



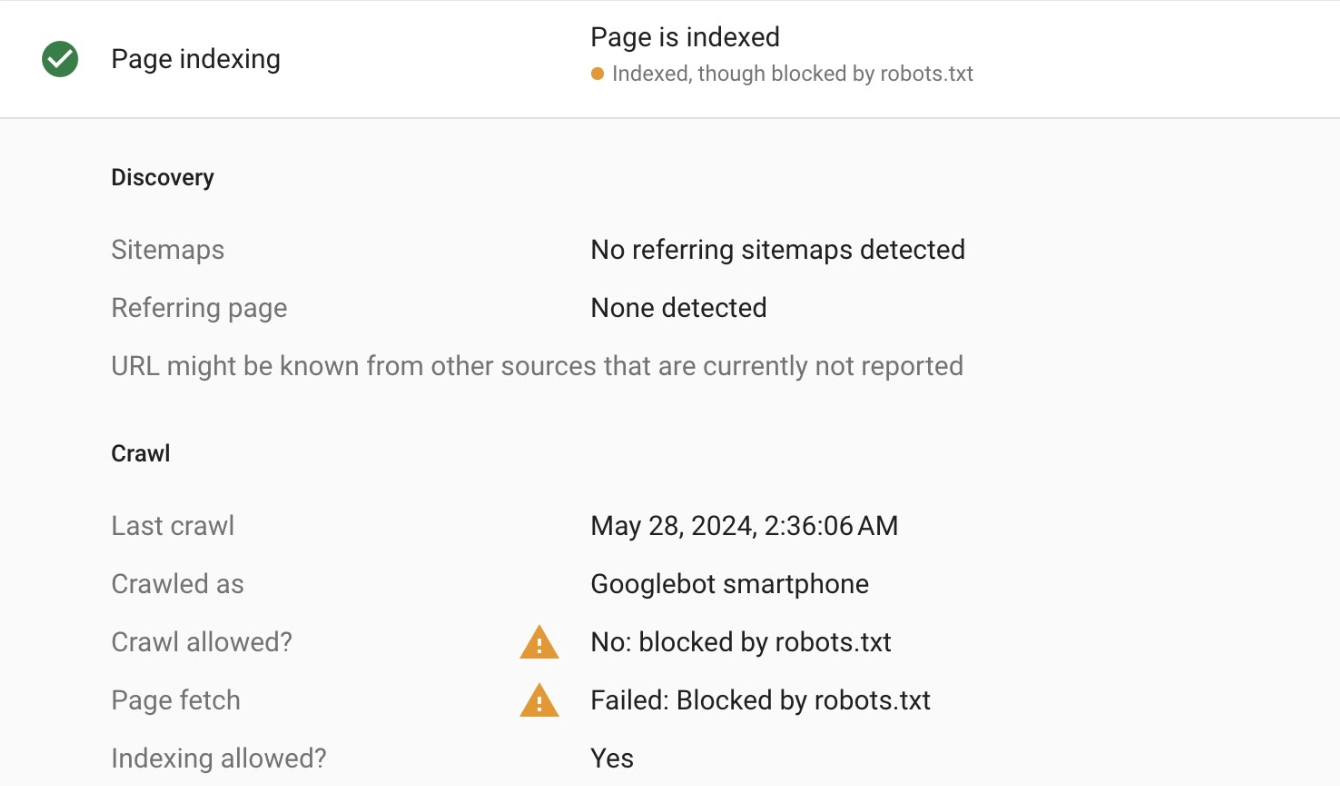
What does ‘Indexed, though blocked by robots.txt’ mean?
When you block a page with robots.txt, you tell search engines not to crawl it. But what if it still shows up in search results? That’s the issue of “Indexed, though blocked by robots.txt.”
Launch Sitechecker’s GSC Dashboard to boost your Search Console reporting!
Expand GSC Data Limits
Bypass Google’s 1,000-row cap and unlock up to 36 months of Search Console history in a single dashboard.
Why does this happen?
There are several reasons why Google might index a page even though it’s blocked by robots.txt:
| Reason | Description |
|---|---|
| Conflicting directives | Google may be receiving mixed signals. If there are other instructions like meta tags (noindex) or HTTP headers telling Google something different from robots.txt, it can confuse the system about whether to index the page. |
| Google’s interpretation | Sometimes, Google’s algorithms determine that a blocked page holds valuable content and should be indexed, even if it’s blocked by robots.txt. Google’s main goal is to deliver the most relevant search results, so it may override the block if it deems the page important. |
| Crawling vs. indexing | While robots.txt blocks crawling, it doesn’t necessarily stop indexing. Google can still gather information about the page from other sources, such as external links or cached data, which might result in the page being indexed. |
| Caching issues | If Google cached the page before the robots.txt update, it may still appear in search results until the cache is updated. This delay can cause outdated data to appear in search results. |
How to fix ‘Indexed, though blocked’ issues
Here’s how you can resolve the issue of pages being indexed despite being blocked by robots.txt:
1. Modify robots.txt and HTTP Headers
Modify your robots.txt file to ensure it only blocks the pages you intend to exclude from crawling. If a page is still indexed despite being blocked by robots.txt, check for conflicting noindex meta tags or HTTP headers. To resolve the issue, remove the block in robots.txt and add the noindex directive in the meta tag or HTTP header for pages you want to prevent from indexing.
If your robots.txt file is blocking a page that should be indexed, you need to remove the block. Once the block is removed from robots.txt, you should add the noindex directive to prevent the page from being indexed. This can be done using the HTTP header or meta tag:
<!-- robots.txt -->
User-agent: *
Allow: /example-page/
<!-- HTML Meta Tag -->
<head>
<meta name="robots" content="index, follow">
</head>
2. Check for meta tags or HTTP headers
Ensure there are no conflicting meta tags (like noindex) or HTTP headers telling Google to index or follow a page when robots.txt has blocked it. If these signals conflict, they could lead to inconsistent indexing behavior.
You can use HTTP Header Checker to ensure no conflicting meta tags or HTTP headers could cause indexability issues. The tool helps identify any mismatched directives, such as noindex or nofollow, that may be interfering with your robots.txt settings.
Fix Google’s indexing confusion with robots.txt
Check for indexability issues and ensure your pages appear correctly in search results.
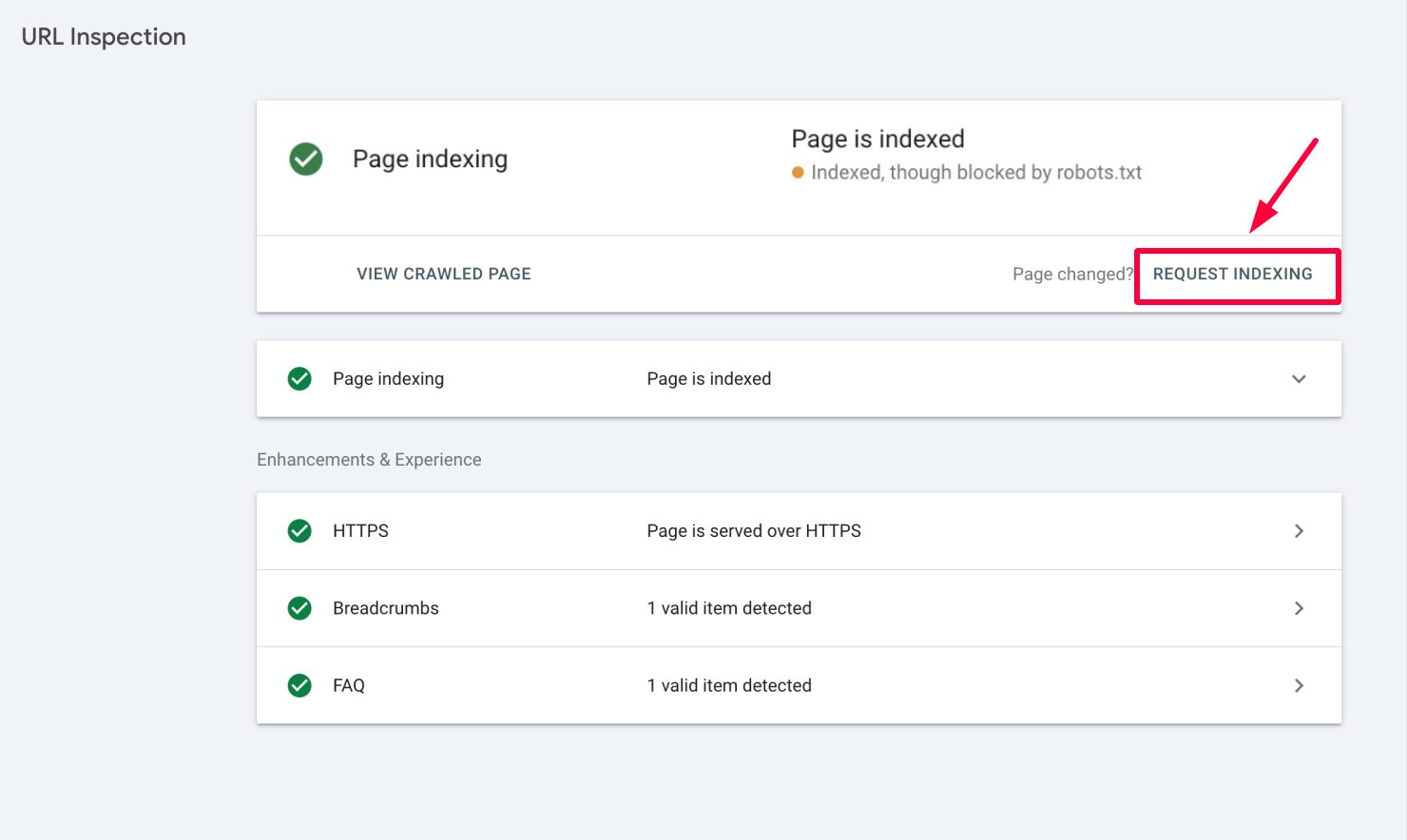
3. Use Google Search Console
Use the Page Indexing section in GSC to check the status of pages that have been indexed despite being blocked:
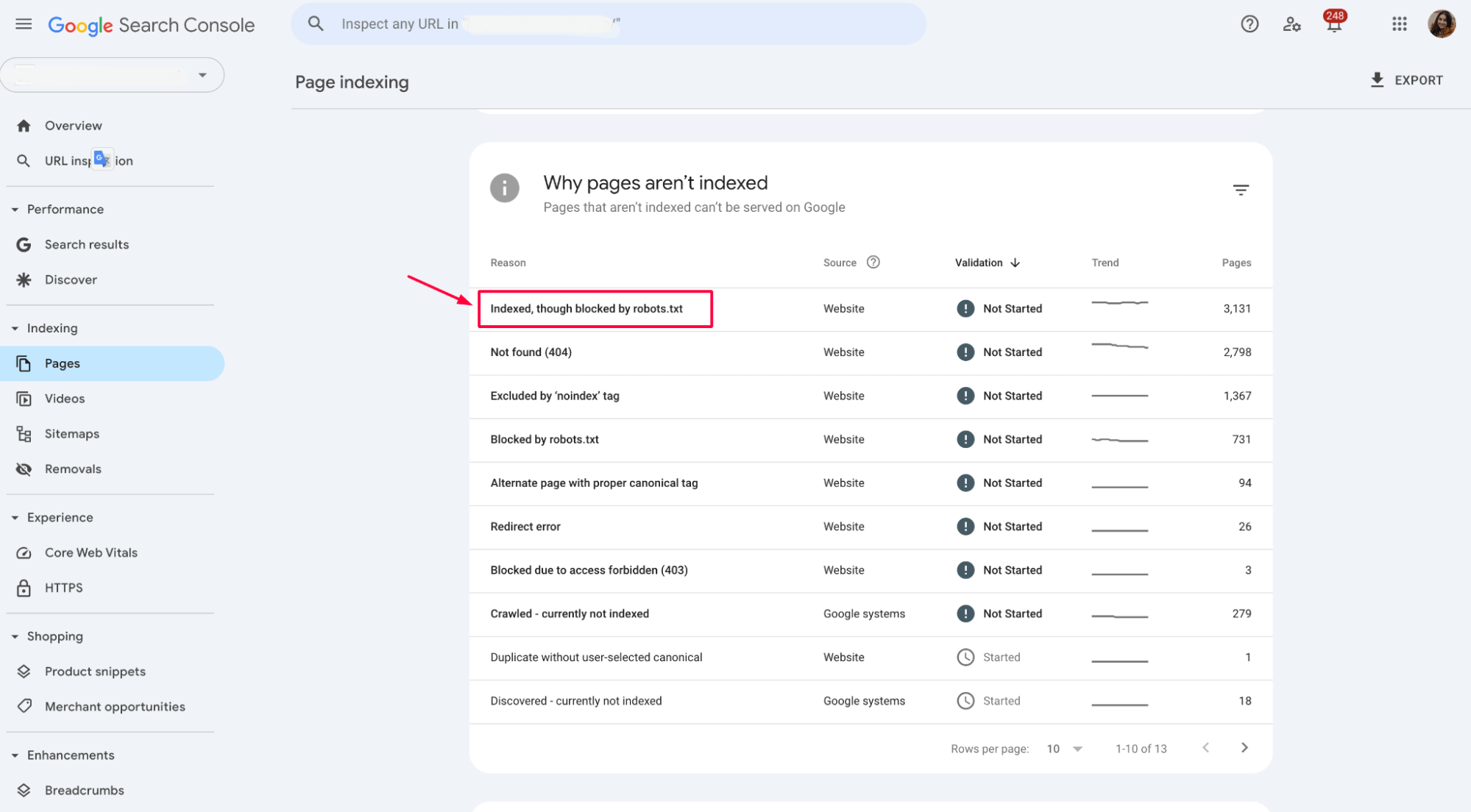
In this case, click on the pages flagged with the “Indexed, though blocked by robots.txt” issue and make any necessary adjustments to your sitemap or robots.txt file. Ensure the correct pages are included or excluded from indexing depending on your SEO strategy.
Submit an updated sitemap through Google Search Console to ensure Google has the latest information about your site’s structure:
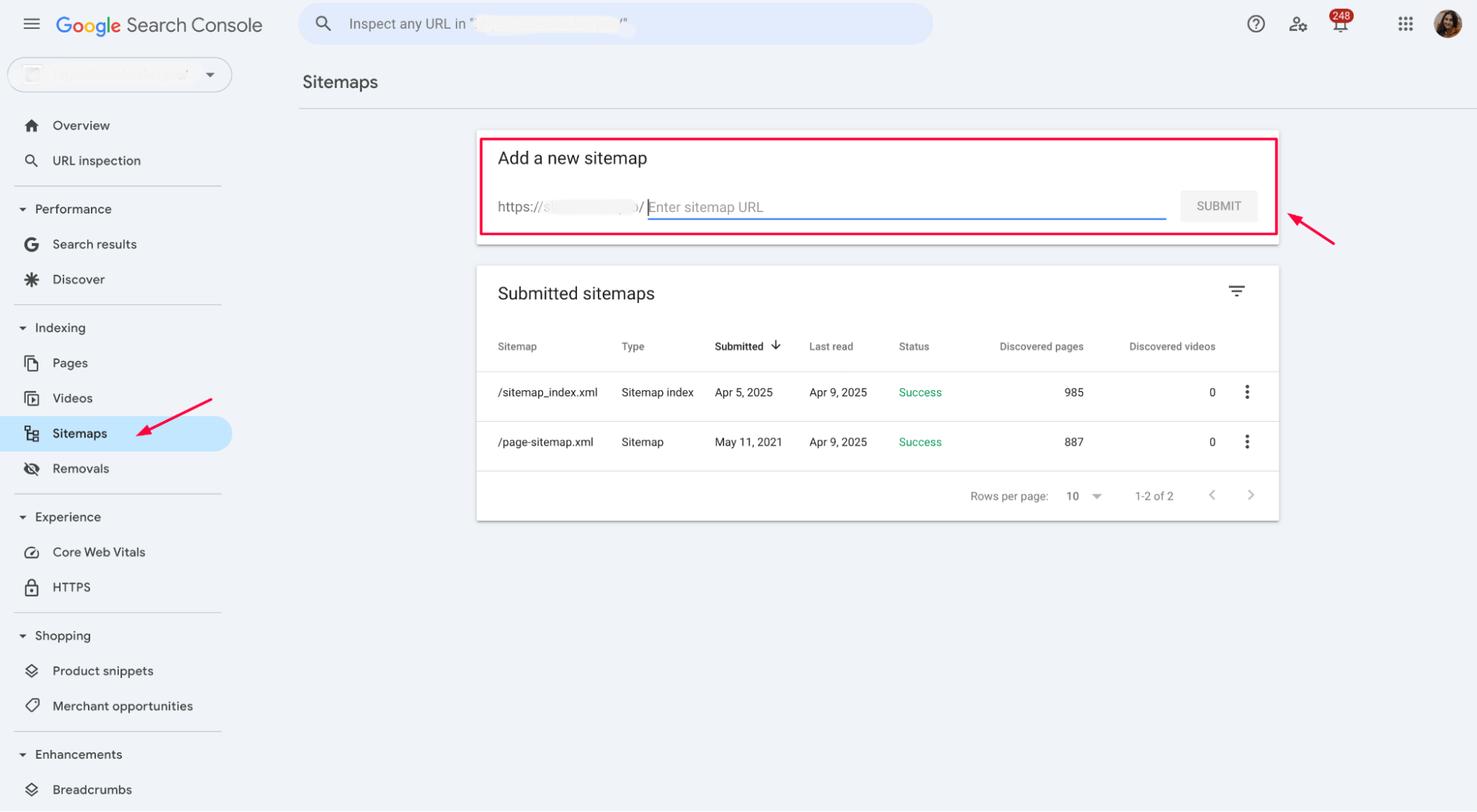
After updating robots.txt or any conflicting directives, use Google Search Console’s “Request indexing” feature to prompt Google to revisit your pages and update its index.
Preventing future issues
To keep your site running smoothly and avoid the “Indexed, though blocked by robots.txt” problem down the road, follow these simple steps:
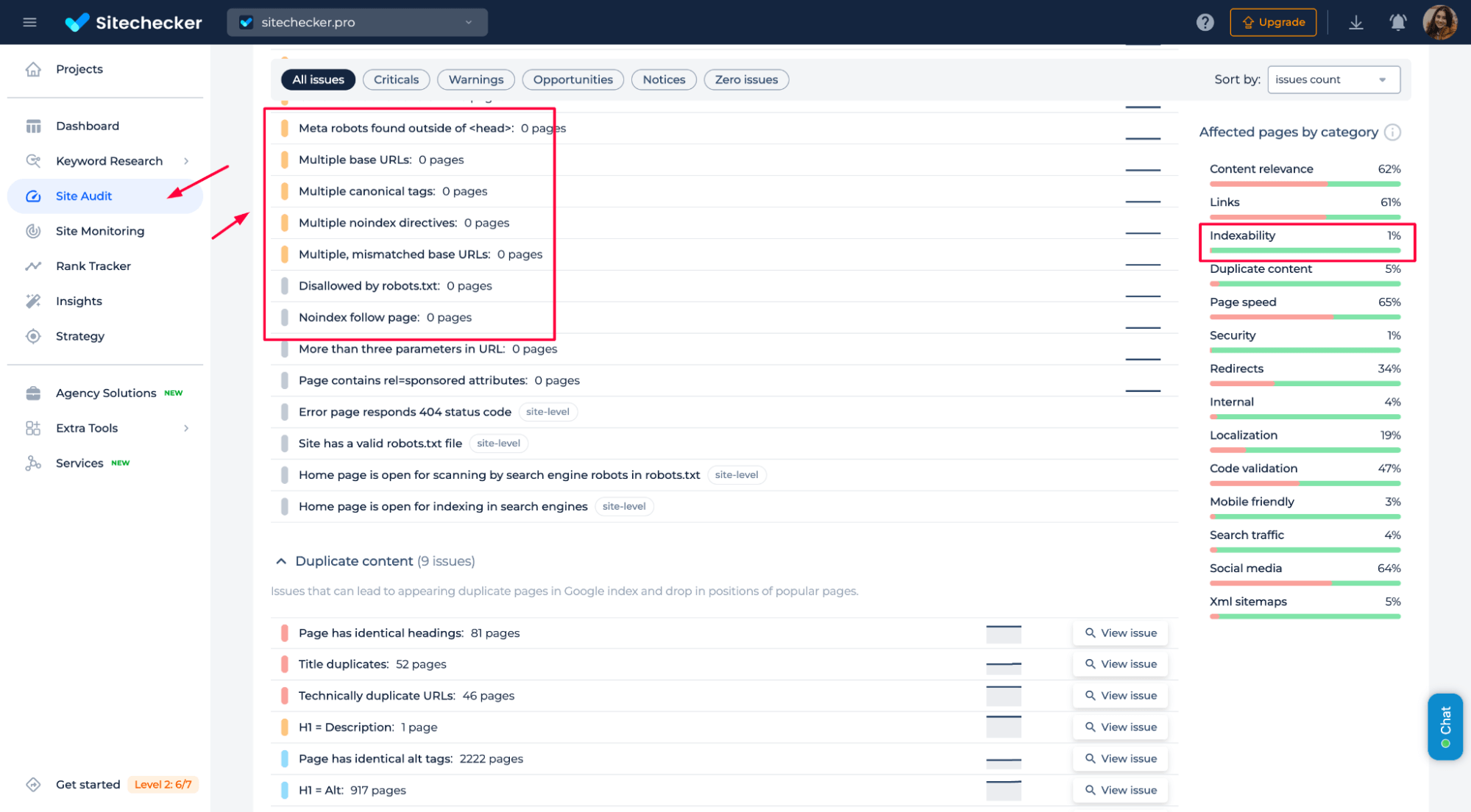
1. Regularly check your indexability
If something looks off, catching and fixing it early is easier. Also, don’t forget to test your robots.txt occasionally – things change, and you’ll want to ensure it reflects your current SEO strategy.
2. Streamline your content management to avoid conflicting instructions
A noindex tag here or a rogue meta tag there can mess things up. Stick to one clear directive and ensure it aligns with what you want Google to do. Less confusion means fewer headaches.
Regarding robots.txt, make sure you’re blocking what needs to be blocked, but don’t forget that blocking crawlers doesn’t stop indexing if other signals (like backlinks) are available.
<!-- robots.txt -->
User-agent: *
Disallow: /example-page/
<!-- HTML Meta Tag -->
<head>
<meta name="robots" content="noindex, follow">
</head>
Watch the video below to ensure you fully understand how to configure your robots.txt and avoid conflicts with other directives. It explains how robots.txt works and how to properly manage crawling and indexing instructions for your site:
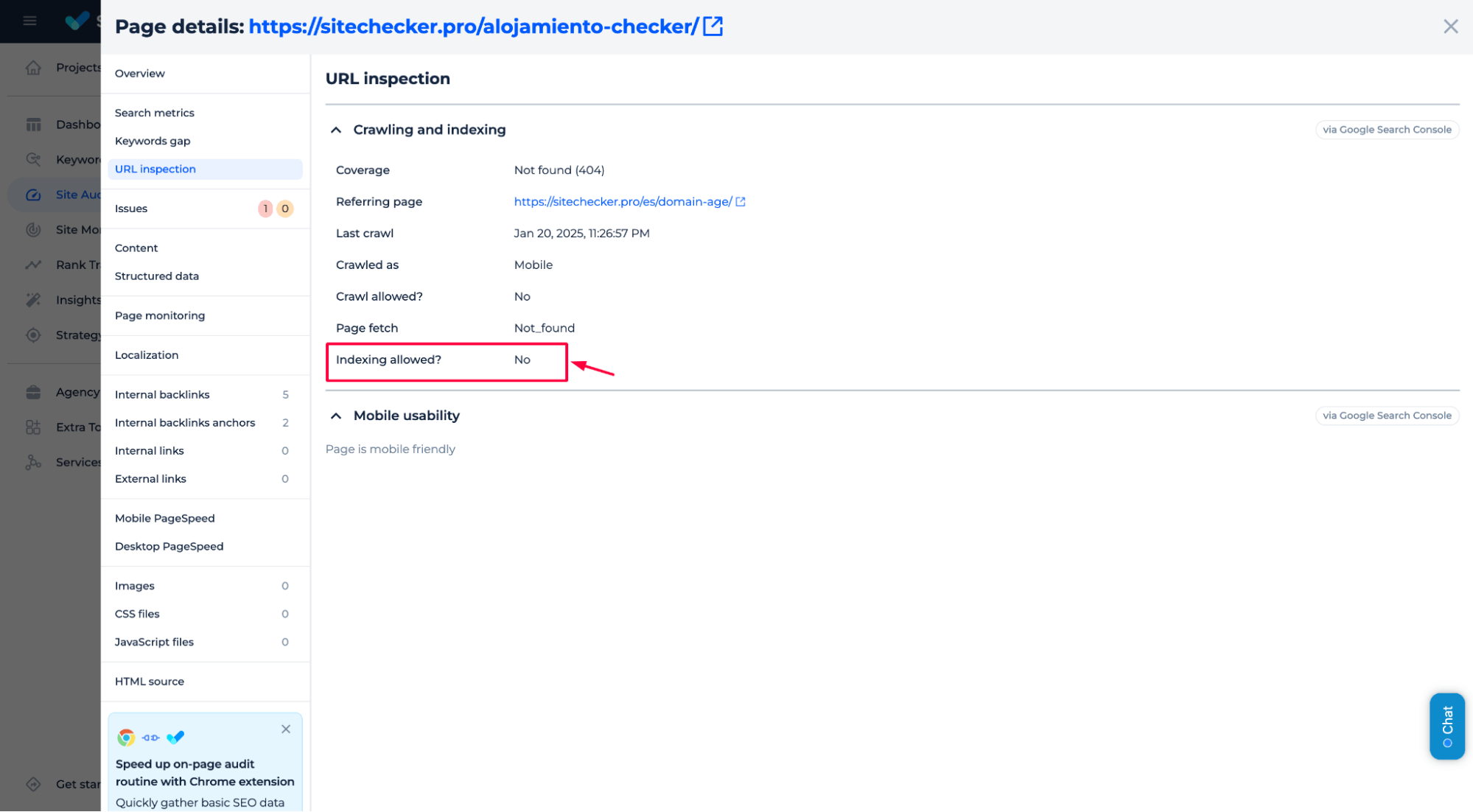
3. Test before you implement any changes
Sitechecker URL Inspection feature is a great way to double-check that your site’s behavior is exactly how you want it to be.
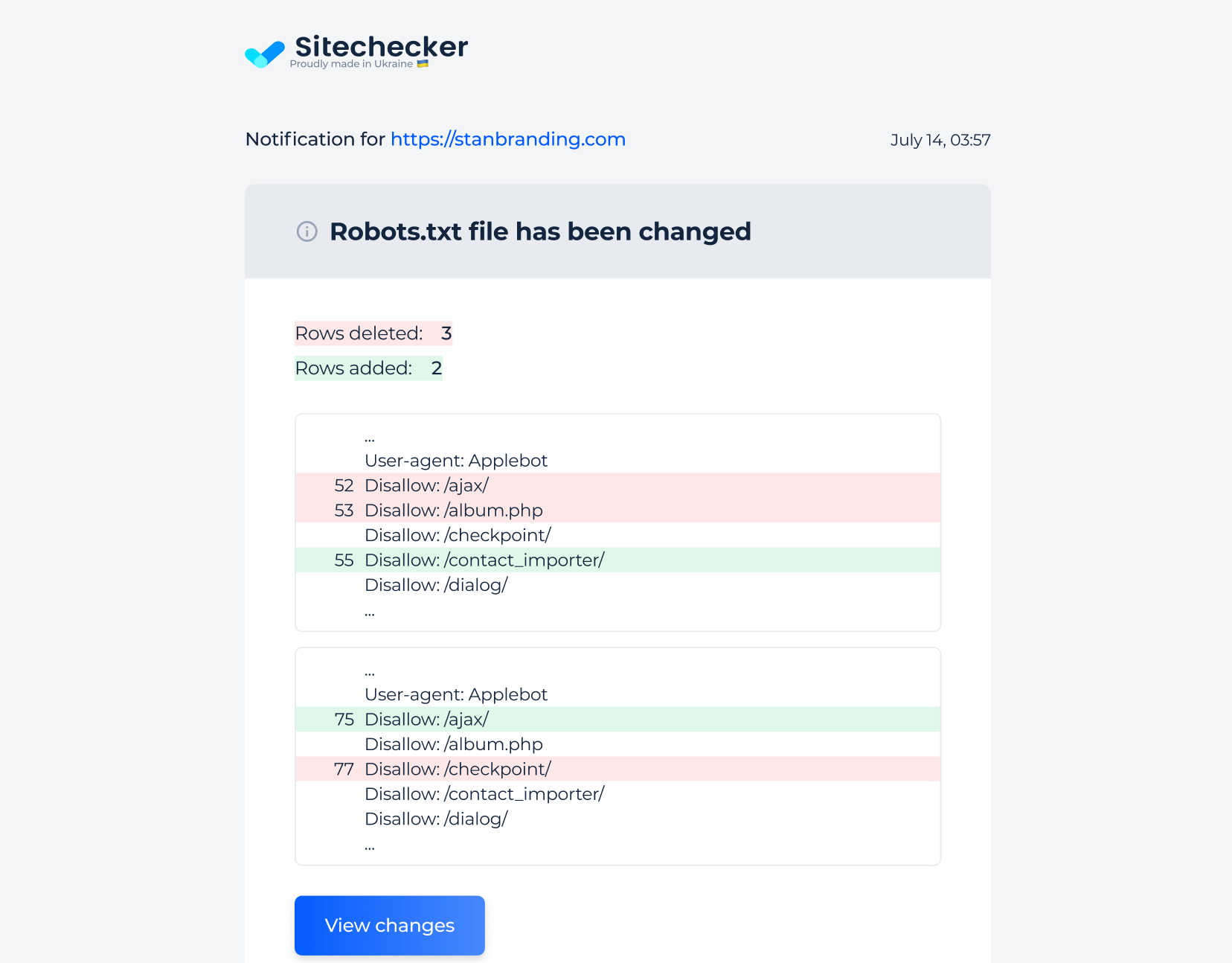
4. Set up alerts
We recommend setting up alerts for changes in your robots.txt file to detect discrepancies promptly and ensure your SEO strategy remains aligned.
You can also set up alerts for changes in HTTP headers. Enabling this option will notify you whenever HTTP headers are modified:
This can help you track any unintended changes that might affect your SEO or indexing, such as adding or removing new noindex or nofollow directives.
Final idea
The issue of “Indexed, though blocked by robots.txt” occurs when Google indexes a page without being instructed to crawl it via the robots.txt file. This can happen due to conflicting directives, Google’s algorithmic interpretation, the difference between crawling and indexing, or caching issues. To resolve this, ensure proper implementation of robots.txt, check for conflicting meta tags or HTTP headers, and use Google Search Console’s tools to inspect and recrawl affected pages.
Monitor your indexability regularly, review robots.txt for accuracy, and set up alerts for changes to prevent future issues and ensure your SEO strategy is effective.





