



What is Google Index?
The Google Index is a vast database stored in Google’s servers where the search engine keeps a copy of all the web pages that it has deemed worthy of inclusion after its crawling process. When users search on Google, the search engine retrieves relevant results from this listing rather than searching the entire web in real-time.
The links in this index are the ones that have been discovered by Googlebot, Google’s web crawler, and have been analyzed and deemed fit to appear in search results based on various factors such as content quality, relevance, and site structure.
How Google Crawling and indexing work
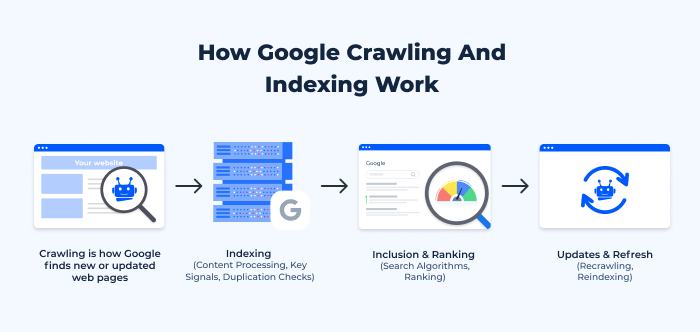
- Crawling. Crawling is the process by which Google discovers new or updated web pages.
- Googlebot. This is Google’s web crawler, a piece of software designed to explore the web. It fetches web pages and follows the links on those pages to find new URLs. To ensure that Googlebot can navigate your site effectively, using a Googlebot Simulator allows you to see how Google’s crawler interacts with your pages. This tool helps identify any issues, such as broken links or blocked resources, that could hinder Googlebot’s ability to fully crawl and index your site.
- Starting Points. Googlebot begins its crawl from a list of known web addresses from past crawls and sitemaps provided by site owners.
- New Content Discovery. As Googlebot visits each page, it detects links on the page and adds them to its list of pages to visit next.
- Indexing. Once Googlebot crawls a page, the search engine then decides whether to add it to its index, which is a vast database stored across thousands of machines.
- Content Processing. Google analyzes the content of the page, catalogs images and videos embedded in the page, and determines the topics covered on the page.
- Key Signals. Beyond content, Google checks for key signals like freshness of content, region-specific relevance, and website quality to determine the value of the page.
- Duplication Checks. To avoid storing duplicate information, The search engine checks if the content already exists in its database.
- Inclusion & Ranking. Not all crawled pages get listed. But for those that do:
- Search Algorithms. When users enter a query, Google uses complex algorithms to pull relevant results from its index. These algorithms take into consideration hundreds of factors, including user-specific details like location and search history.
- Ranking. The relevance of the results to the search query determines their ranking. Factors influencing this include the quality and originality of content, the number of external links pointing to the page (backlinks), and many other on-page and off-page signals.
- Updates & Refresh. Google’s index is constantly updated and refreshed.
- Recrawling. Googlebot revisits web pages at variable frequencies. Important and frequently updated pages like news websites might be crawled several times a day, while other pages may be crawled less often.
- Reindexing. If changes are detected during a crawl, the search engine may reindex the page, updating its stored version in the database.
Check out this video from Google for a deeper dive into the process:
In addition, incorporating Defacement Monitoring ensures that any unauthorized changes or tampering with your site’s content are detected immediately. This adds an extra layer of protection, safeguarding your site’s integrity and preventing potential SEO setbacks caused by malicious activities.
Factors Influencing Indexing
Google’s indexing process involves analyzing a multitude of factors to determine the relevance, importance, and quality of a web page. While Google’s exact algorithms are proprietary and contain hundreds of ranking signals, the following are some well-known and impactful factors that influence whether and how a webpage is indexed:
| Content Quality | Relevance: The content must be pertinent to search queries and topics. Originality: Unique content is more likely to be listed than duplicated versions. Structure: Proper use of headers, paragraphs, and formatting makes content easier for Googlebot to interpret. |
| Website Structure | XML Sitemap: Submitting an XML sitemap via Google Search Console can help Google understand the structure of your website and prioritize pages for crawling. Robots.txt: This file can instruct Googlebot on which pages to avoid. However, wrongly configured robots.txt can prevent important pages from being crawled. Clean URL Structure: URLs that are descriptive and concise can assist Google in understanding the content of a page. |
| Technical SEO | Mobile-friendliness: With mobile-first indexing, Google primarily uses a page’s mobile content for listing. Page Speed: Faster-loading webpages can be listed more quickly and are favored in rankings. Secure and Accessible Website: A site that’s HTTPS and easily accessible to Googlebot is preferred. |
| Meta Tags | Meta Robots Tag: This can be used to instruct search engines if a page should be listed (index or noindex). Canonical Tag: Indicates the preferred version of a page if there are multiple pages with similar content. |
| Internal Linking | Pages that are important and have more internal links pointing to them may be crawled and indexed more frequently. |
| Backlinks | High-quality, relevant backlinks from authoritative sites can indicate to Google that a page is important and trustworthy, potentially influencing its listing. |
| Server Issues | If a website’s server is often down or slow when Google tries to crawl it, the site might be crawled less often. |
| Duplicate Content | Pages with substantially similar content can confuse search engines. Google might choose to list only one version, thinking the others are duplicates. |
| User Engagement | While more directly a ranking factor than an indexing factor, positive engagement signals (like low bounce rates) can indirectly influence the frequency and depth of site indexation. |
| Social Signals | Shares, likes, and mentions across social media platforms can increase a page’s visibility and might indirectly impact its indexing. |
| Penalties | If a site or page violates Google’s Webmaster Guidelines, it can be penalized, which can affect its listing status. |
| Freshness | Regularly updated content or new pages can trigger search engines to crawl and index your site more frequently. |
Understanding these factors and optimizing for them can significantly influence how and when a page is listed by the search engine. Regularly monitoring and analyzing a website’s performance using tools like Google Search Console and Website SEO Monitoring can provide insights into indexing status and any potential issues.
Checking if a Page is Indexed
This refers to the process of verifying whether a specific webpage or a set of pages from a website has been added to Google’s vast database. Once a webpage is in this database, it’s eligible to appear in Google’s search results.
There are multiple ways to check if a page is indexed, and the following are two common methods:
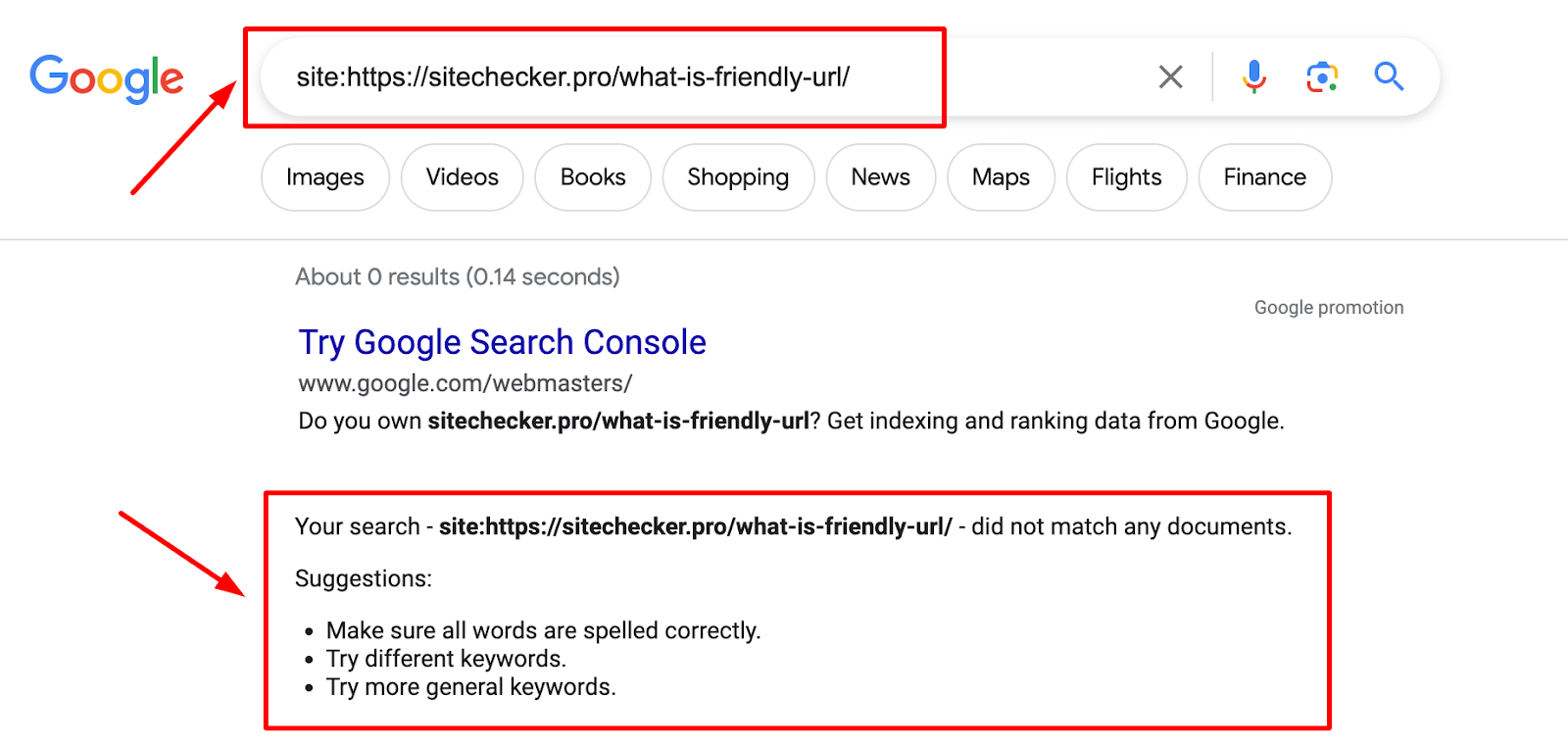
1. Using the “site:” search operator
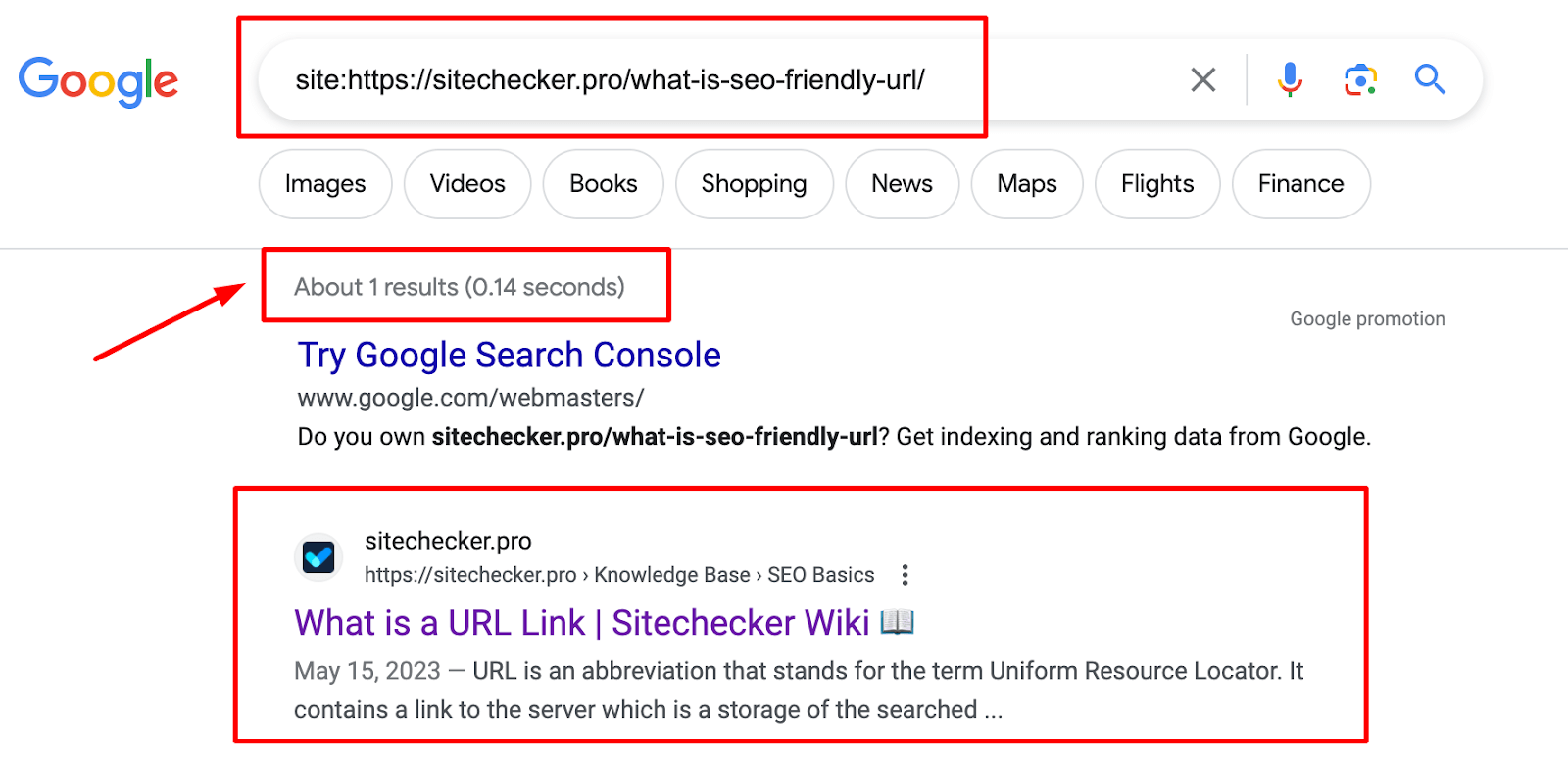
How it works: By entering site: followed by a specific URL or domain name into the search bar, you can see all the indexed pages from that particular website or the specific URL.
Google will display all the included webpages from the specified domain or the exact URL if it’s listed. If no results appear, it suggests that the domain or the specific page hasn’t been added to the database.
2. Google Search Console and its Index Coverage Report
Google Search Console (GSC) is a free tool offered by the search engine that allows webmasters and website owners to monitor and manage their site’s presence in Google’s search results. It provides a plethora of information, including indexing status, search traffic data, and issues affecting the site.
Within GSC, the Index Coverage issues report provides detailed information about which pages from your website have been added to their database, which haven’t, and why.
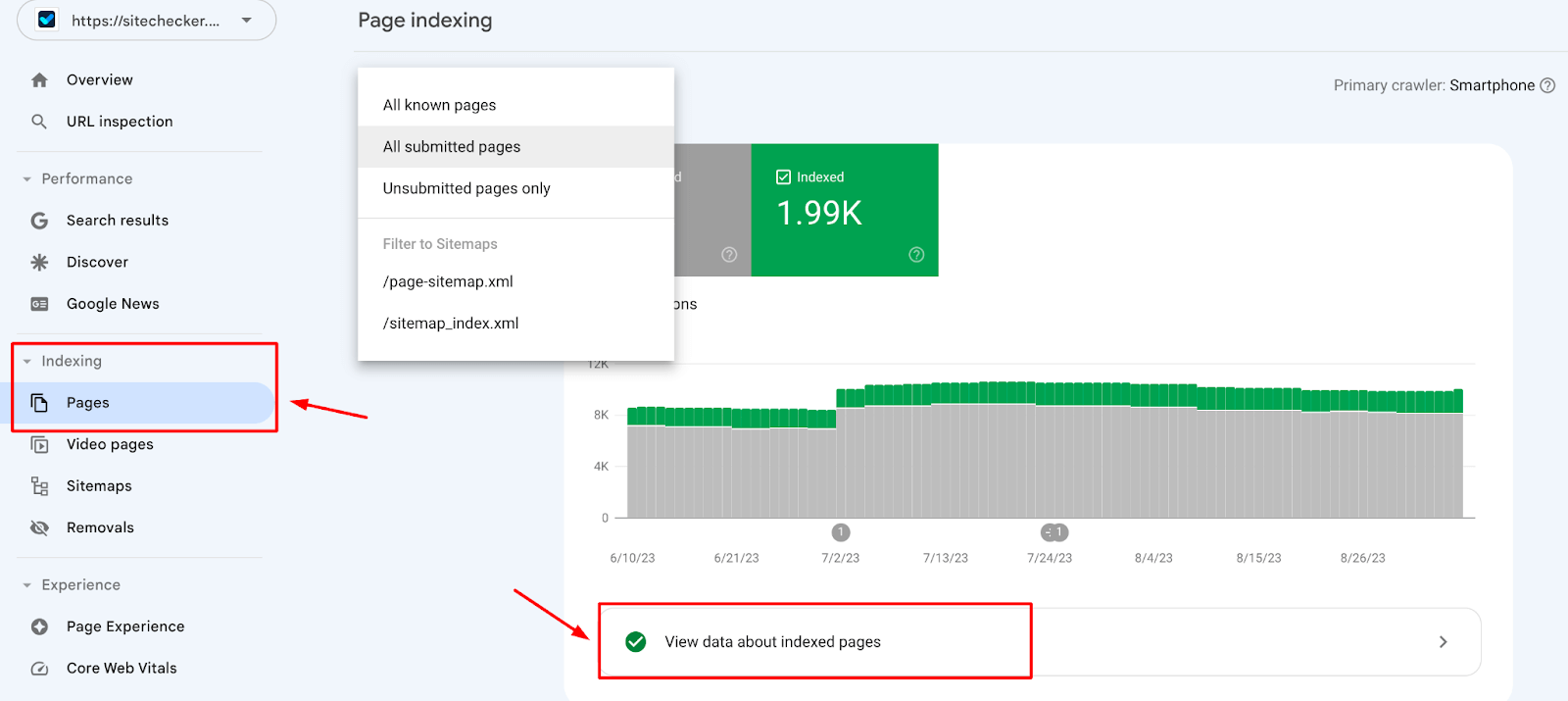
More about the Index Coverage report in the video by Google Search Central:
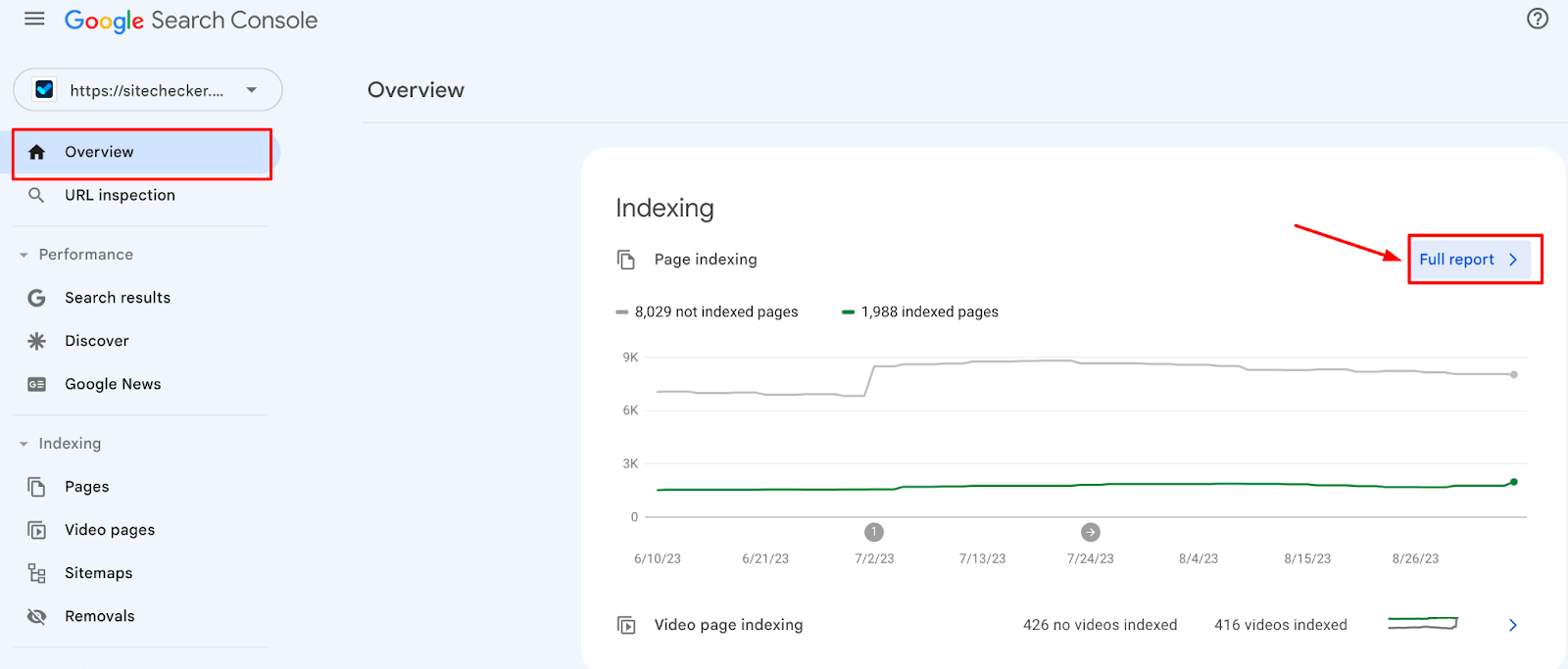
Features Index Coverage report:
- Error – Pages that the search engine tried to index but couldn’t, accompanied by the reasons for the error.
- Valid with warnings – Pages that are listed but have some issues that might affect their performance in search.
- Valid – Pages that are successfully indexed.
- Excluded – Pages that Google has not listed intentionally, along with explanations (e.g., because of directives in the robots.txt file or due to noindex tags).
By analyzing the Index Coverage report, webmasters can gain insights into the indexing status of their websites and address any issues that might be preventing pages from getting listed.
In summary, both the site: search operator and the Google Search Console’s Index Coverage report are valuable tools to verify if pages from a website have been successfully added by the search engine. While the former provides a quick snapshot, the latter offers more in-depth information and insights.
How to get Google to index my site or page
To ensure that the search engine indexes your site or webpage via GSC, you first need to verify your website within the console. Once verified, you gain access to a suite of tools and data catered to your website’s performance in Google Search.
Google Index Site
One of the primary steps is to submit your website’s sitemap within the ‘Sitemaps’ section of the console:
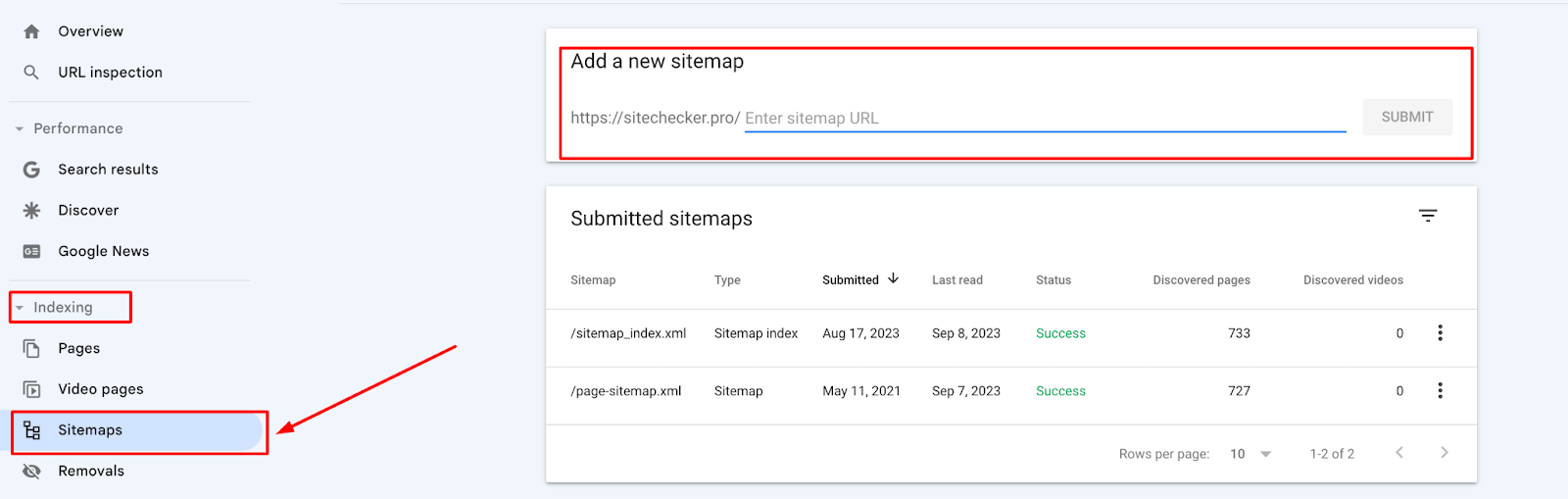
Google Index Page
Simply enter the URL of your sitemap, typically found at yourdomain.com/sitemap.xml. This guides the crawler through your website’s structure, ensuring all necessary pages are discovered. If you have specific pages in mind, you can directly submit their URLs for listing through the ‘URL inspection’ tool. After inputting the URL, an option for ‘Request Indexing’ becomes available.
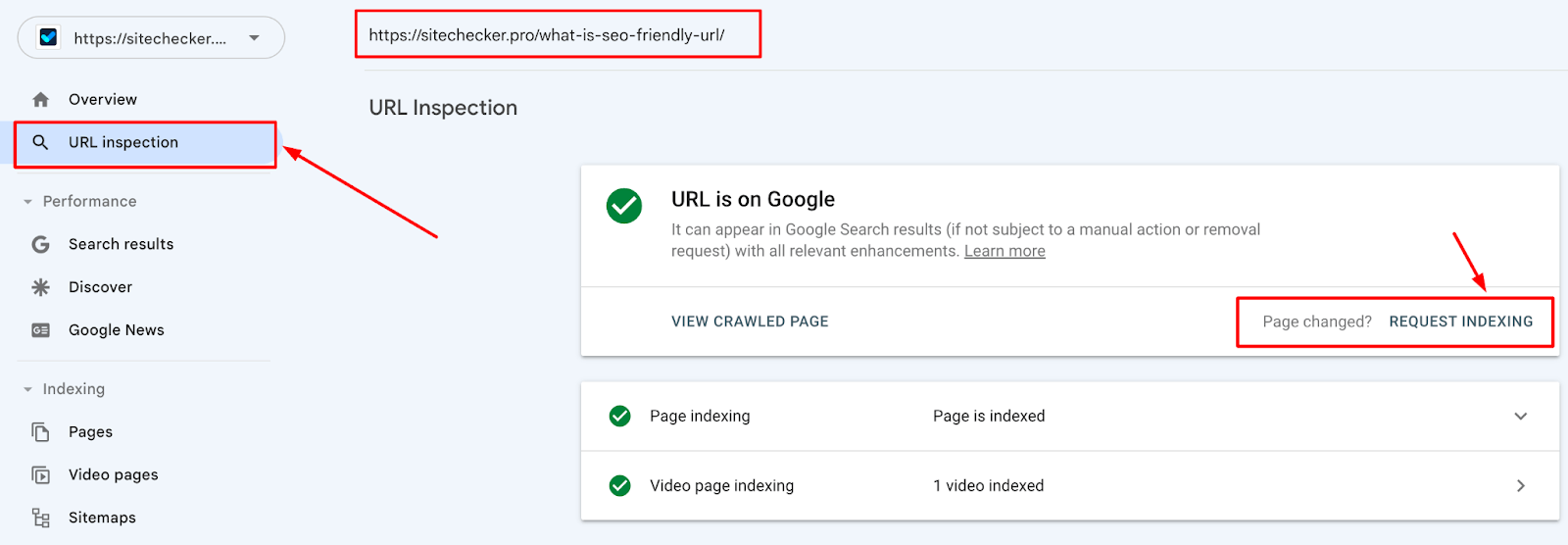
Also, using the URL Inspection tool, ensure none of your crucial pages carry a ‘NoIndex’ tag, which could prevent them from being added to the search engine’s database. While you can prompt the search engine to list, the final decision rests with its algorithms. Prioritizing quality content and adhering to Google’s guidelines will boost your site’s listing chances.
Time required for indexing a new page
Google’s indexing time for a new page varies. Well-established sites with regular updates and strong backlinks may see content indexed within hours, aided by tools like Google Search Console’s “Request Indexing”.
Newer or average sites typically wait days to weeks. However, sites lacking authority or with indexing issues might face prolonged delays or even non-indexation due to factors like crawl errors or duplicate content.
Why a Crawler Couldn’t Index the Webpages: De-indexing, NoIndex Tag, and Canonical Tag
Navigating the complexities of webpage listing, one might encounter obstacles. Here’s why a crawler might fail to index certain webpages:
De-indexing
De-indexing refers to the removal of a webpage or a set of them from a search engine’s database. When a page is de-indexed, it won’t appear in the search results, even though it still exists on the web.
NoIndex Tag
The NoIndex tag is a directive you can add to the HTML code of a webpage, instructing search engines not to include that page in their indices.
Site owners might prevent specific pages from being indexed to avoid search engine penalties for duplicate content. Additionally, to ensure privacy, pages containing sensitive data or those designed for internal use are often kept out of search results. Pages from development versions of the site, low-quality content, and internal search results are also typically excluded to maintain a site’s search engine reputation and clarity for users.
How does the “noindex” meta robots tag work?
The noindex directive can be added to a webpage using a meta robots tag in the page’s HTML header. When search engine crawlers see this tag, they acknowledge the instruction not to include that specific page in their index.
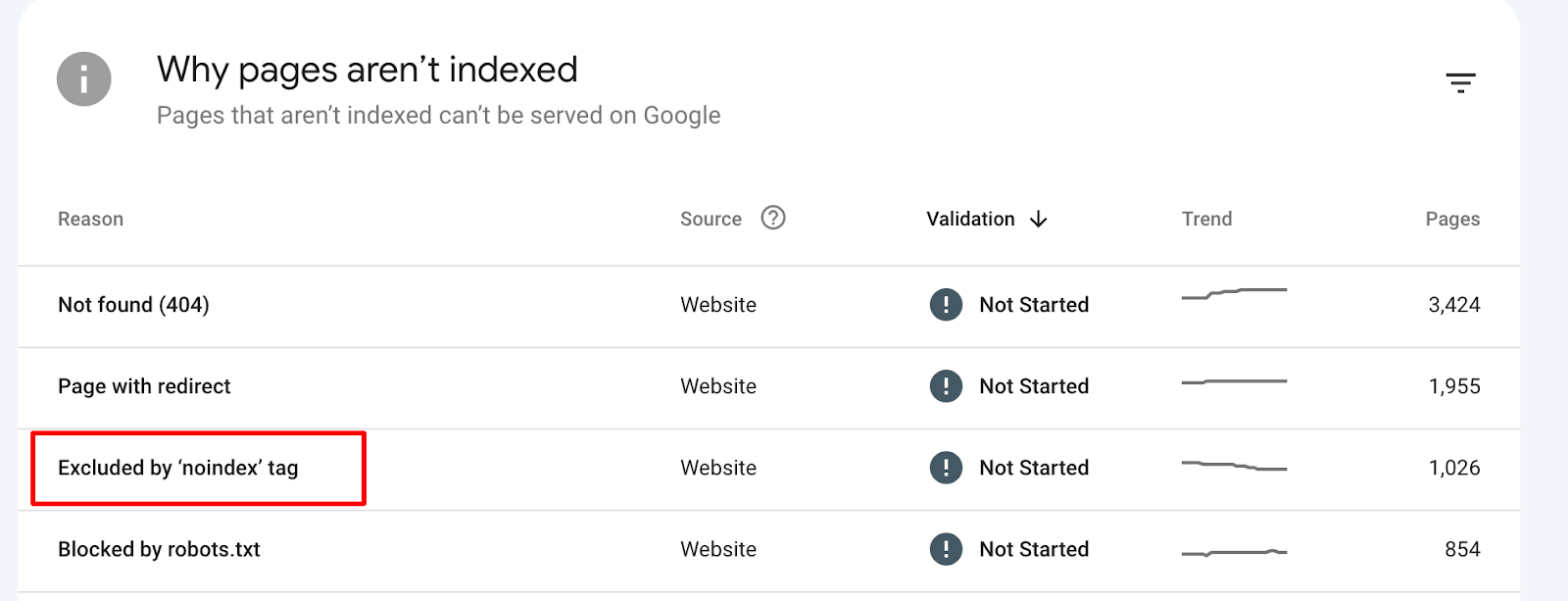
Here’s an example of what the tag might look like:
<meta name="robots" content="noindex">- Combining Directives. You can combine multiple directives in one tag. For example, to prevent both listing and following the links on that page, you’d use: <meta name=”robots” content=”noindex, nofollow”>.
- Specificity to Search Engines. If you want to target a directive to a specific search engine (like Google), you can replace “robots” with the name of the search engine, like <meta name=”googlebot” content=”noindex”>.
- Reindexing. If you’ve previously set a page to noindex and later want it to be included in the search results, you will need to remove the noindex directive and potentially request the page to be re-crawled through tools like Google Search Console.
The decision to de-index a page or to use the noindex tag is strategic, allowing site owners to curate what content appears in search engine results, ensuring the best representation of their website.
Canonical Tag
Another potential reason your page hasn’t been indexed is the presence of a canonical tag.
Canonical tags guide crawlers to the preferred version of a page, addressing problems from identical content spread across different URLs.
When a page features a canonical tag pointing elsewhere, Googlebot interprets a preferred version elsewhere, refraining from listing the tagged page, even in the absence of an alternative version.
To clarify this, you can use the Google Search Console’s “Pages” report. Navigate to the “Reasons for non-indexation” and select the “Alternative page with correct canonical tag” option.
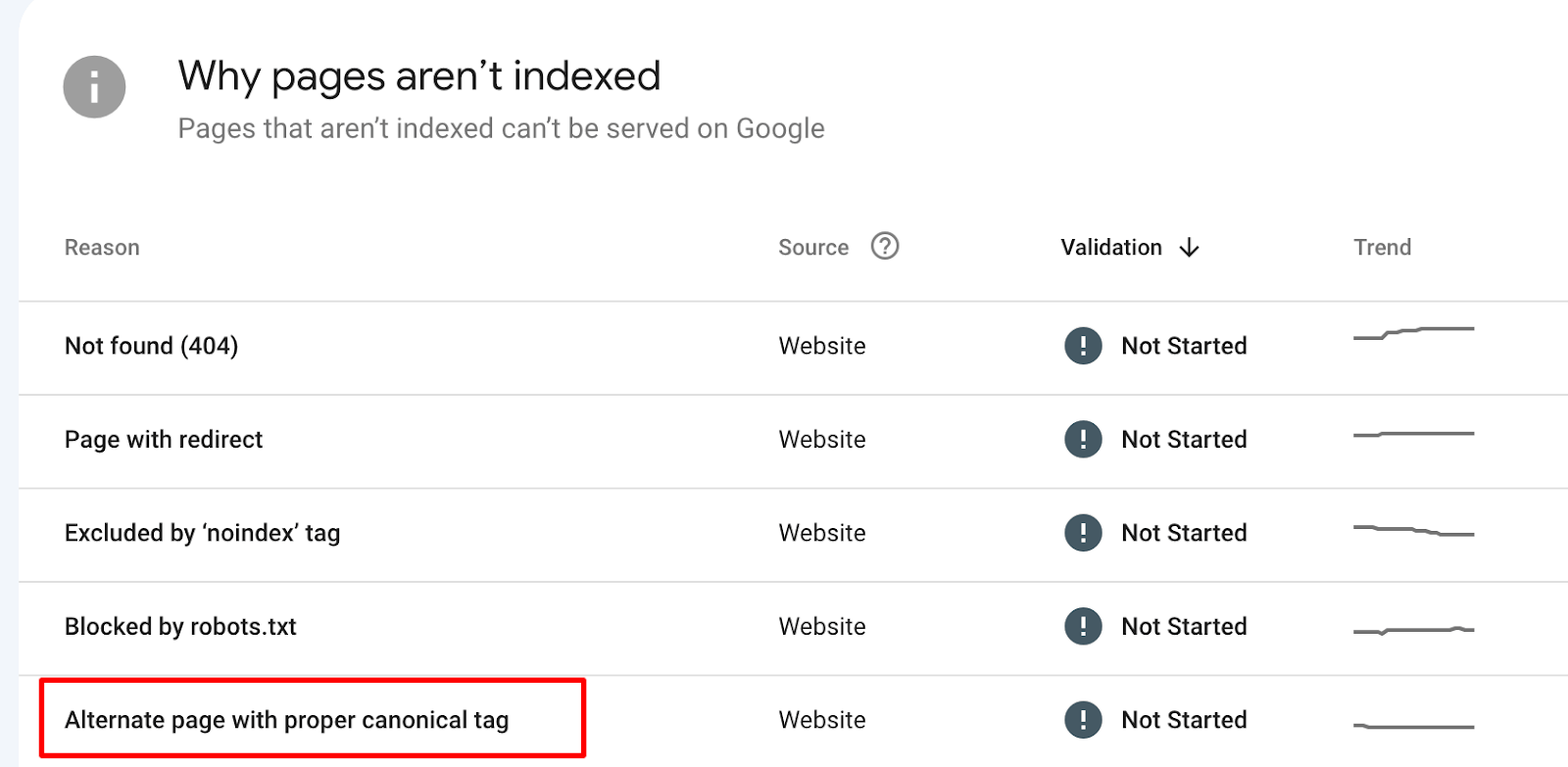
Common misconceptions about Google Index
Universal Google Indexing
The notion that Google indexes every single website is a misconception. Google’s indexing hinges on its ability to crawl a website. If your site lacks sufficient external links or contains technical barriers, it might not trigger Google’s crawl.
Permanent indexation
Some believe once a site gets indexed, it remains indefinitely. In reality, sites can be delisted if they become dormant or breach Google’s webmaster standards.
Manual Google submission
Submitting your site to Google doesn’t guarantee its indexation. Post-submission, the search engine must still crawl and evaluate the site before it’s listed in search results.
Sheer page volume
Simply having a large number of pages doesn’t ensure top ranks in search results. Google’s ranking system evaluates multiple factors, including content quality, backlink count, and search term relevance.
Purchased backlinks
Acquiring backlinks through purchase might seem like a shortcut to better rankings, but Google penalizes such practices.
Paid indexing services
The belief that paid services can expedite Google’s indexing process is unfounded. There’s no assured way to speed up listing through monetary means.
Google Index Checker for Preventing Indexation Issues
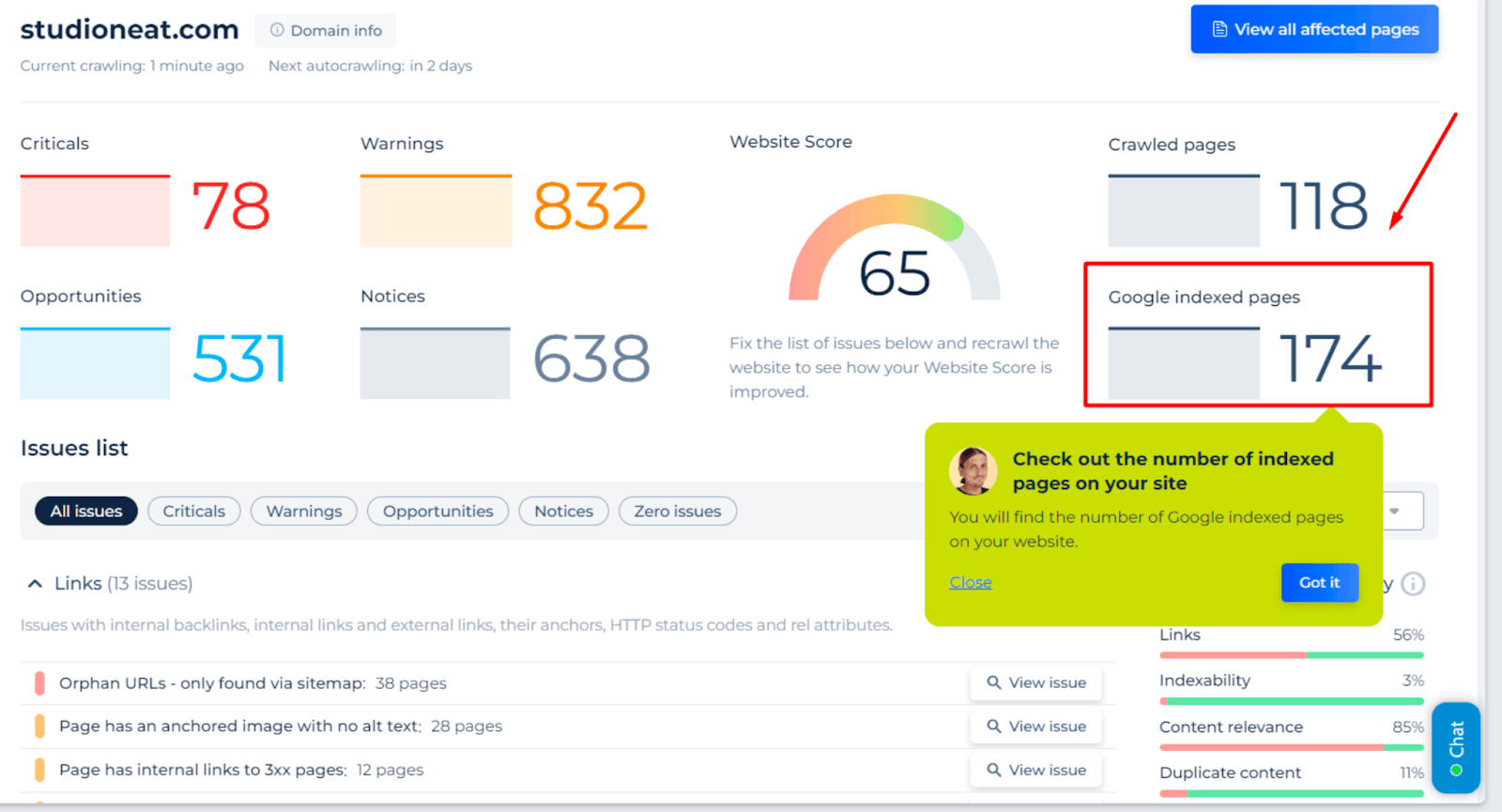
Google Index Checker by Sitechecker.pro offers a direct insight into how many of a website’s pages are indexed by Google. This information is crucial as it reveals how visible your content is to the world’s most used search engine. If certain vital pages are not listed, they remain invisible to users searching on Google.
Furthermore, understanding which pages are listed can help website owners pinpoint potential problems. A sudden drop in indexed pages could indicate technical issues, penalties, or misconfigured settings. By identifying these disparities early on, one can take corrective actions swiftly, ensuring a smooth user experience and maintaining optimal website visibility.
Using tools like the Google Index Checker becomes an indispensable part of a holistic SEO strategy. Not only does it help in maintaining a healthy website indexation, but it also acts as an early warning system for potential issues that might impact a website’s search visibility and performance.
Summary
Google Index serves as a storage system for significant web pages, enabling swift search results. It doesn’t scan the entire web in real time. Instead, Googlebot, Google’s web crawler, assesses pages based on factors like content quality, relevance, and structure. The decision to list a page hinges on several elements, including its content, the site’s structure, technical SEO aspects, and backlinks. Tools like Google Search Console and Google Index Checker play crucial roles in monitoring and fine-tuning a website’s indexation status. There are also mechanisms, such as NoIndex and Canonical tags, to offer webmasters control over what’s added to the database of the search engine.
 Response Code: Meaning, Issues with 200 Status Codes")




