



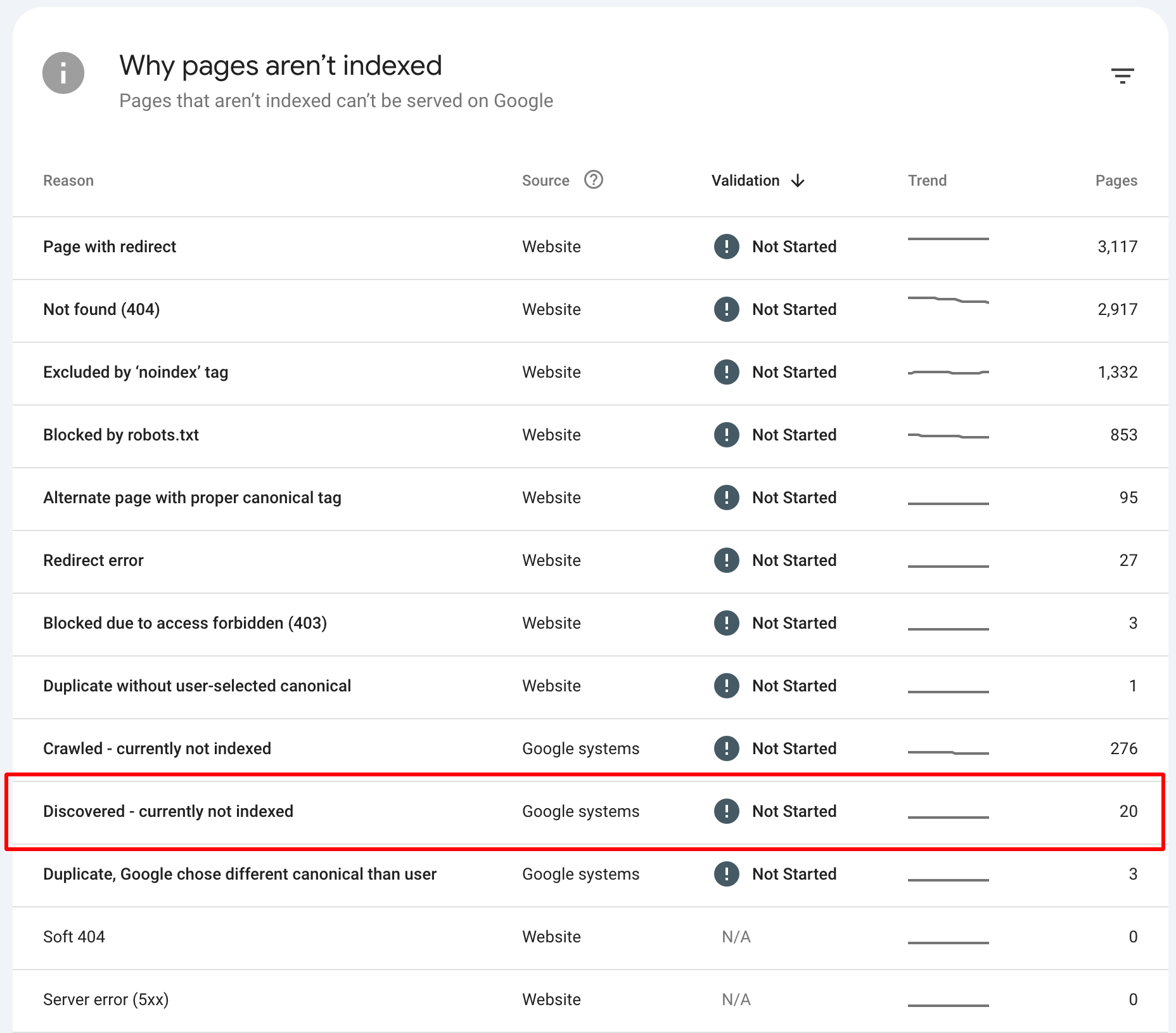
Understanding “Discovered – Currently Not Indexed” and how to fix it
When Google marks a page as “Discovered – Currently Not Indexed,” it means Googlebot has found the page but hasn’t added it to Google’s search index yet. This can happen for various reasons, and it prevents your page from appearing in search results, impacting visibility and traffic.
Launch Sitechecker’s GSC Dashboard to boost your Search Console reporting!
Expand GSC Data Limits
Bypass Google’s 1,000-row cap and unlock up to 36 months of Search Console history in a single dashboard.
What does “Discovered – Currently Not Indexed” mean?
Googlebot has crawled the page but hasn’t indexed it for various reasons, such as technical issues or content quality concerns.
Common causes include
- Crawl budget issues (e.g., subdomains or redirects taking up too much crawl time)
- Technical problems (e.g., broken links, server errors)
- Duplicate content or low-quality material
- Misconfigured robots.txt or noindex tags
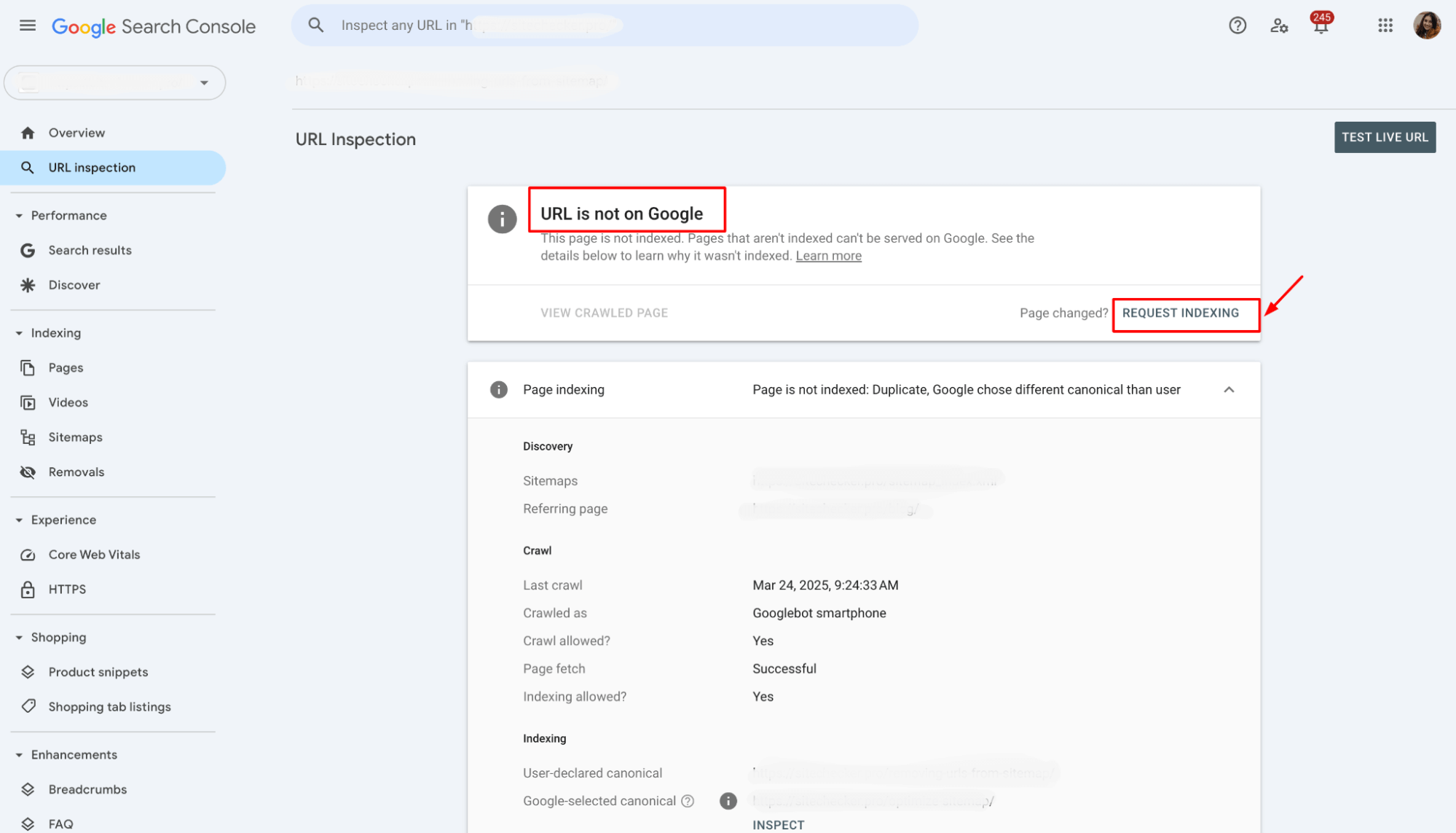
If you’ve noticed that your page is stuck in the “discovered, currently not indexed” status, the quickest way to jumpstart the process is to request indexing in Google Search Console.
It’s a simple step but often surprisingly effective.
Here’s the deal: Google doesn’t always crawl your site immediately after discovering it, especially if there’s a backlog or limited crawl budget.
By manually requesting indexing, you’re telling Google, “Hey, take a closer look at this page now!” This can prompt the search engine to prioritize and speed up the process.
To do this, go to Google Search Console, find the “URL Inspection” tool, and enter the URL of the page you want indexed.
If everything checks out, just click the “Request Indexing” button, and voilà – you’ve put your page in the queue.
Is your crawl budget being wasted? Here’s how to check
Crawl budget refers to the number of pages Googlebot crawls on your site within a given timeframe. If your crawl budget is misused, Google might not index your valuable content. So, how do you know if your budget is being wasted? Here’s what to look for:
1️⃣ Subdomains crawling frequency
First, check for subdomains that might steal attention from your leading site. Google sees subdomains as separate sites, and if they aren’t set up correctly, Googlebot could be wasting its crawl time on them instead of focusing on your primary pages.
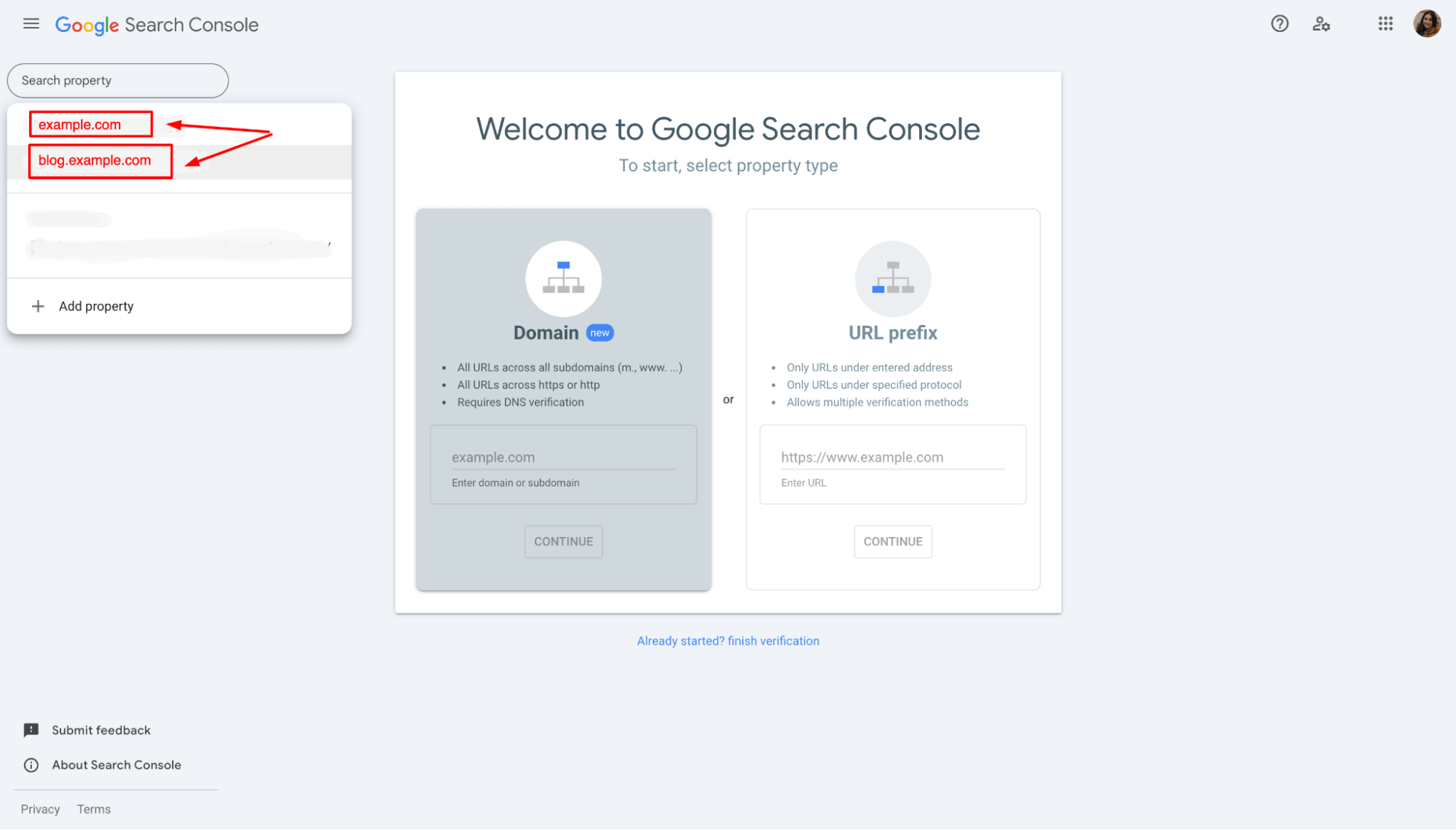
1. Check Google Search Console for subdomain data
a. Log into your Google Search Console account.
b. In the left-hand menu, under “Property,” look for any subdomains listed as separate properties.
For example, if your leading site is example.com, check for subdomains like blog.example.com or shop.example.com that may be treated as separate sites by Google.
c. Each subdomain will have its own crawl and indexing data.
If a subdomain is getting more crawl time than necessary, this could be eating into your primary site’s crawl budget.
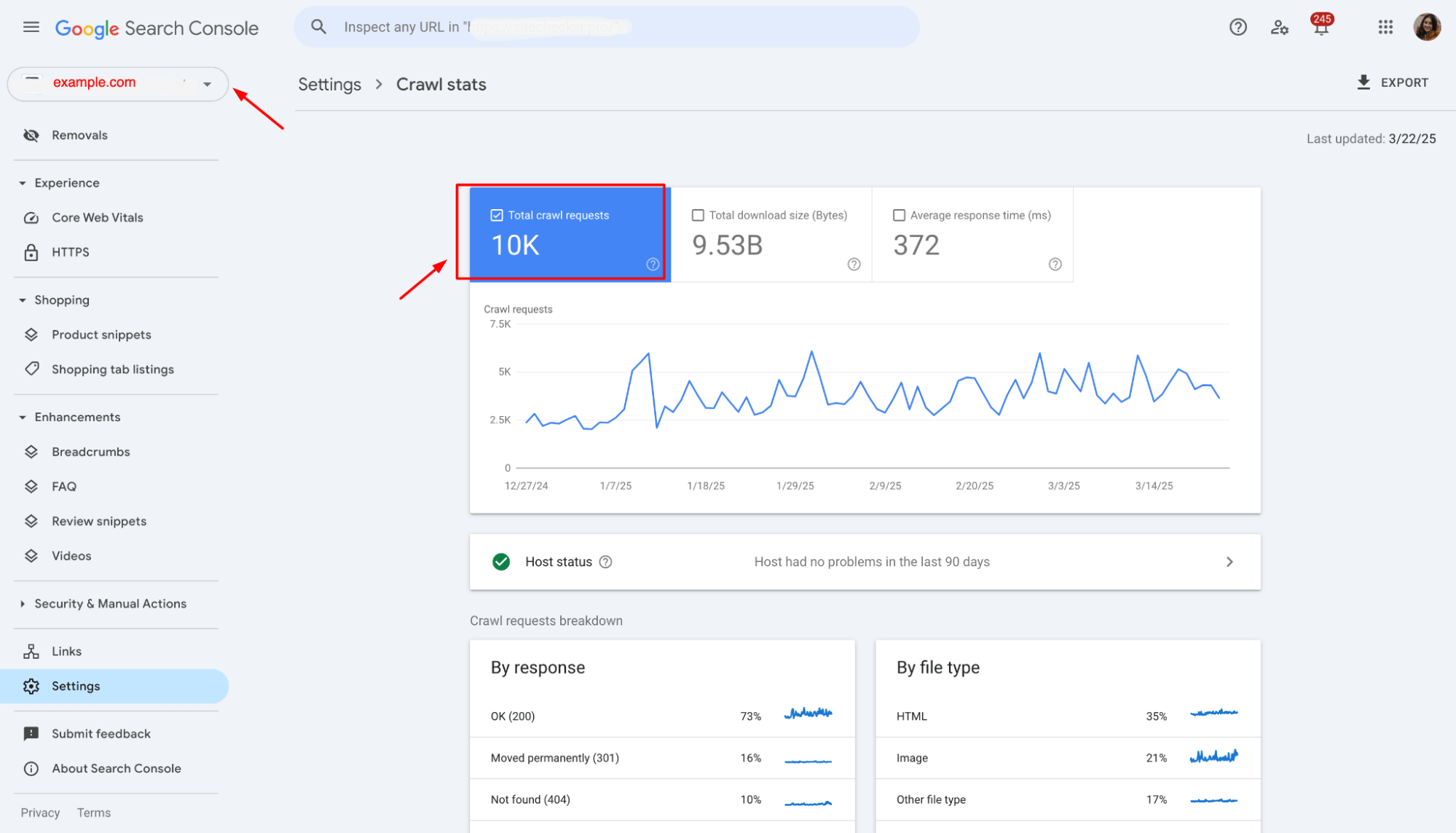
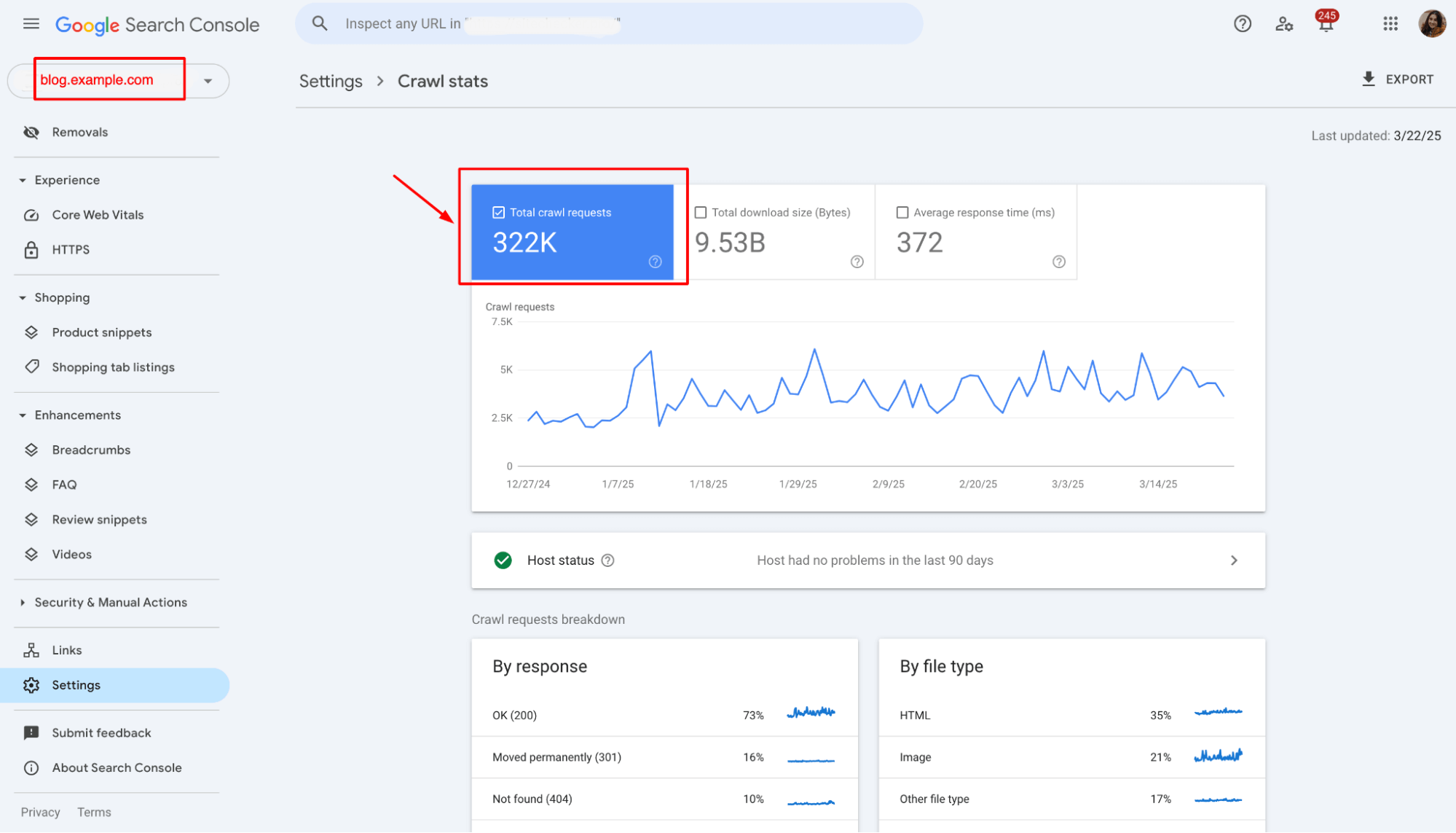
2. Analyze Crawl Data
In the “Crawl Stats” section of Google Search Console, review how often Googlebot crawls your subdomains compared to your leading site.
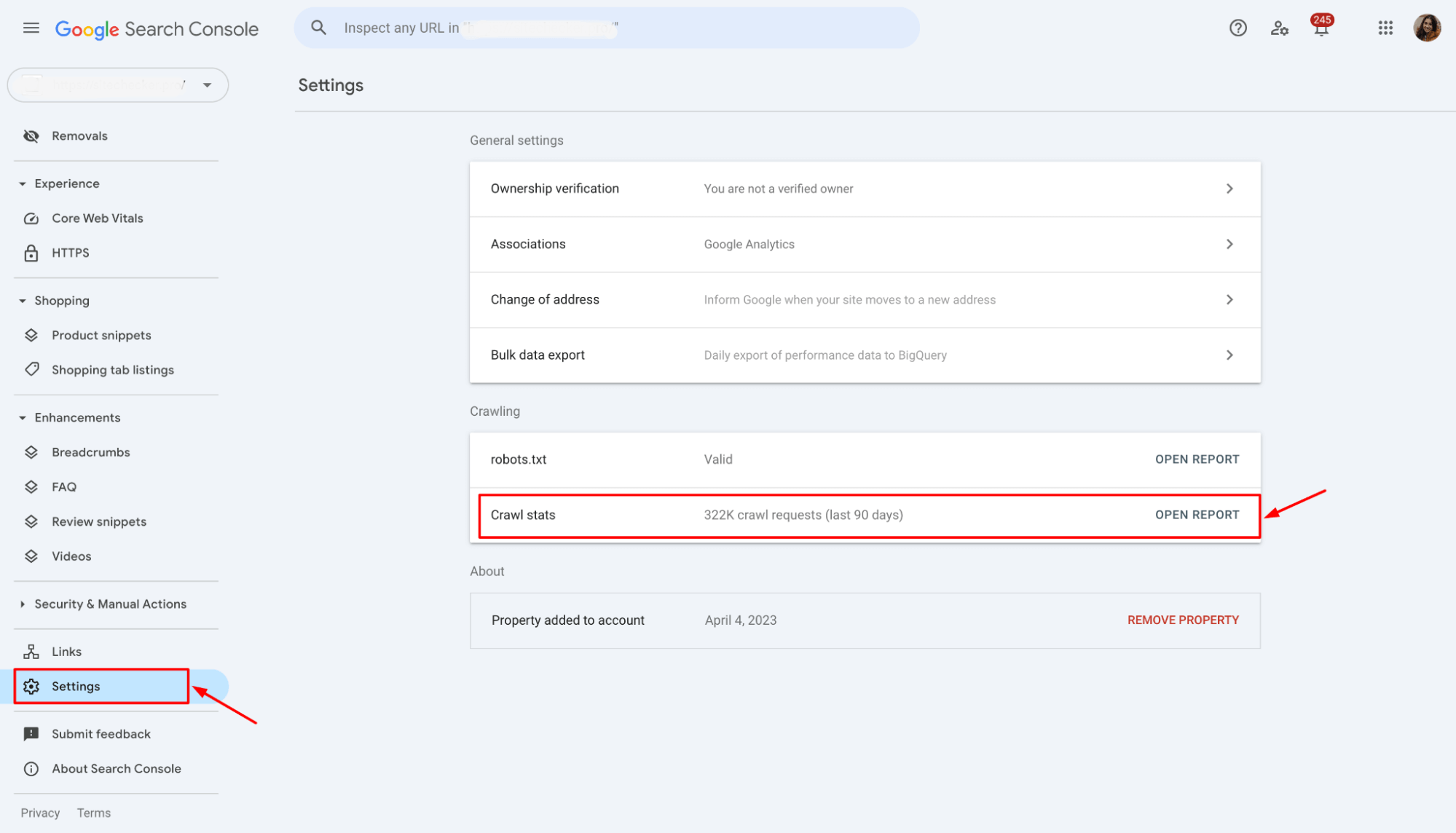
If you notice that Googlebot is spending a disproportionate amount of time on subdomains, consider revising your setup to ensure they don’t distract Google from indexing your most important pages.
3. Review robots.txt files
Make sure that your subdomains aren’t unintentionally blocked in the robots.txt file. If set incorrectly, this could prevent Googlebot from properly crawling them and lead to wasted crawl budget on pages that don’t need indexing.
Check the robots.txt of each subdomain to see if any rules might be causing unnecessary blocking or hindering Googlebot’s crawl efficiency.
If you have a subdomain (e.g., blog.example.com) and your robots.txt file is incorrectly set to block it, this can prevent Googlebot from crawling it, even if it’s essential for indexing.
Here’s what the file might look like:
User-agent: *
Disallow: /blog/
This rule tells Googlebot not to crawl pages under the /blog/ directory on the main domain. If you have blog.example.com as a separate subdomain, Googlebot could ignore it entirely.
Make sure your robots.txt is configured properly for subdomains. For example, if you don’t want Google to crawl certain areas of the subdomain, you can block only specific URLs:
User-agent: *
Disallow: /blog/private/
4. Evaluate subdomain structure and necessity
Ask yourself if all subdomains are necessary. In some cases, merging subdomains into the main domain could reduce crawl waste and make indexing more efficient.
If subdomains are crucial for your site (e.g., for a blog, store, or support section), ensure they are well-optimized and linked to your leading site to maintain efficient crawling.
You can move the blog content to your leading site as a subdirectory, reducing the need for separate crawling and indexing of the blog subdomain. After merging:
// New URL structure
- Blog post: example.com/blog/post-1
- Main page: example.com/about
5. Use Google’s URL Inspection Tool
In Google Search Console, use the “URL Inspection” tool for pages from the main domain and subdomains. This will show you how Googlebot crawls and indexes those URLs.
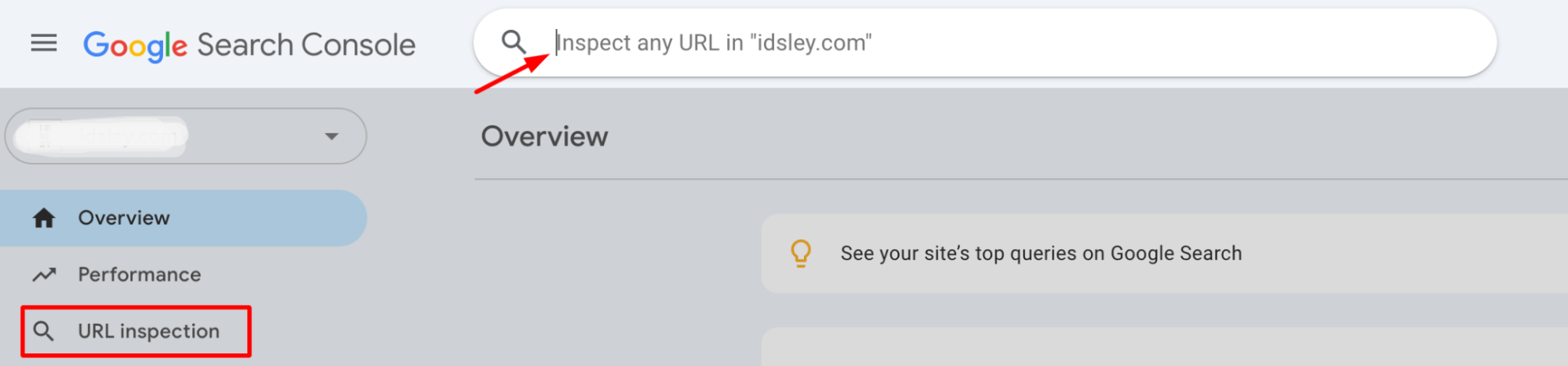
If you notice that subdomain pages are repeatedly not being crawled or indexed, or if Googlebot is spending an unusual amount of time on subdomains instead of your main site, this could indicate that crawl resources are being wasted.
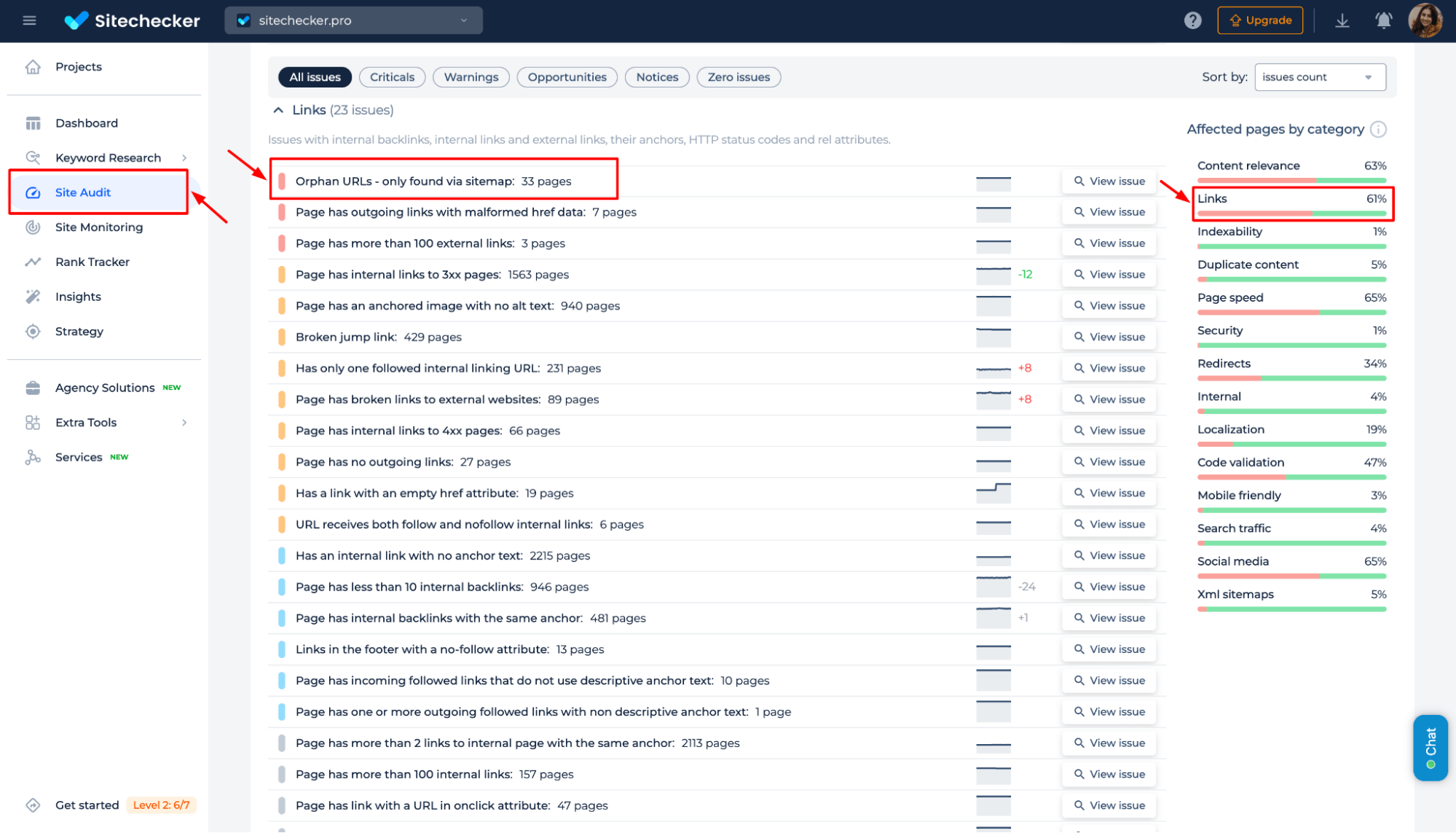
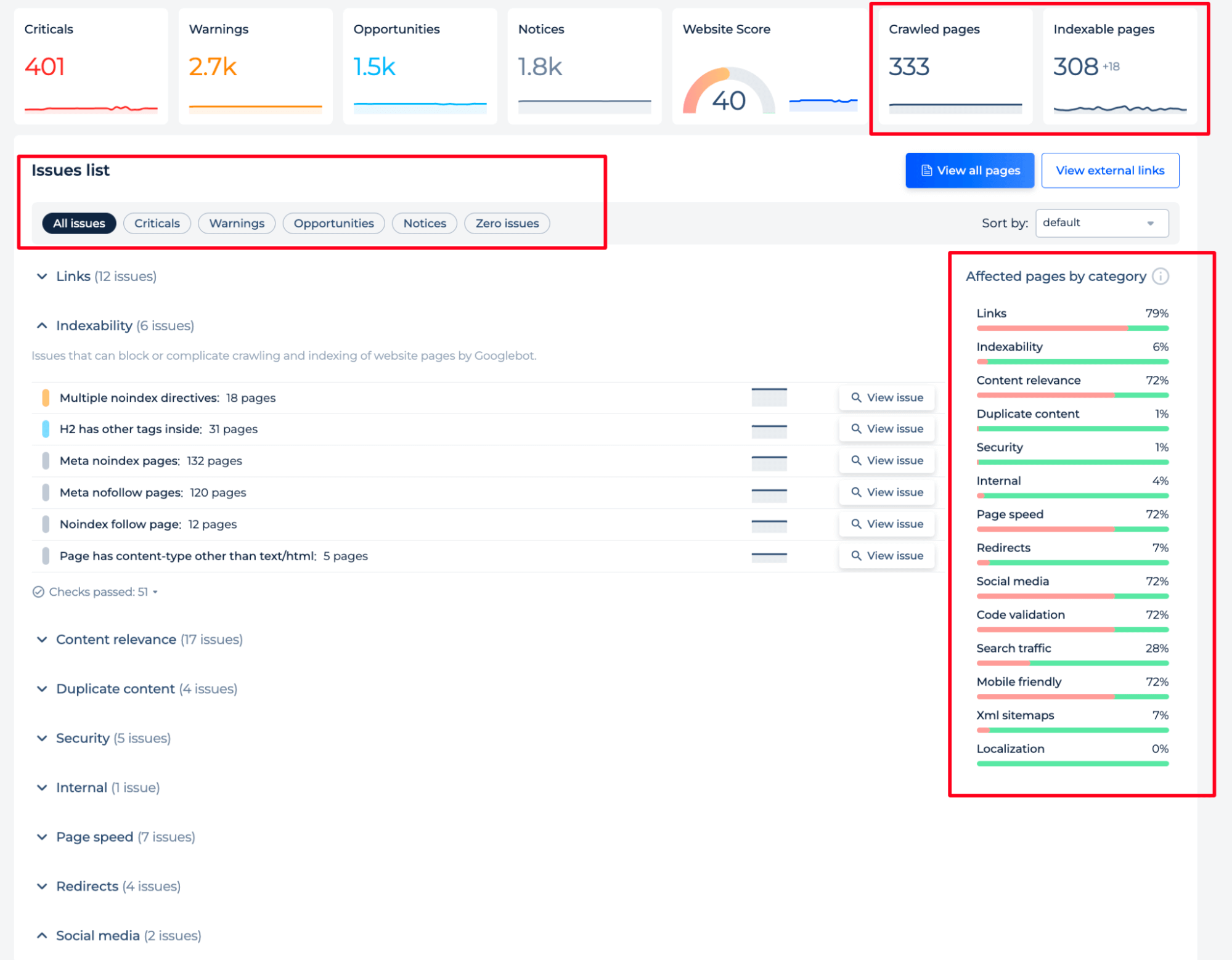
6. Inspect Google page indexing, detect issues, and fix them with Sitechecker
For quick access to indexing status, use the Sitechecker Inspection Tool. This tool allows you to check whether a page is indexed and identify any technical errors that may have impacted its indexing.
Sitechecker allows you to view real-time indexing status directly from Google Search Console data without accessing GSC separately.
To check the indexing status, navigate to the Site Audit, then go to “View All Pages” → “Page Details” → and select the “URL Inspection” tab.
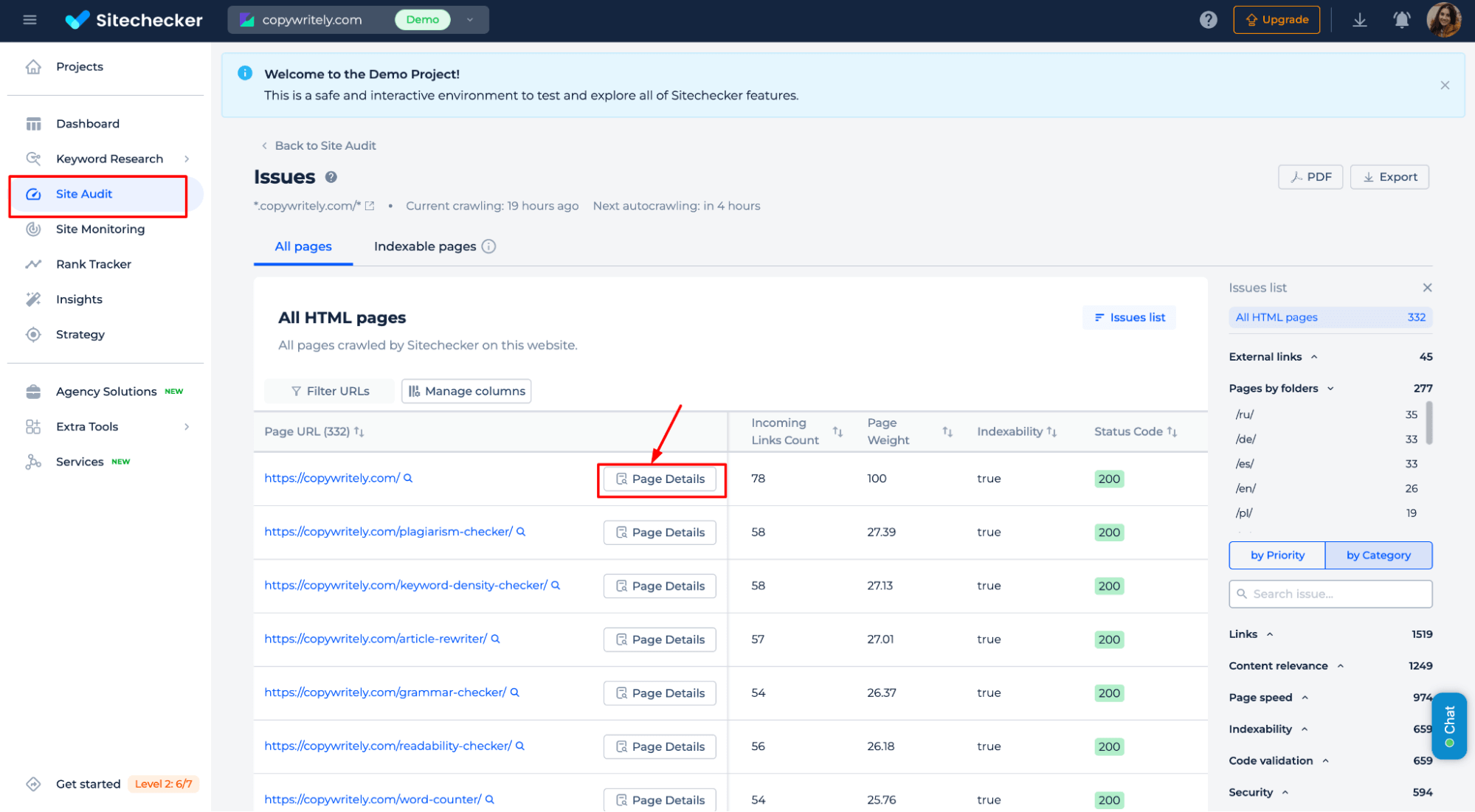
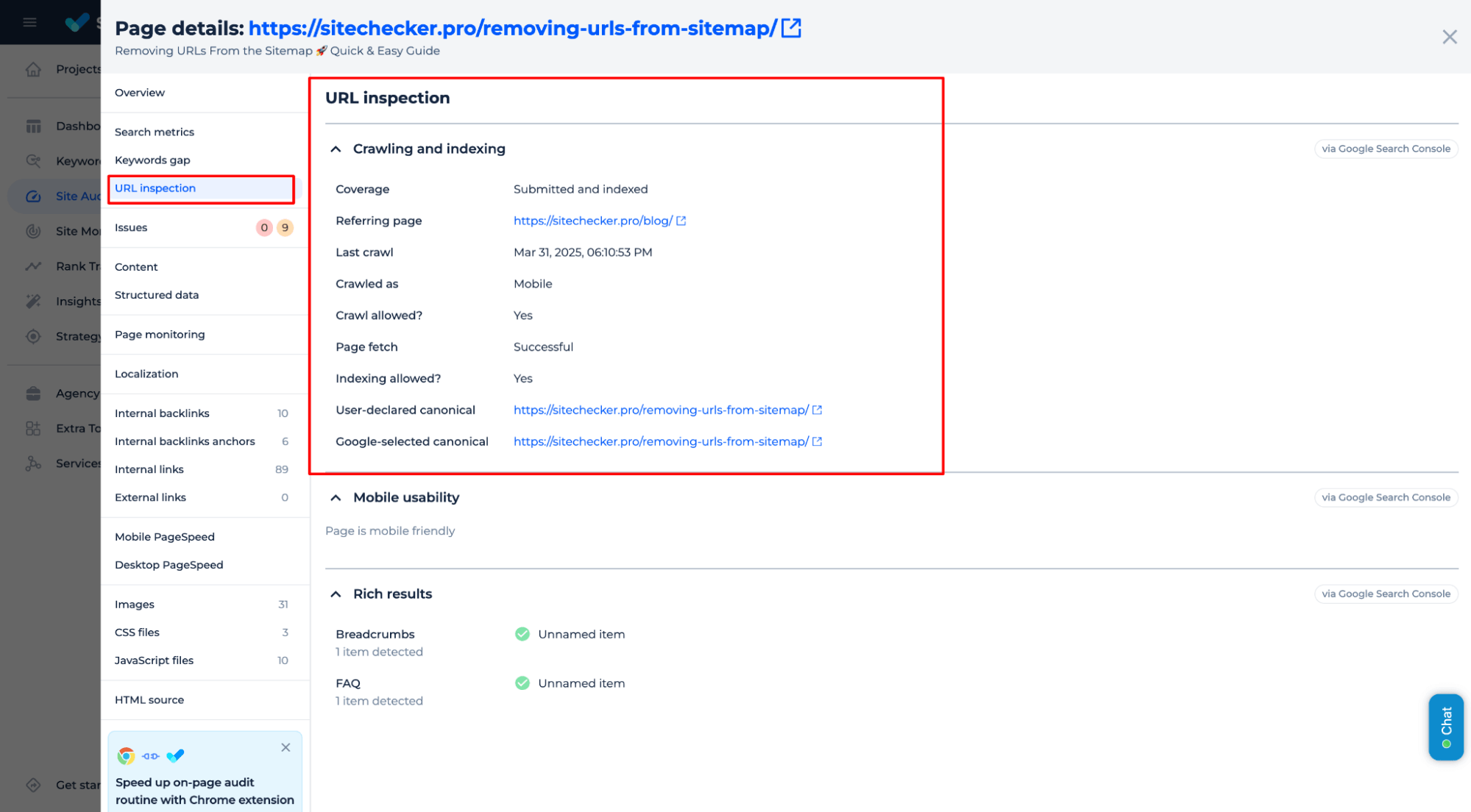
If a page has the status “Discovered – Currently Not Indexed,” go to the “Issues” tab, where you’ll find a list of errors that may be preventing indexing.
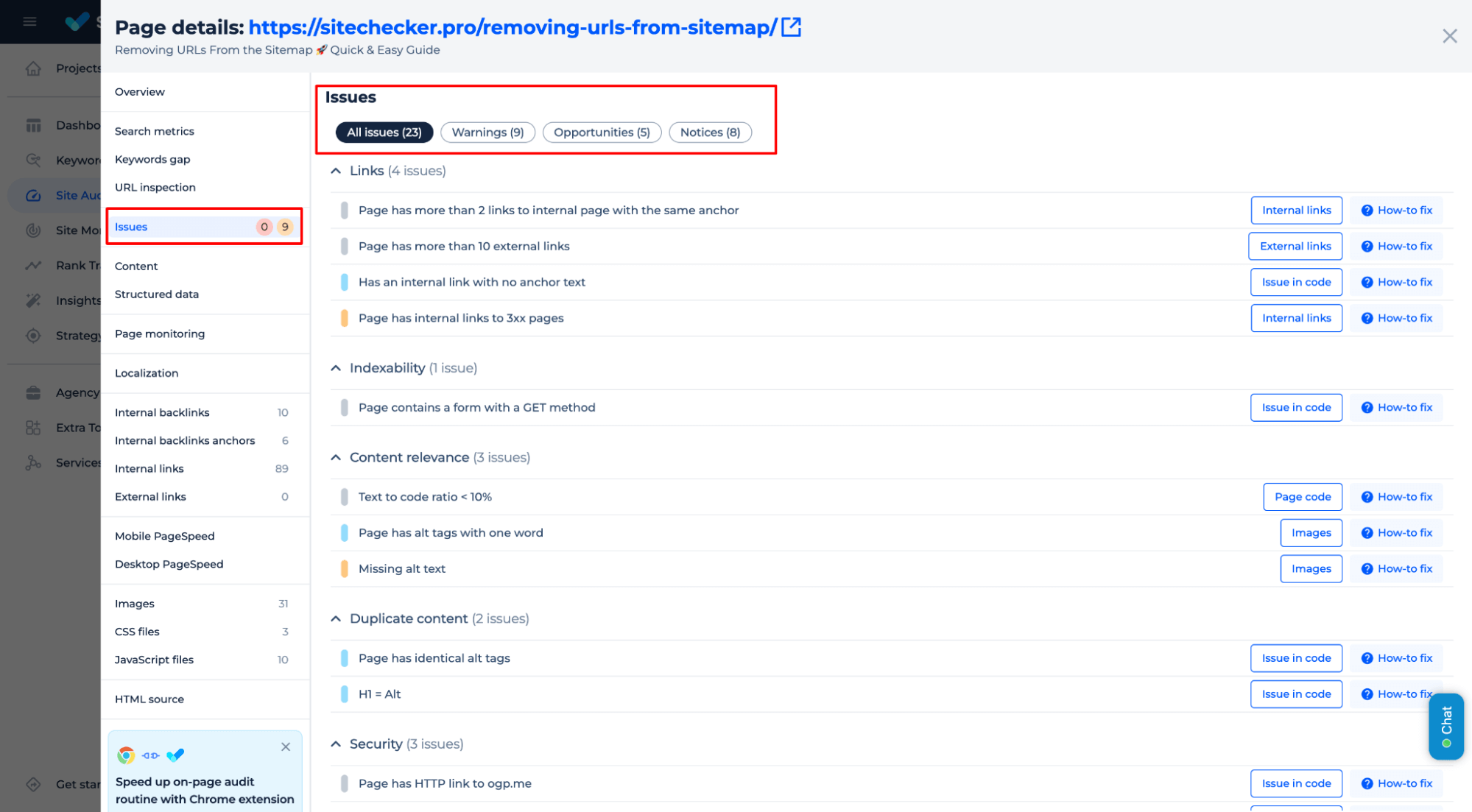
Alternatively, you can access this information directly through the Sitechecker Chrome Extension.

Stuck in “Discovered - Not Indexed”?
Quickly check for crawl issues and request indexing in Google Search Console!
2️⃣ Unnecessary redirects
Too many redirects can force Googlebot to jump around your site instead of directly crawling your pages. This delays the indexing process and eats into your crawl budget.
3️⃣ Duplicate content
If your site has duplicate content, Google might crawl multiple versions of the same page. This wastes your crawl budget and can harm your SEO rankings. Be sure to implement canonical tags to let Google know which version of the page should be prioritized.
4️⃣ Internal nofollow links
These links tell Google not to follow the linked pages, meaning they get ignored during the crawl. If you’re using nofollow links where they aren’t needed, you could limit Google’s ability to index valuable content.
You can quickly check for internal nofollow links using Sitechecker. Identify and manage internal links with the “nofollow” attribute, which tells Google not to follow those links during crawling. Review and adjust these links to avoid limiting Google’s ability to index important content on your site.
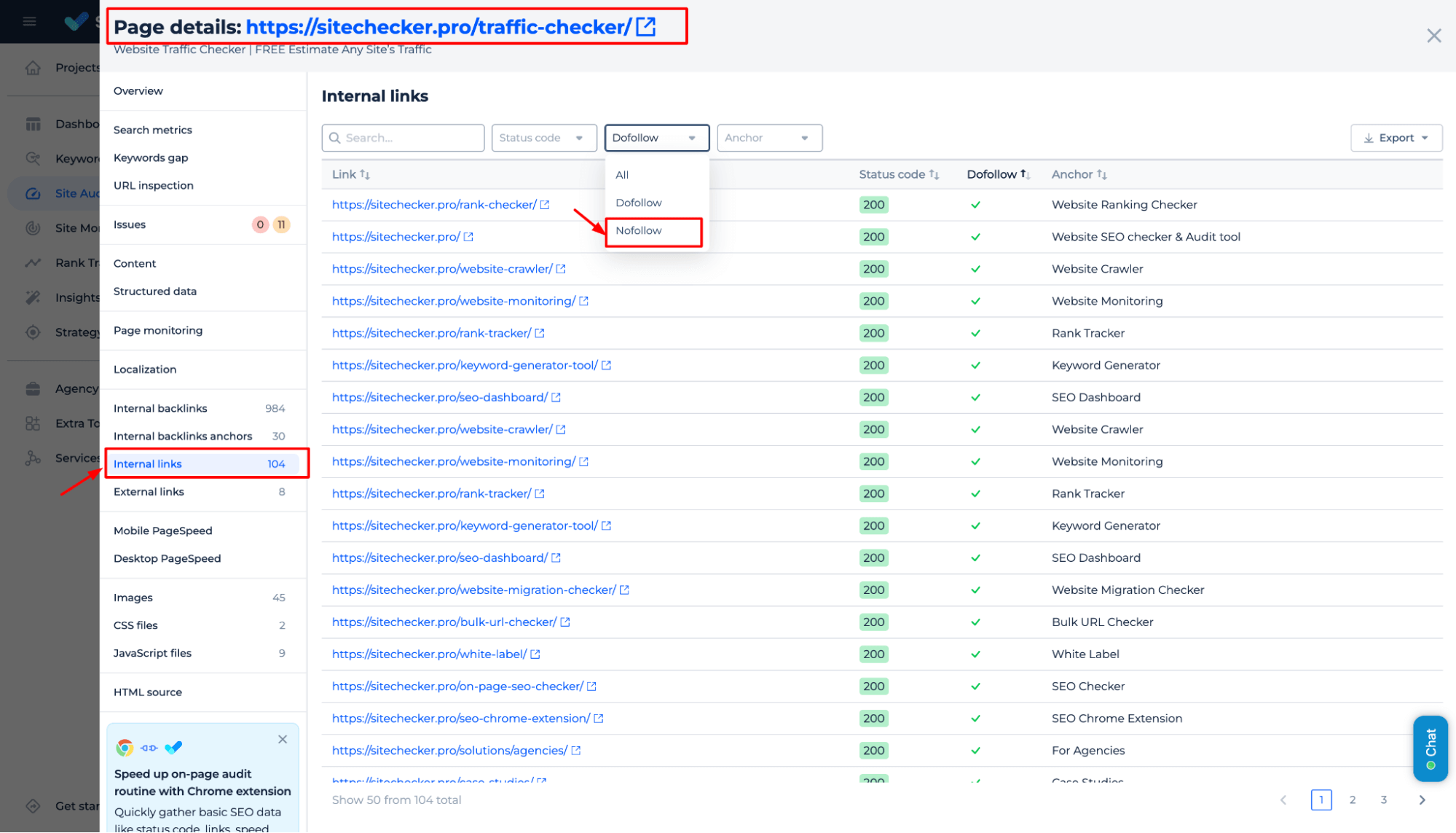
5️⃣ Orphan pages
Lastly, orphan pages – those that aren’t linked to from anywhere on your site – can also be missed out on being crawled. Make sure every critical page is easily accessible through internal linking.
Fixing these issues will help optimize your crawl budget, ensuring Googlebot focuses on your most important pages, leading to faster and more efficient indexing.
Evaluating your content quality for better performance
If your pages aren’t getting indexed, it could be because your content isn’t up to par. Google’s algorithms prioritize high-quality, relevant, and engaging content; if yours falls short, it will likely stay in the “discovered, currently not indexed” zone.
Start by asking yourself: Is your content unique? If it’s too similar to what’s already out there, Google might not bother indexing it. Original, fresh insights have a better chance of catching Google’s eye.
The content should be expert and trustworthy and reflect real-world experience. This makes it even more critical for content to be unique, valuable and well-researched to perform well in Google’s search results.
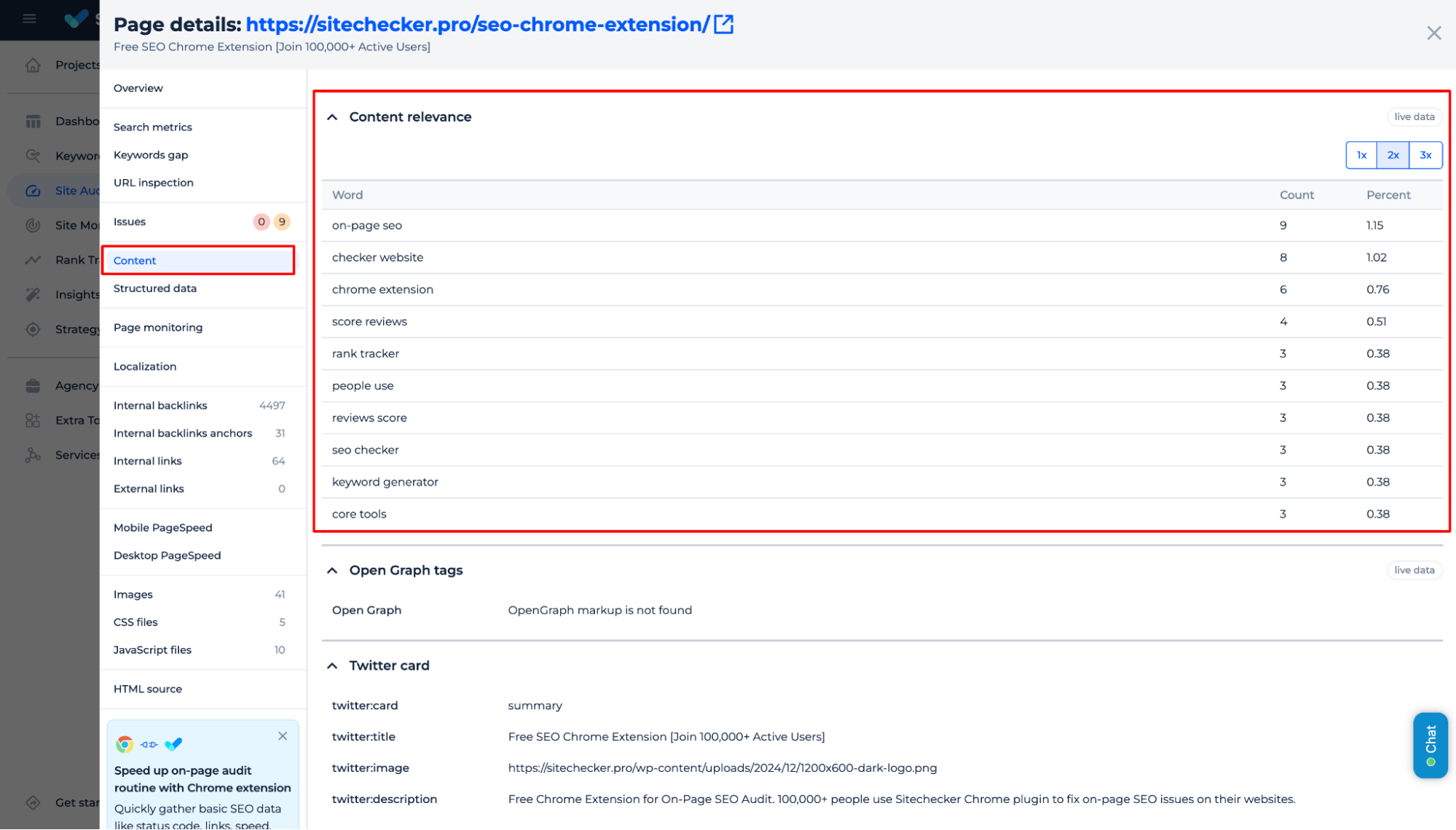
Another factor to consider is relevance. Does your content meet the needs of your audience? Is it answering the questions that matter most?
Pages that offer no real value or solve problems tend to be overlooked by Google.
Finally, readability plays a significant role. Content that is poorly written or hard to navigate can turn users away and send negative signals to Google.
Make sure your writing is clear, concise, and easy to digest. High-quality, user-friendly content is more likely to be indexed and rank well.
Internal linking and its full potential maximization
Internal linking is a key SEO tactic that helps Googlebot discover and index your pages. To optimize it, link to your most essential pages from relevant content, guiding Google to your top content.
Avoid over-optimizing with too many links or exact-match anchor text, as this can appear spammy.
Ensure orphan pages have internal links and audit your links regularly to fix broken ones. Proper internal linking improves indexing and enhances site navigation for users and search engines.
Mobile-friendliness & user experience
Google prioritizes mobile-first indexing, so ensure your site is responsive and loads well on mobile. Use the Mobile-friendly test tool to check for issues.
A smooth user experience (UX) is key – ensure fast loading times (under 3 seconds) and easy navigation. Optimize your mobile site to improve indexing, rankings, and user engagement.
Google’s ability to crawl your content and ensure accessibility
If Google can’t crawl your content, it can’t index it. Crawlability issues often cause pages to remain in the “discovered, currently not indexed” state. To fix this, review your robots.txt file to ensure essential pages aren’t blocked.
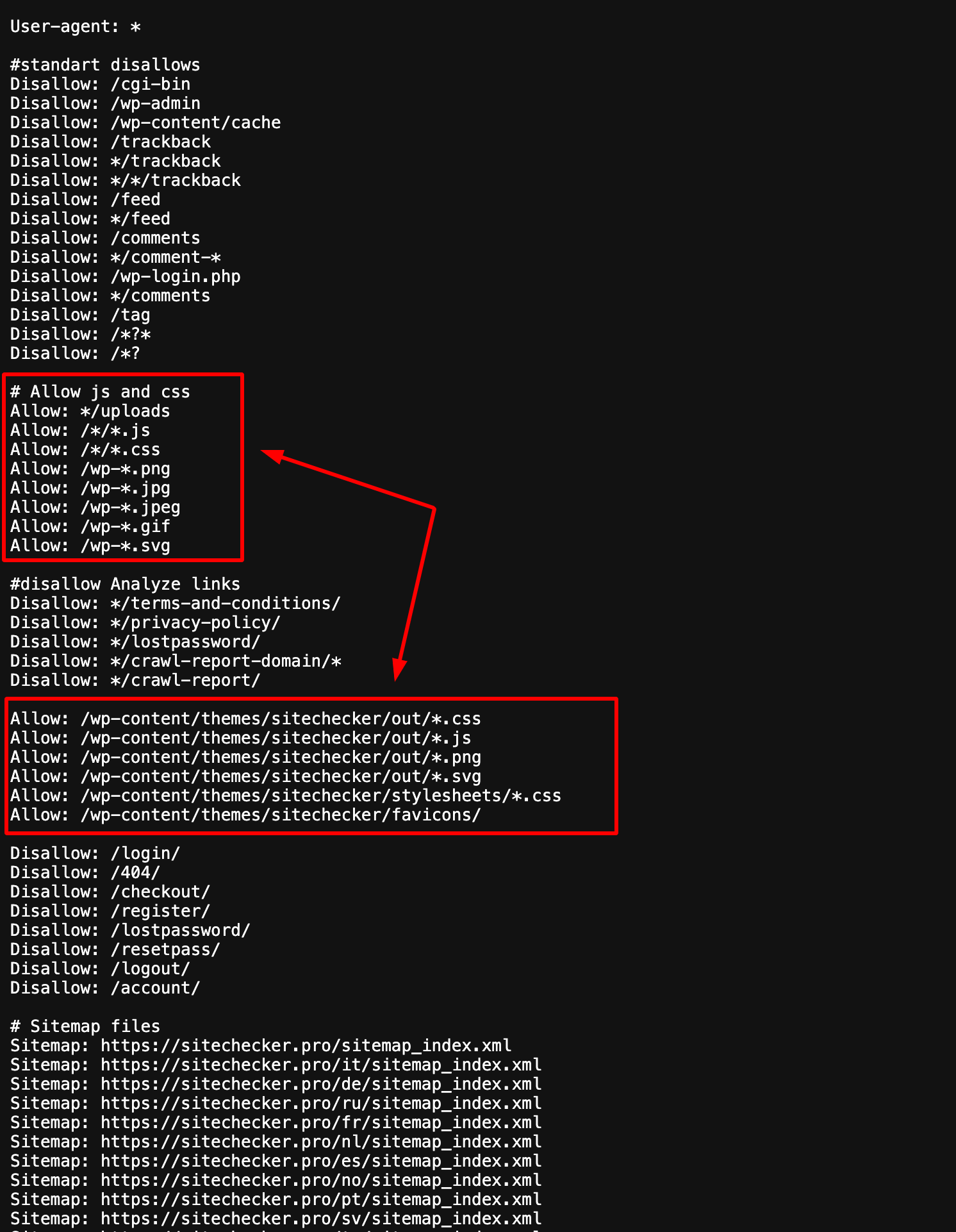
Use Sitechecker to identify crawl errors and resolve them.
Fixing these issues will improve crawlability and help Google index your content quickly.
Make it easy for Google to understand you with structured data
Structured data helps Google understand your content by providing context through schema markup. This makes it easier for Google to index your content and display it in rich results, boosting visibility and click-through rates.
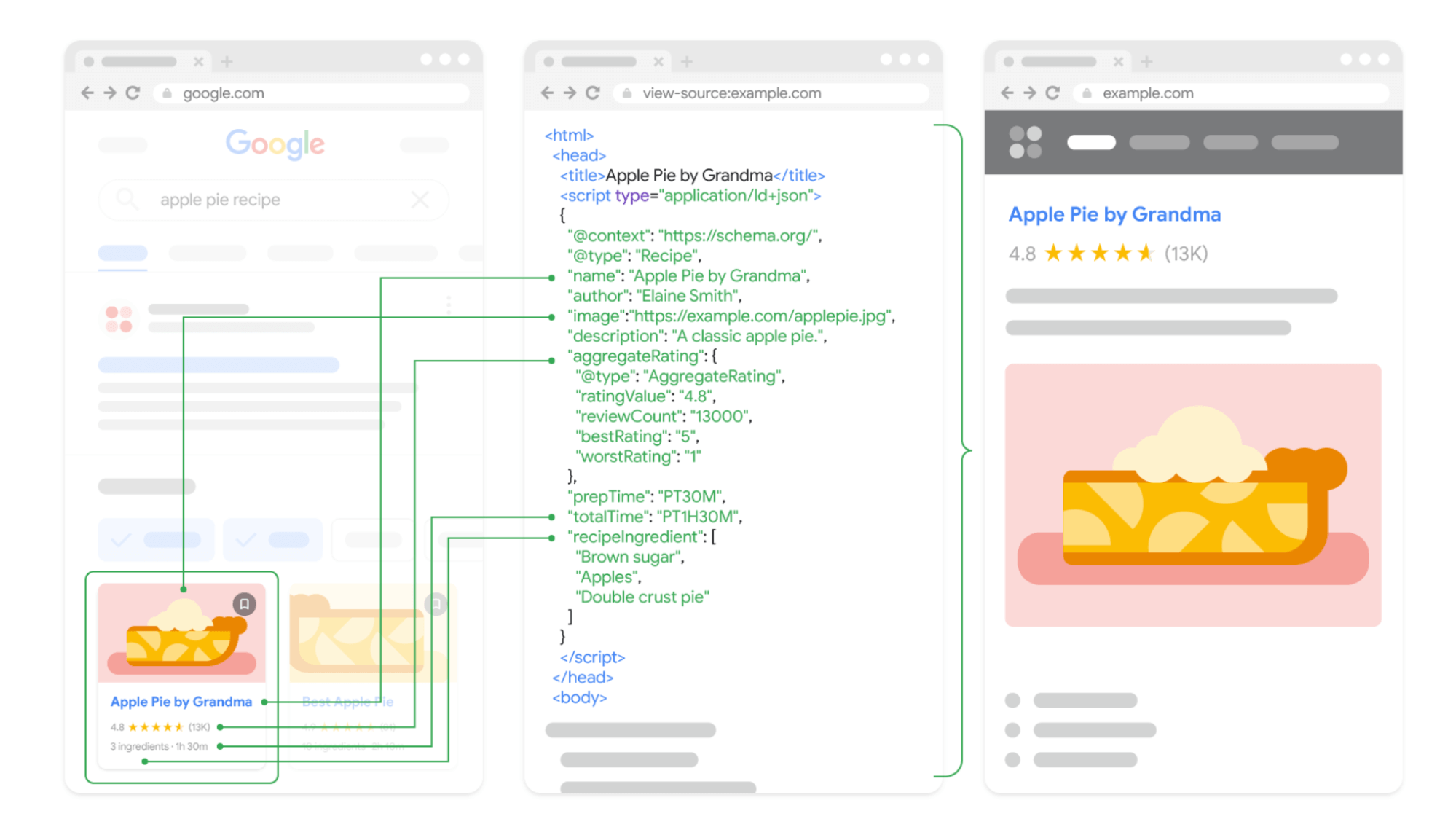
Start using schema.org markup for key pages, like articles, products, or reviews. Use tools like the Structured Data Testing Tool to ensure correct markup.
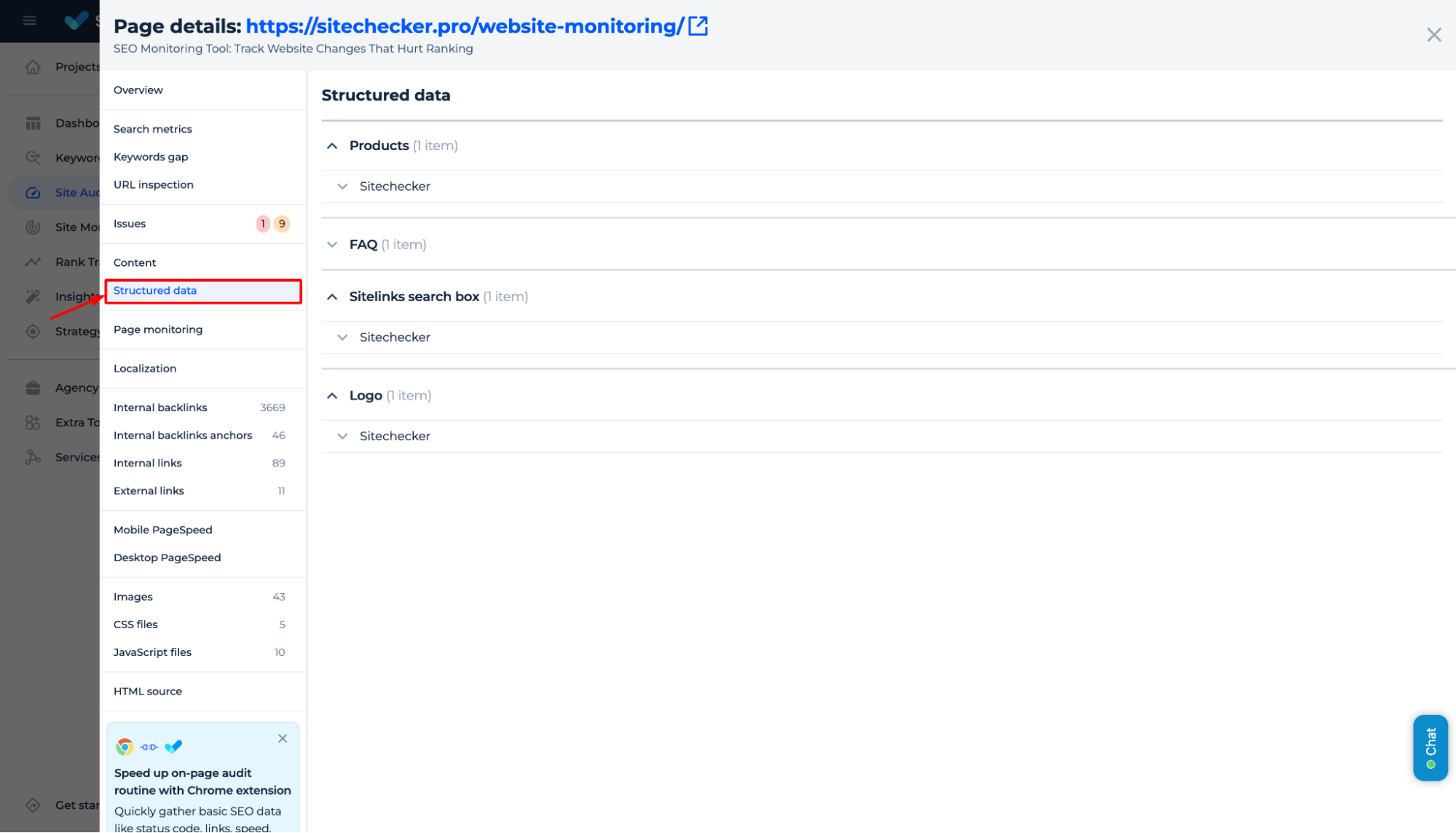
Monitor the performance of your structured data in Google Search Console to spot errors.
Properly implemented structured data enhances indexing and visibility, so don’t skip this step!
How long should you wait before checking back?
Patience is key when it comes to indexing. After making changes, wait 3-5 days before checking back. Google needs time to crawl, index, and process updates. If the page still shows as “discovered, currently not indexed,” review your updates and check for any remaining issues.
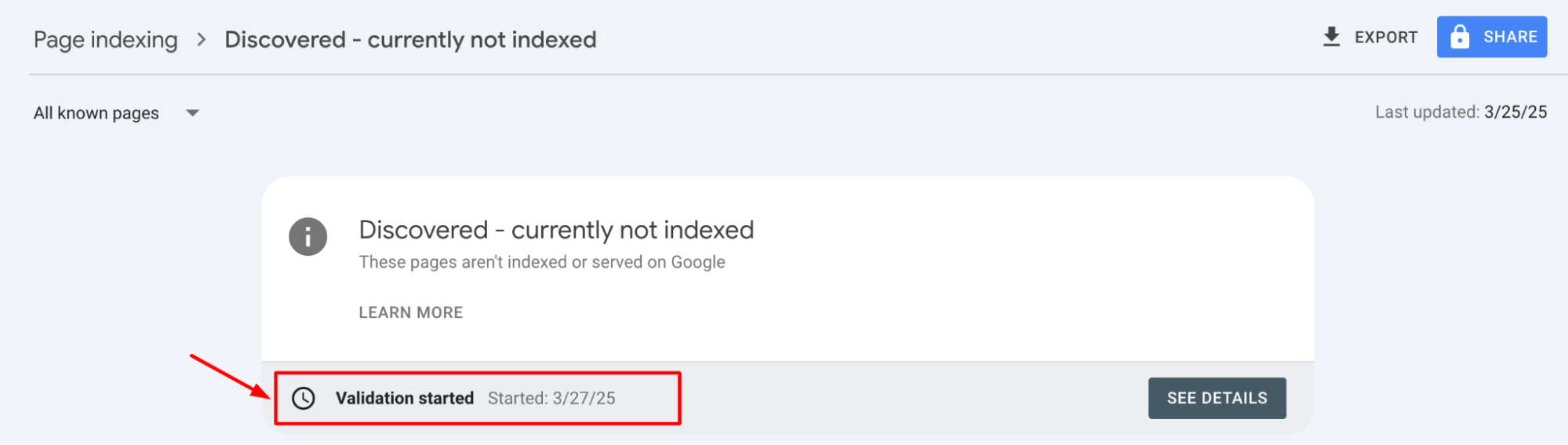
It may take longer for more significant sites or during high-demand periods, so monitor and adjust.
Final idea
To fix “Discovered – Currently Not Indexed,” request indexing in Google Search Console. Check for crawl budget issues, subdomain mismanagement, robots.txt errors, redirects, duplicate content, internal nofollow links, and orphan pages.
Ensure content is unique and relevant. Regularly audit internal links, improve mobile-friendliness, and use structured data. Wait 3-5 days for updates. Avoid common mistakes and keep your site optimized for better indexing.





