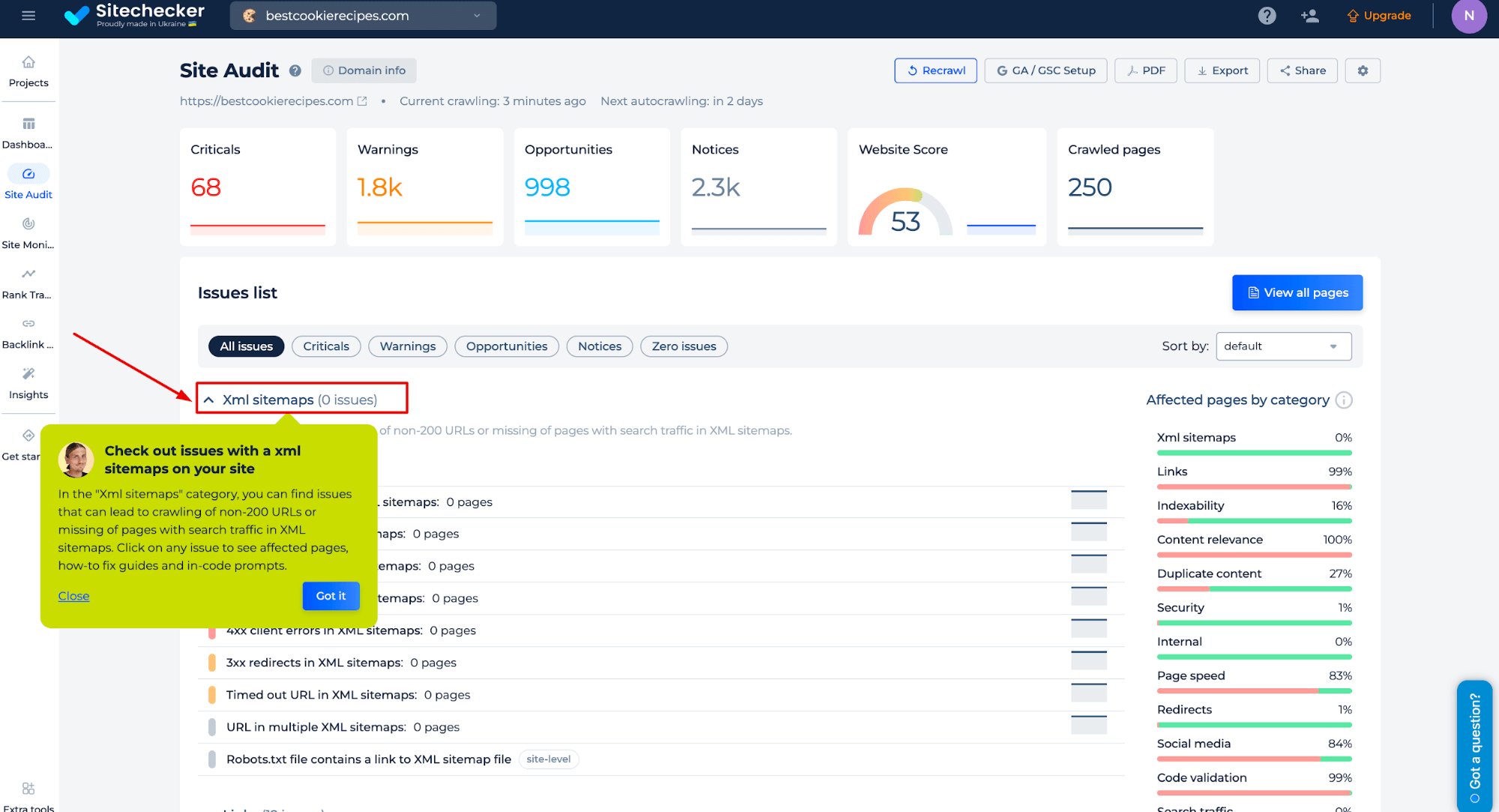
Paso 2: Interpretación de los resultados del comprobador de sitechecker
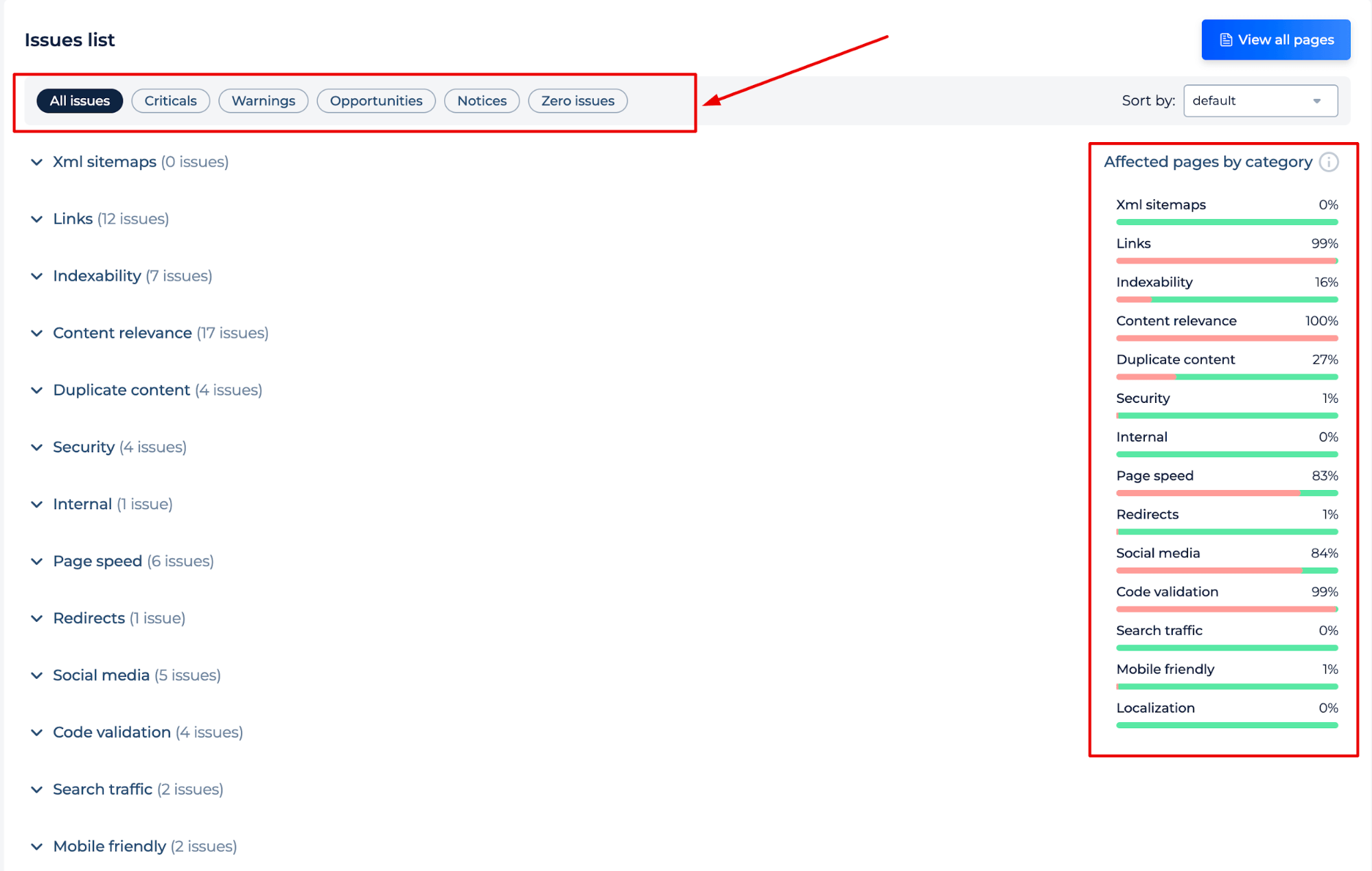
El análisis que realizas genera una auditoría del sitio para el dominio que introduzcas. En la categoría “Mapas de sitio XML”, puede encontrar problemas que pueden provocar el rastreo de URL no 200 o la ausencia de páginas con tráfico de búsqueda en los mapas XML. Haz clic en cualquier problema para ver las páginas afectadas, las guías de solución y las indicaciones en el código.
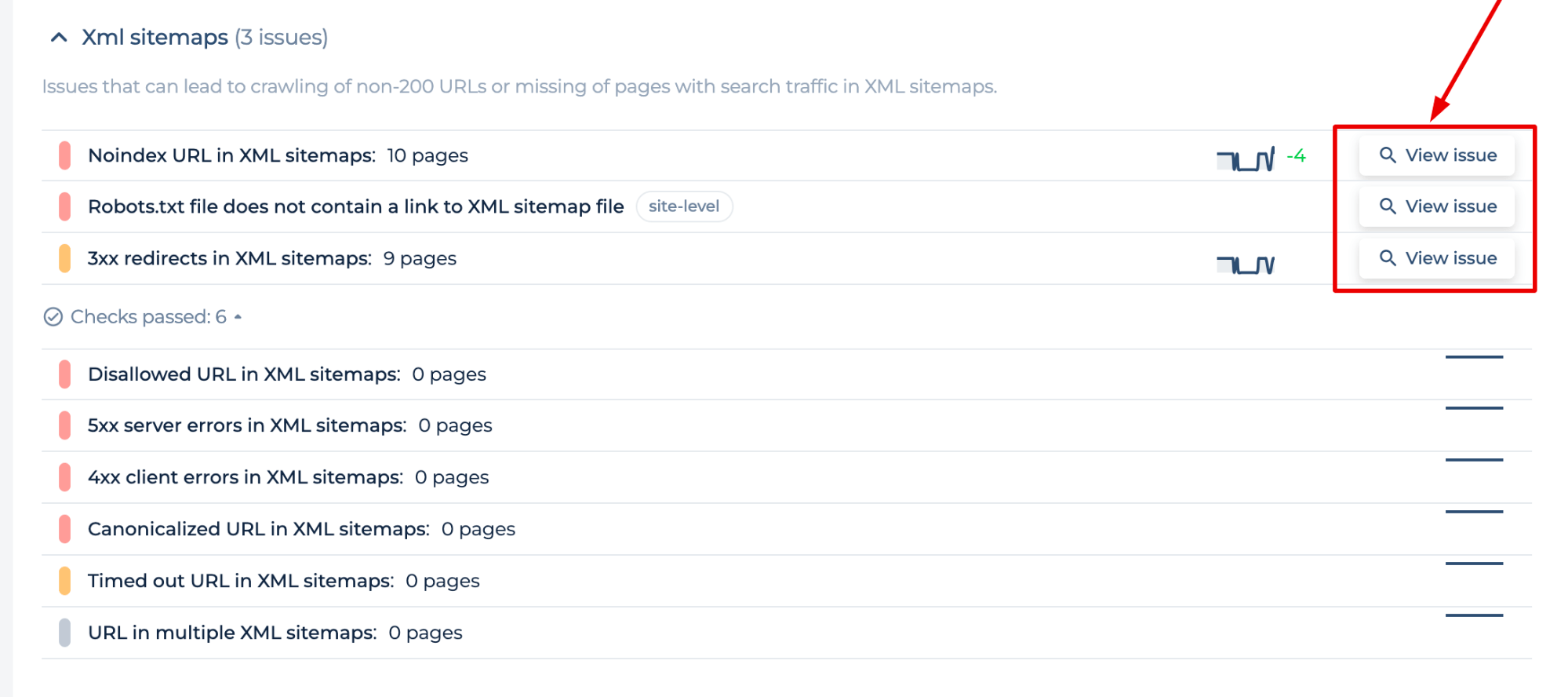
El comprobador de sitemap le permite identificar errores de sitemap y obtener instrucciones sobre cómo solucionarlos para reducir el efecto de los errores de sitemap en su indexación:
- URL sin código de estado 2xx en el mapa del sitio (3xx redirects, 5xx errores de servidor, 4xx errores)
- Red no indexada y URL no permitida
- Archivo robots.txt sin enlace a mapa del sitio XML, URL en varios XML, Archivo sitemap.xml demasiado grande, etc.
- Demasiado grande, etc.
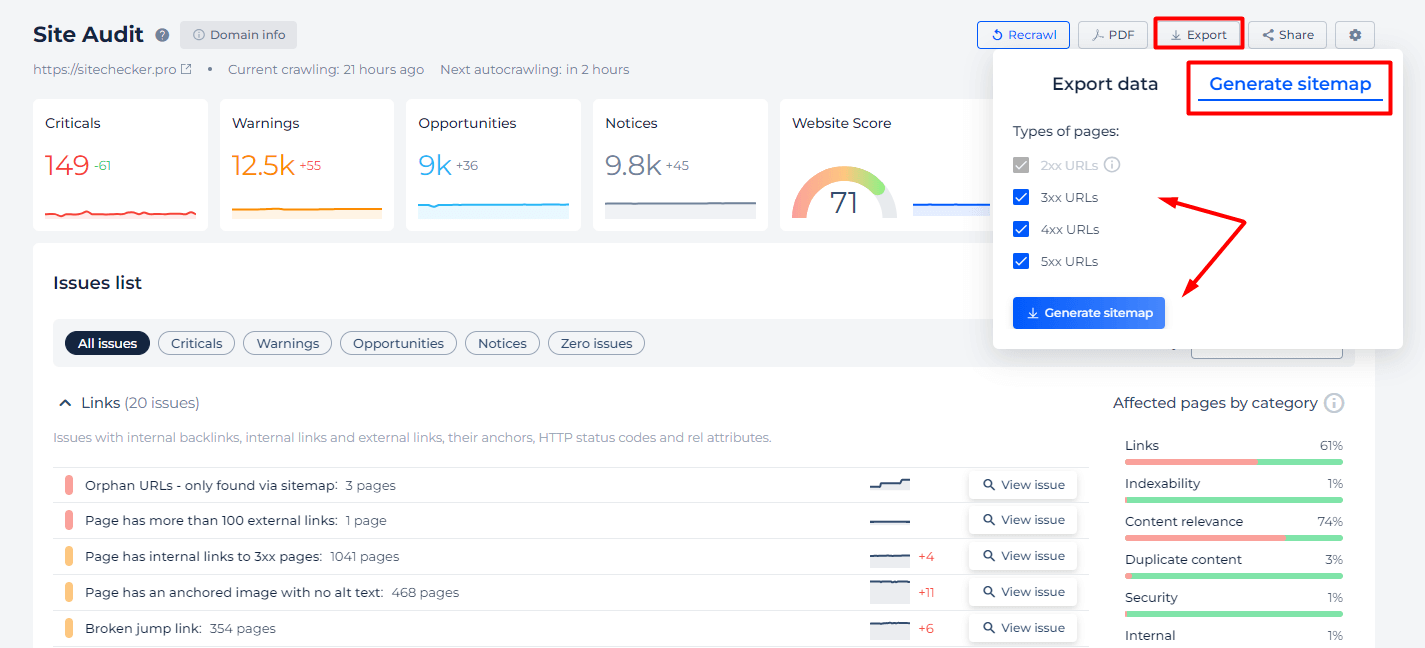
Además, ofrecemos funciones específicas en caso de que no esté seguro de si todas las páginas están incluidas en su sitemap, o si simplemente desea utilizar nuestra herramienta como un validador de sitemap XML. Utilice las pestañas “Exportar” y “Generar mapa del sitio” para seleccionar los tipos de URL por código de estado que deben incluirse en su mapa.
Características adicionales de XML sitemap checker
Después de rastrear el sitio, también recibirá un completo informe de auditoría del sitio, en el que se destacan los posibles problemas y se proporcionan instrucciones sobre cómo solucionarlos. El informe se clasifica por tipo o categoría de problema, lo que le permite abordar eficazmente los problemas más cruciales para el éxito de su sitio.
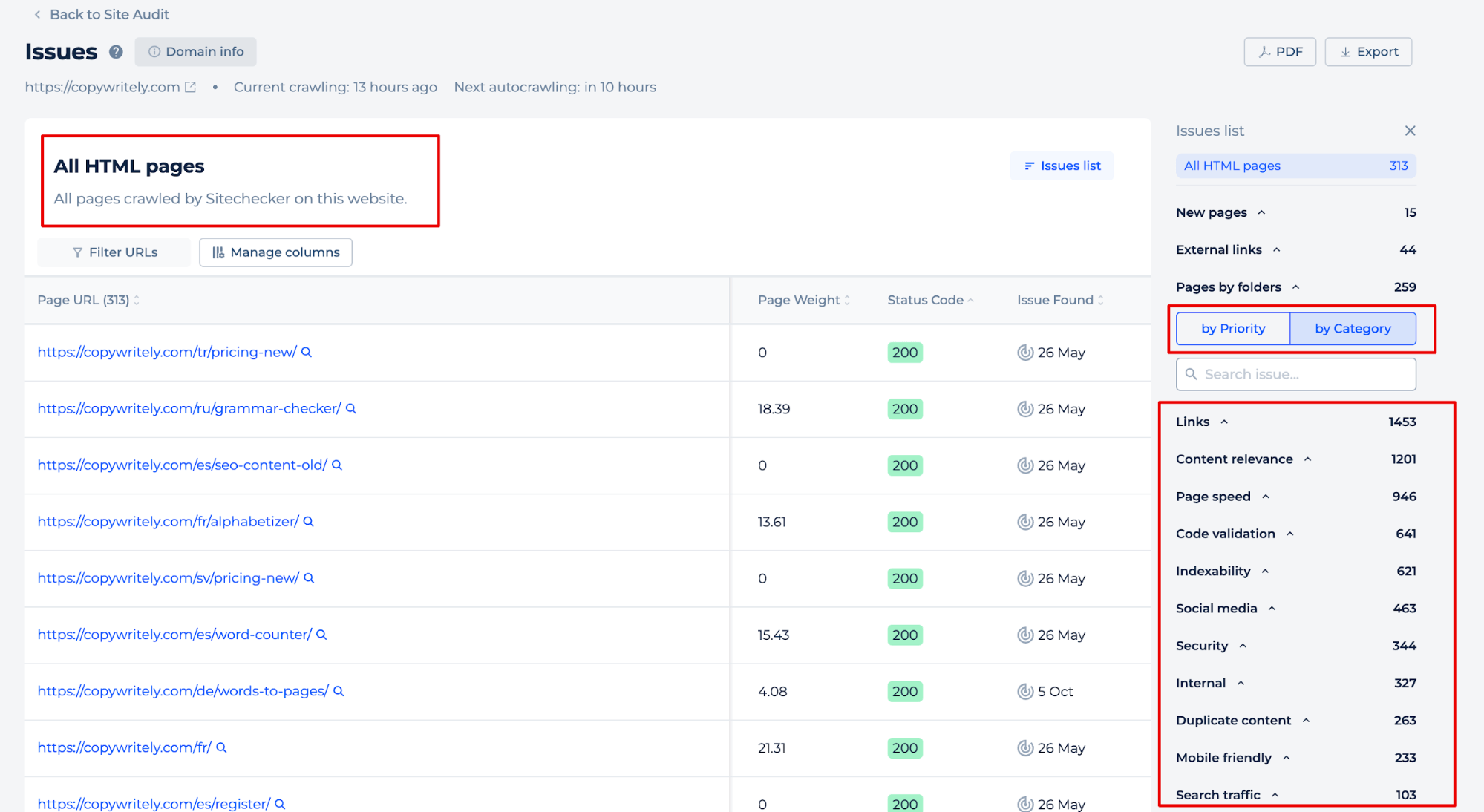
Si hace clic en el botón “Ver todas las páginas”, podrá identificar problemas en páginas individuales. Ordene los problemas por prioridades o categorías o añada manualmente datos a las páginas que le interesen.
Idea Final
Website Sitemap Checker es una herramienta diseñada para asegurar que un sitio tiene un archivo XML, identificar cualquier error presente, y ayudar a mejorar la eficiencia de indexación del motor de búsqueda del sitio. Ofrece una interfaz fácil de usar dentro de un panel de control unificado para facilitar la gestión SEO, como parte de un conjunto completo de herramientas SEO. La herramienta simplifica el proceso de comprobación de un mapa del sitio introduciendo un nombre de dominio y analizando los resultados, que incluyen un completo informe de auditoría con instrucciones detalladas para solucionar los problemas identificados. Esto ayuda a mantener un sitio bien estructurado y optimizado para SEO.








