Il est tout à fait possible que vous êtes au courant ce que c’est SEO et quels sont les principes de son fonctionnement: la valeur de la structure du site, les règles de marquage, la farce de mots clés, la valeur de l’optimisation du contenu unique et d’autres. Alors vous connaissez les robots de Google. Mais qu’est-ce que c’est? Ce phénomène diffère de l’optimisation SEO bien connue, car elle est réalisée au niveau plus profond. Si l’optimisation SEO s’occupe de l’optimisation d’un texte pour les requêtes SE, alors Google Bot est un processus d’optimisation de site Web pour Google spiders. Bien sûr, ces processus sont pareils. Mais il est important d’apprendre la différence entre les deux, car cela peut influencer profondément votre site. Je parlerai ici d’un phénomène tel que la crawbility du site, parce que c’est le problème principal auquel tout le monde devrait prêter attention si l’on parle de recherche sur le site Web.
Qu’est-ce que Googlebot?
Les robots de téléchargement ou Google bots sont des robots qui examinent une page Web et créent un index. Si une page permet à un bot d’y accéder, alors celui-ci ajoute cette page à un index, et seulement après cela la page devient accessible aux usagers. Si vous souhaitez apprendre comment ce processus est effectué, vérifiez ici. Pour comprendre le processus d’optimisation de Googlebot, vous devez comprendre comment un robot d’indexation de Google analyse le site. Ce processus comprend quatre étapes.
Si la page a le niveau de classement élevé, le robot d’indexation de Google passera plus de temps sur son crawling.
Ici, nous pouvons parler de “budget de crawl”. C’est une quantité exacte de temps passé par les robots Web sur le scannage d’un certain site. Le budget s’augmente avec l’autorité de la page vérifiée par website crawler.
Les robots Google explorent un site Web en permanence
Voici ce que Google dit à ce sujet: “Le robot de Google n’a pas accès à un site Web plus d’une fois par seconde.” Alors votre site est sous le contrôle constant des moteurs d’exploration si ils ont accès à celui-ci. Aujourd’hui, de nombreux gestionnaires de SEO se disputent sur ce que l’on appelle le «taux d’exploration» et essaient de trouver un moyen optimal d’exploration de site Web pour obtenir un niveau élevé. Pourtant c’est une interprétation icorrecte. Le “taux d’exploration” n’est rien de plus qu’une vitesse des demandes de robot de Google. Vous pouvez même modifier vous-même ce taux. Pour cela utilisez les Outils pour les webmasters. Le grand nombre de backlinks, l’unicité et les mentions sociales influencent votre position dans les résultats de recherche. Je devrais également noter que les moteurs d’exploration de Web ne scannent pas chaque page constamment. C’est pourquoi il faut bien élaborer des stratégies de contenu. Le contenu unique et utile attire l’attention du bot.
Le fichier Robots.txt est la première chose que les robots Google analysent afin d’obtenir une feuille de route pour l’exploration du site.
Et quand une page est marquée comme non autorisée dans ce fichier, les robots ne pourront pas la scanner et l’indexer.
XML sitemap est un guide pour les robots de Google
Le sitemap XML aide les bots à découvrir quels sites web doivent être explorés et indexés, car il peut y avoir des différences dans la structure et dans l’organisation du site. Ce processus peut ne pas être automatique. Un bon plan Sitemap peut aider les pages avec un faible niveau de classement, avec peu de backlinks et le contenu inutile. Il aide aissi Google à gérer les images, les nouvelles, les vidéos, etc.
6 stratégies pour optimiser votre site pour l’exploration de Googlebot
Vous avez déjà compris que l’optimisation de Google doit se faire avant l’optimisation SE. C’est pourquoi nous allons apprendre ce que vous devriez faire pour faciliter le processus d’indexation pour les robots Google.
Il ne faut pas faire trop
Savez-vous que Googlebots ne peuvent pas scanner différents cadres, Flash, JavaScript, DHTML et le HTML. De plus, Google n’a pas encore précisé si Googlebot est capable d’explorer Ajax et JavaScript. C’est pourquoi il est préférable de ne pas les utiliser lors de la création de votre site web. Matt Cutts déclare que JavaScript peut être ouvert pour les moteurs d’exploration, mais Google Webmaster Guidelines réfute ceci: “Si des cookies, des cadres différents, Flash ou JavaScript ne peuvent pas être vus dans un navigateur texte, alors les moteurs d’eploration web pourraient ne seront pas capable d’explorer ce site. “À mon avis JavaScript ne doit pas être surutilisé.
Il ne faut pas sous-estimer le fichier robots.txt
Avez-vous déjà pensé quel est l’objectif du fichier robots.txt? C’est le fichier commun utilisé dans de nombreuses stratégies de SEO. Mais est-il utile? Tout d’abord, ce fichier est une directive pour toutes les moteurs d’explration. Et le robot de Google dépensera “le budget de crawl” sur n’importe quelle page Web de votre site. Deuxièmement, vous devez décider vous-même quel fichier les robots doivent analyser. S’il y a un fichier qui n’est pas autorisé à explorer, vous pouvez l’indiquer dans votre fichier robots.txt. Pourquoi faire ceci? Si certaines pages ne doivent pas être explorées, Google Bot les verra immédiatement et analysera la partie de votre site qui est plus importante. Cependant, ma suggestion est de ne pas bloquer ce qui ne devrait pas être bloqué. Si vous n’indiquez pas que quelque chose est interdite à explorer, le robot va le crawler et l’indexer. La fonction principale du fichier robots.txt est indiquer au robot où il ne doit pas aller.
Le contenu utile et unique est important
D’après la règle le contenu qui est crawlé plus fréquemment a le trafic plus élevé. Malgré le fait que PageRank détermine la fréquence de crawling, il peut s’écarter si l’on parle de l’utilité et de la fraîcheur des pages qui ont un PageRank similaire. C’est pourquoi votre objectif principal est de faire scanner régulièrement vos pages les moins bien classées. AJ Kohn a dit un jour: “Vous êtes un gagnant si vous avez fait de vos pages les moins bien classées celles qui sont scannées plus fréquemment que les pages de vos concurrents.”
Les pages de défilement magiques
Si votre site contient beaucoup de pages de défilement, cela ne signifie pas que vous n’avez aucune chance pour l’optimisation de Googlebot. Vous devez vous assurer tout simplement que ces pages sont conformes aux directives de Google.
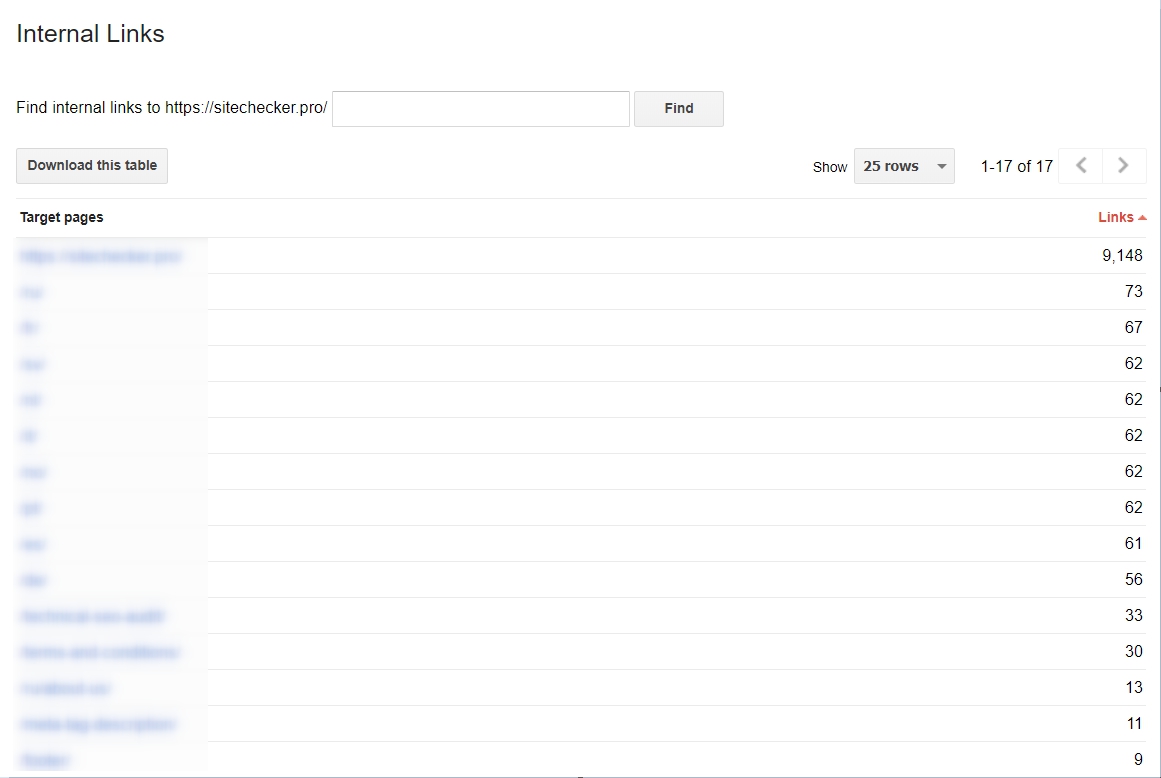
Vous devez commencer à utiliser des liens internes
Cette stratégie est très importante quand vous souhaitez rendre le scannage beaucoup plus facile pour Googlebot. Si vos liens sont soudés et consolidés, ce processus sera très rapide. Pour obtenir une analyse de vos hyperliens internes, vous choisissez les outils Google pour les webmasters, puis Search Traffic et la section Liens internes. Si les pages sont en haut de la liste, elles ont le contenu utile.
L’importance de Sitemap.xml
Le sitemap indique à Googlebot comment accéder à un site Web: c’est une carte à suivre. Alors, pourquoi est-il utilisé? Le fait est qu’aujourd’hui beaucoup de sites ne sont pas faciles à scanner, et ces difficultés peuvent rendre le processus de crawling très compliqué. C’est pourquoi les sections de votre site qui peuvent confondre les moteurs d’exploration sont indiquées dans le sitemap. Cela peut garantir que toutes les zones du site seront crawlées.
Comment analyser l’activité de Googlebot?
Pour analyser l’activité de Googlebot sur votre site, vous pouvez utiliser Google Webmaster Tools. Je vous conseille aussi de vérifier régulièrement les données fournies par ce service. Cela vous indiquera si des problèmes surviennent lors du crawling. Pour cela vérifiez simplement la section “Crawl” dans vos Outils pour les webmasters.
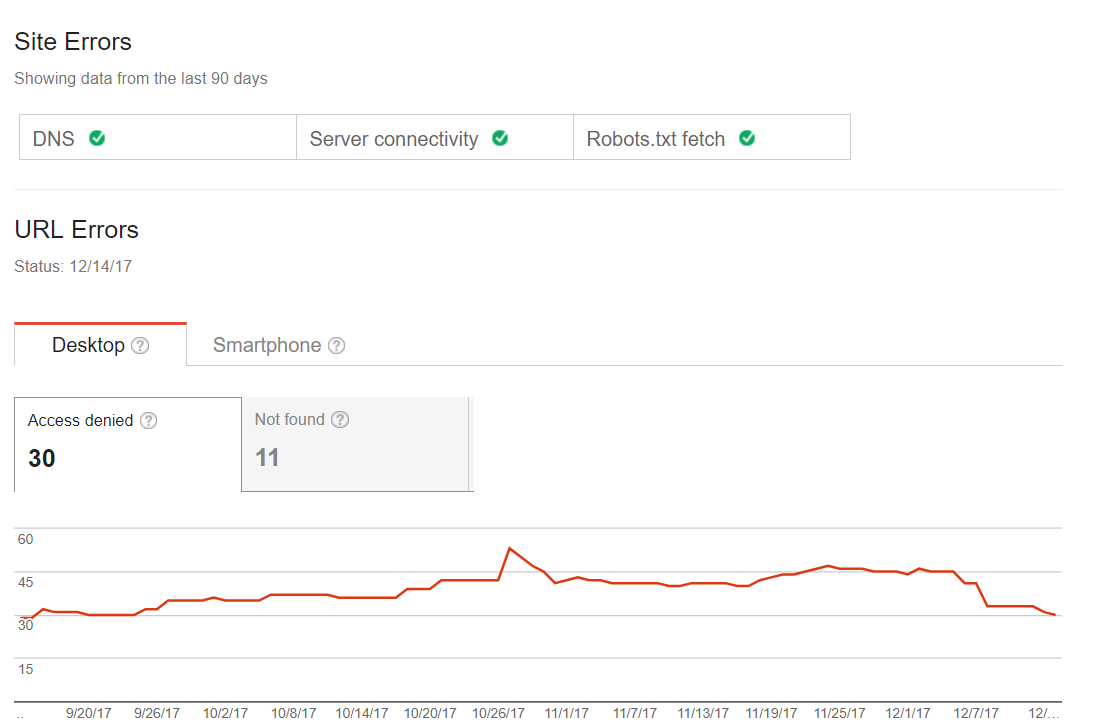
Les erreurs de crawling courantes
Vous pouvez vérifier si votre site confronte des problèmes avec le scannage. C’est la première chose que vous devriez faire pour l’optimisation de Googlebot. Certains sites Web peuvent avoir de petites erreurs avec le scannage, mais cela ne signifie pas qu’elles influenceront le trafic ou le classement. Néanmoins, avec le temps, ces problèmes peuvent entraîner une baisse du trafic. Ici vous pouvez trouver un exemple d’un tel site:
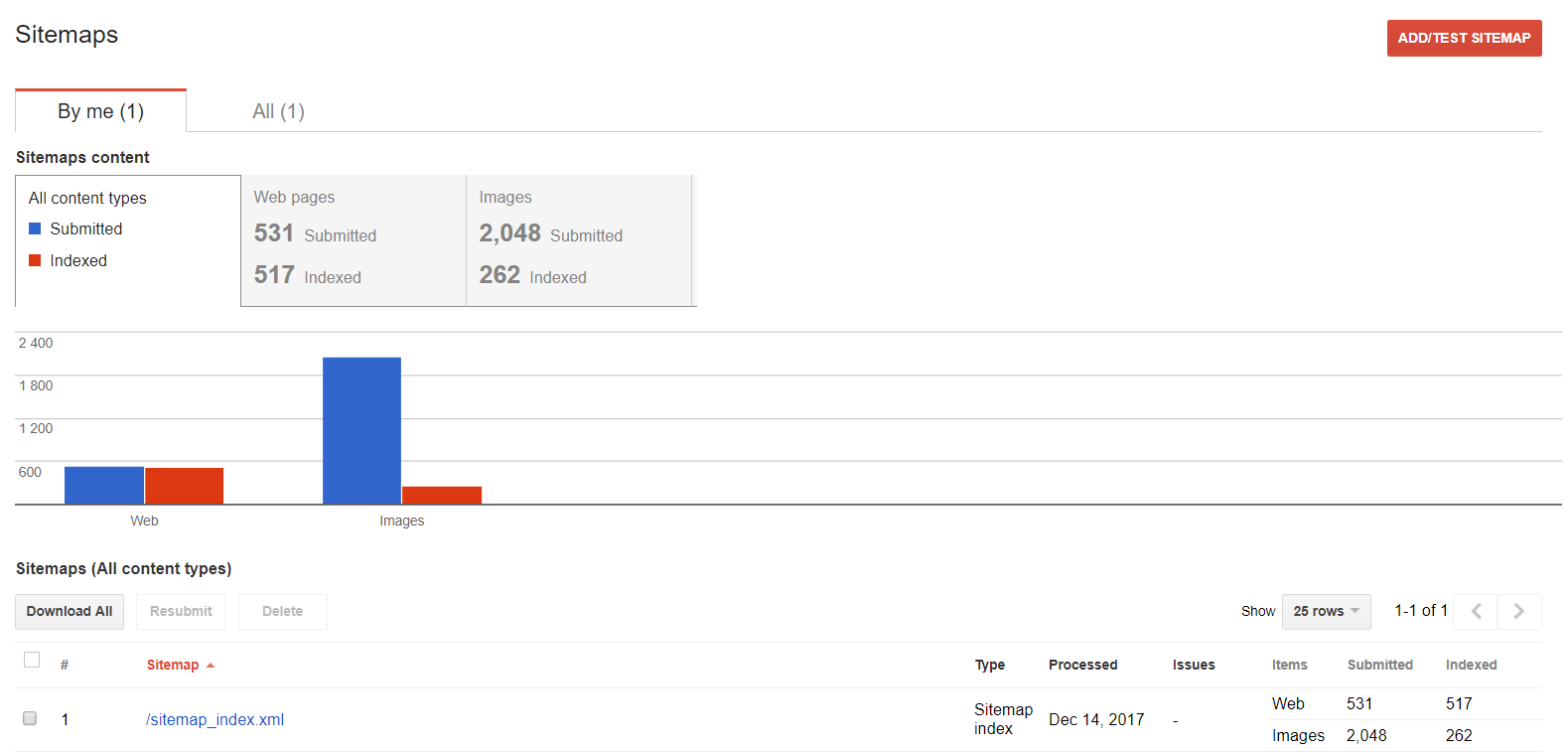
Sitemaps
Vous pouvez utiliser cette fonction si vous souhaitez travailler avec votre sitemape. Vous pouvez examiner, ajouter ou trouver le contenu indexé.
Fetching
La section “Fetching as Google” vous aide à voir votre site / page de la façon dont Google le voit.
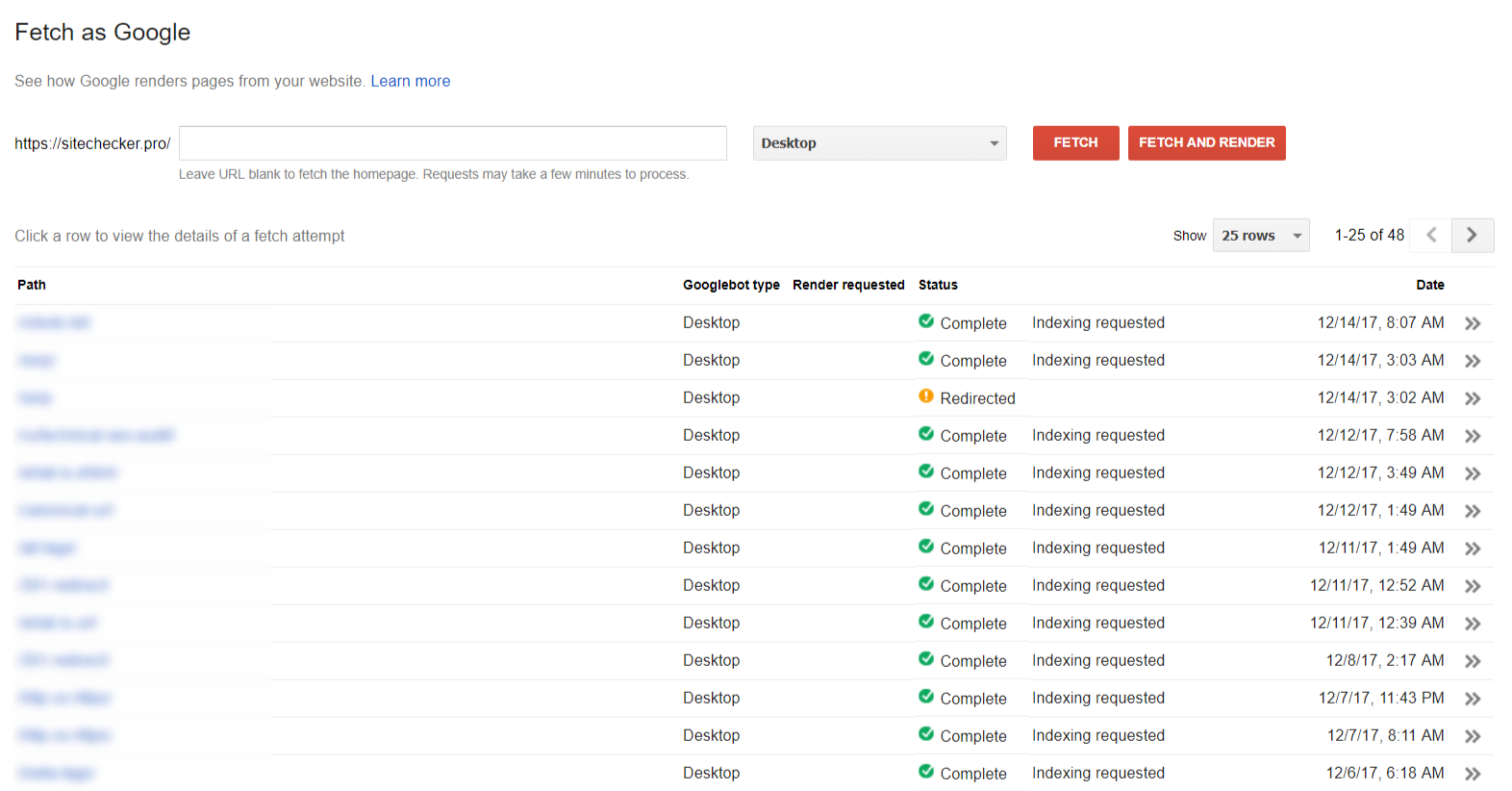
Les statistiques de crawling
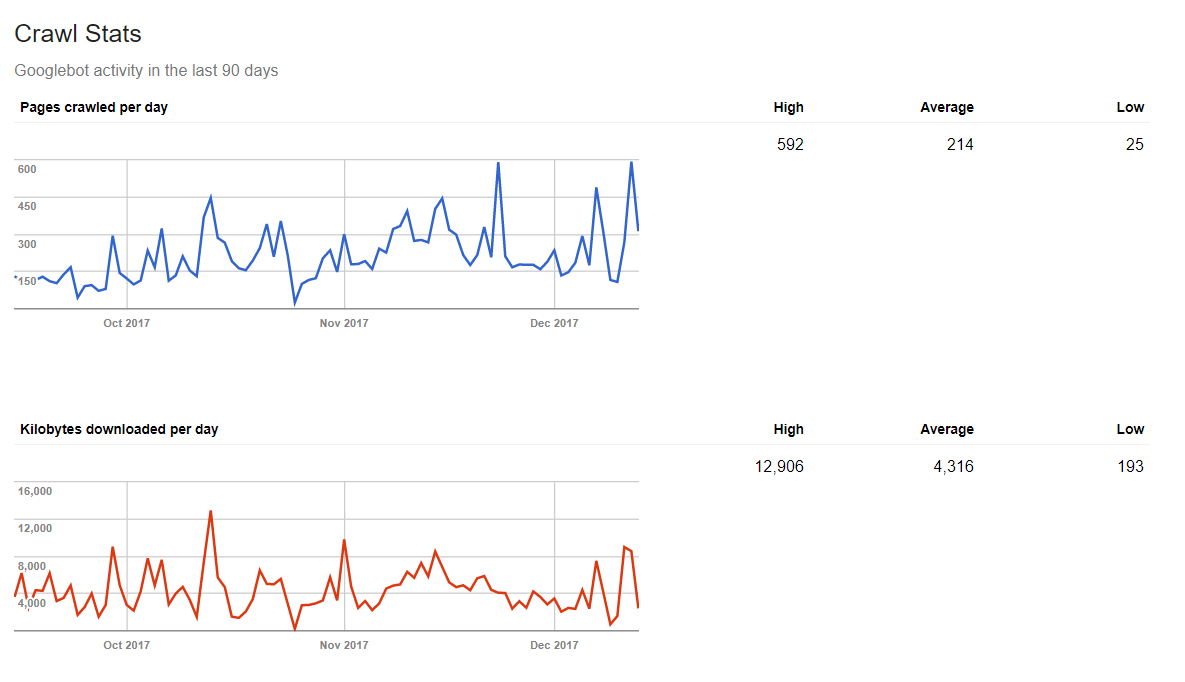
Google peut également vous informer combien de données un moteur d’exploration traite pendant une journée. C’est pourquoi en publiant le contenu frais régulièrement, vous obtiendrez un résultat positif dans les statistiques.
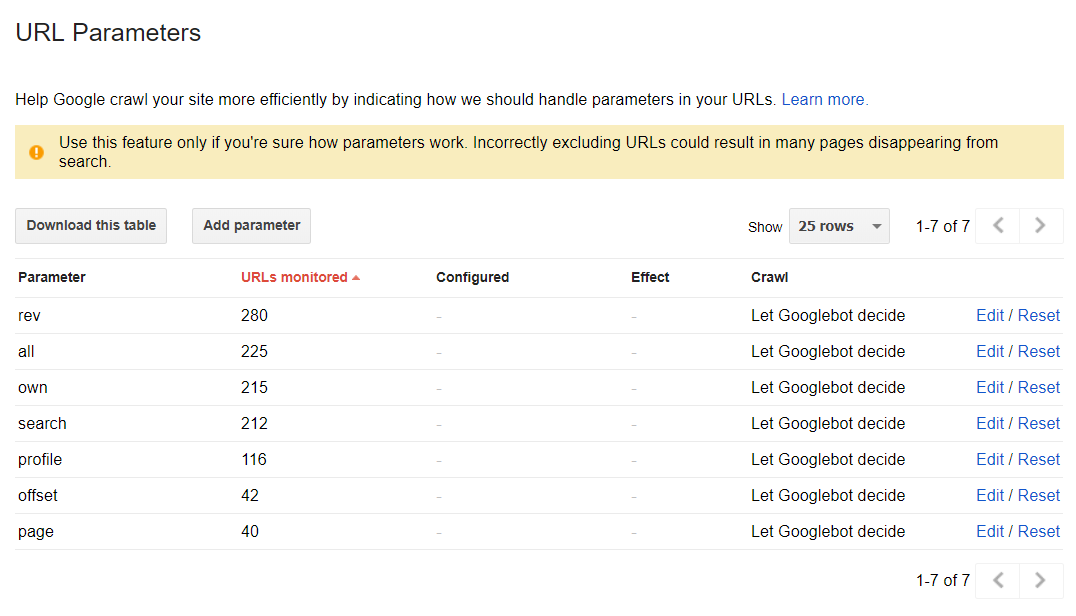
Les paramètres de l’URL
Cette section peut vous aider à découvrir comment Google explore et indexe votre site Web à l’aide de paramètres d’URL. Cependant, en mode par défaut, toutes les pages sont explorées d’après les décisions des moteurs d’exploration: