



Duplicate pages without canonical issue means that website has pages with identical contents without the link tag with the rel=canonical attribute value.
The Importance of the Issue
Duplicated content degrades the pages’ value, leading to degrading text relevance and making the search engine waste crawling budget and choose the best page among two identical ones. This may lead to the ranking decrease of the main landing page, as well as to negative user experience in case one gets to the duplicate page instead of the main one.
How to Check the Issue
Using any browser is enough to check the issue. Open the source code of the flawed page To do this, click the right mouse button at any spot of the page and choose “browse the code” option, or apply an online tool https://codebeautify.org/source-code-viewer.
Find the <link> tag with the rel=canonical attribute value. If there is no tag with the attribute, or it forwards to the URL of a current affected page, then there is an issue.
A classic example is when goods are sorted in the page with the help of URL parameters.
Example:
main page: https://site.com/asus/
sorting page: https://site.com/asus/?sort=desc
There is an issue, if:
- the page https://site.com/asus/?sort=desc has no link tag formatted as follows: <link rel=”canonical” href=”https://site.com/asus/”>;
- the page contains a link tag forwarding to the current page <link rel=”canonical” href=”https://site.com/asus/?sort=desc”>.
Sitechecker SEO tool has a specialized feature that identifies a common issue many websites face: duplicate pages without canonical tags. This particular issue is highlighted under the ‘Content relevance’ category because it can significantly impact your SEO efforts. Instead of getting overwhelmed by the total number of affected pages, our tool allows you to focus on the specific problem.
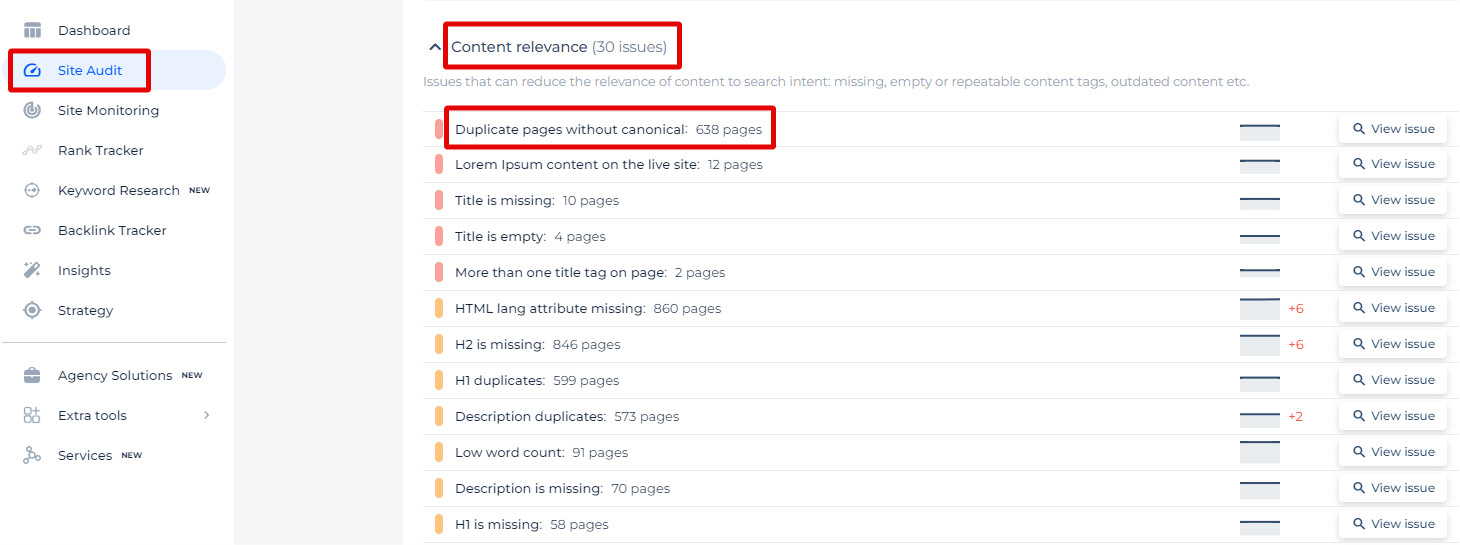
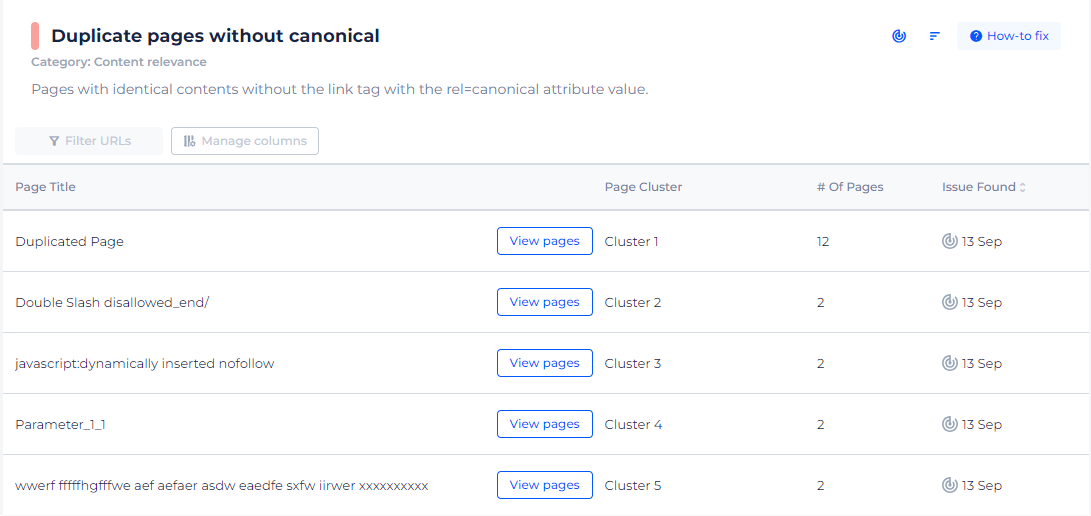
Our tool doesn’t just tell you that you have duplicates; it categorizes them into clusters for easy management. When you click on ‘View pages’ for any given cluster, you’ll not only see a list of the URLs with potential duplicate content but also specific details like the title of the pages and the date the issue was identified. This targeted approach helps you address each case of duplication methodically, ensuring that your content has the best chance to rank well in search engines. Remember, it’s not about the sheer volume of pages; it’s about identifying and resolving these critical issues that can dilute your SEO efforts.
Detect & Canonicalize Duplicates!
With our intuitive Canonical URL Checker, you can spot and consolidate duplicate pages.
How to Fix This Issue
Fixing duplicate pages without canonical tags is essential to avoid SEO issues and ensure your website is optimized for search engines. Here are several strategies to address this issue:
1. Implement Canonical Tags
Even though the problem is the absence of canonical tags, implementing them is a straightforward solution. The canonical tag tells search engines which version of a URL is the preferred one.
- Identify the replicated URL.
- Add a canonical tag to the <head> section of the HTML on all replicated URL, pointing to the preferred version.
<link rel="canonical" href="https://www.example.com/preferred-page/"/>
2. 301 Redirects
Use 301 redirects to redirect duplicate URLs to the preferred link permanently. This is particularly useful if the duplicate content is not necessary.
- Identify the cloned pages.
- Add 301 redirects from duplicate pages to the preferred page in your .htaccess file (for Apache servers) or through your server’s configuration.
Redirect 301 /duplicate-page https://www.example.com/preferred-page
3. Use Noindex Meta Tag
If the replicated link does not need to appear in search results, you can use the noindex meta tag.
- Identify the duplicate URLs.
- Add the following meta tag to the <head> section of the HTML on the duplicate links.
<meta name="robots" content="noindex">
4. Consolidate Content
If possible, consolidate the content from the duplicate pages into a single page. This not only solves the duplication issue but can also enhance the content quality.
- Review the content of the replicated link.
- Merge the relevant information into a single, comprehensive page.
- Redirect the duplicate links to the consolidated page using 301 redirects.
5. URL Parameters Handling
If duplicates are created by link parameters (e.g., tracking codes, sorting options), configure your CMS or use Google Search Console to indicate how these parameters should be handled.
- Identify URL parameters causing duplication.
- In Google Search Console, go to URL Parameters and set the parameters to be ignored or specify their function.
6. Sitemap Optimization
Ensure your sitemap only includes the preferred links. This helps search engines understand which URLs to index.
- Review your sitemap file.
- Remove URLs of replicated URLs, keeping only the preferred pages.
7. Internal Linking Structure
Ensure your internal links point to the preferred version of a page. This can reduce the instances of search engines indexing replicated links.
- Audit internal links.
- Update links to point to the preferred page.





