



What Does the Issue Mean?
Technically duplicate pages refer to web pages nearly identical in content but available through different URLs. These pages may not be intentionally duplicated but result from technical issues, such as different URL parameters, session IDs, or slight variations in the URLs (e.g., with or without “www,” using HTTP vs. HTTPS, or having different query strings). Here are some common scenarios leading to technically duplicate pages:
1. URL Parameters: Pages that have the same main content but different URL parameters, like tracking codes or session IDs.
example.com/page?sessionid=123 and example.com/page?sessionid=456
2. WWW vs. Non-WWW: The same content is accessible via both www.example.com and example.com.
www.example.com/page and example.com/page
3. HTTP vs. HTTPS: The same content is accessible via both HTTP and HTTPS protocols.
http://example.com/page and https://example.com/page
4. Trailing Slashes: URLs with and without a trailing slash can serve the same content.
example.com/page and example.com/page/
5. Capitalization: URLs differing only in capitalization can serve the same content.
example.com/Page and example.com/page
6. Mobile vs. Desktop Versions: Separate URLs for mobile and desktop versions of the same content.
m.example.com/page and example.com/page
7. Printer-Friendly Versions: Printer-friendly URLs that duplicate the main content.
example.com/page and example.com/page?print=true
These technical duplications can confuse search engines and lead to issues like diluted link equity and split ranking signals, which can harm a site’s SEO performance. To mitigate these issues, webmasters often use canonical tags, 301 redirects, or settings in the robots.txt file to consolidate and indicate the preferred version of a page.
How to Check the Issue?
In the Sitechecker SEO tool, under the category “Duplicate content,” you will find a specific section for “Technically duplicate URLs,” which identifies pages on your website that might differ in URL structure but contain identical or very similar content. This particular analysis helps to pinpoint technical discrepancies that might confuse search engines, thereby potentially harming your site’s SEO performance.
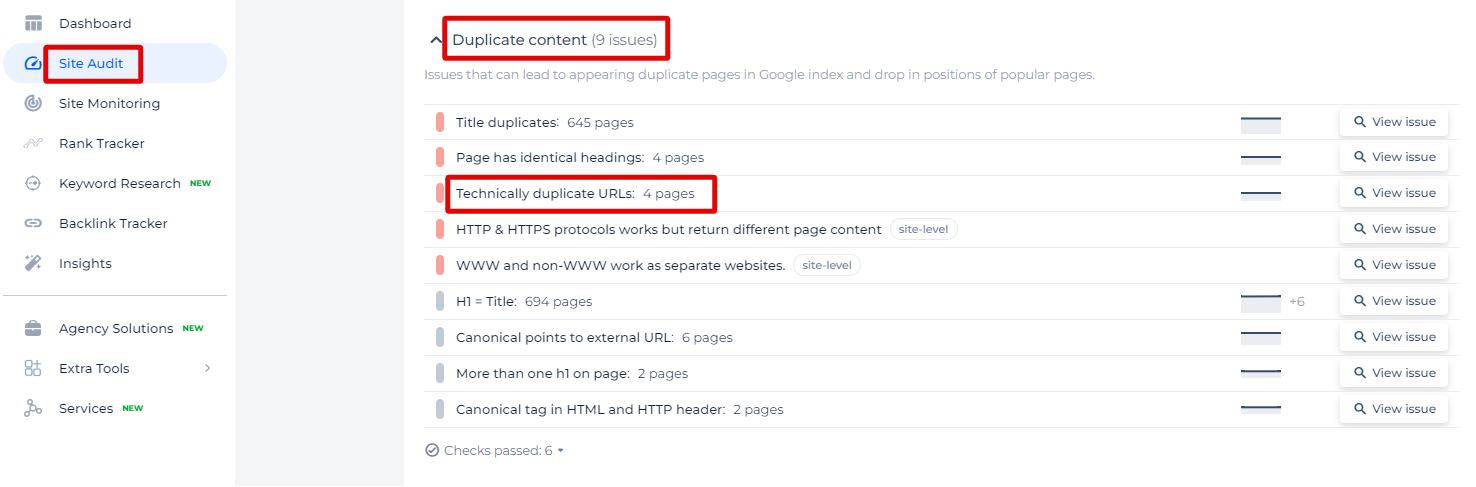
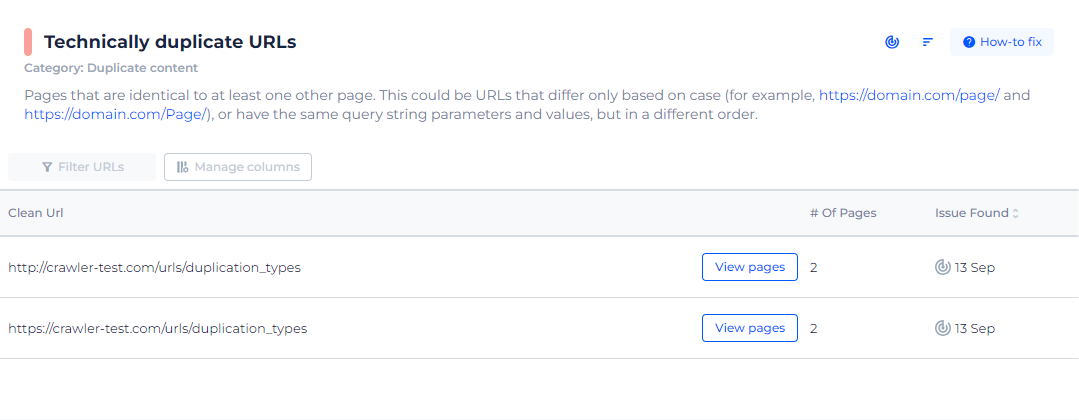
By clicking on the “View issue” link next to the “Technically duplicate URLs” section, users are provided with a detailed list of pages that are affected by this issue. The interface clearly displays each problematic URL, allowing for an easy review and subsequent optimization.
Detect Duplicate Page Issues Instantly
Spot and fix technically duplicate URLs with our powerful Site Audit Tool to enhance your website’s SEO performance.
How to Fix the Issue?
To fix the issue of technically duplicate URLs, you can employ several strategies to ensure that search engines understand which version of the page should be considered the authoritative one. Here are the steps you can take:
1. Canonical Tags
Add a <link rel=”canonical” href=”URL”> tag in the HTML <head> section of each page. This tag tells search engines which version of a URL is the preferred one.
<link rel="canonical" href="https://example.com/page">
2. 301 Redirects
Implement 301 redirects to permanently redirect traffic from duplicate pages to the canonical version. This is especially useful for consolidating duplicate content caused by different URLs.
Redirect http://example.com/page to https://example.com/page
3. Consistent Linking
Ensure all internal links point to the canonical version of the URL. This helps search engines and users consistently access the preferred version of your pages.
4. URL Parameter Handling
Use Google Search Console’s URL parameter tool to specify how different parameters should be handled by search engines. This helps prevent indexing of duplicate content caused by URL parameters.
5. robots.txt and Meta Robots Tag
Use the robots.txt file to disallow search engines from crawling duplicate URLs if they are not necessary for indexing.
User-agent: *
Disallow: /print/
Alternatively, use the <meta name=”robots” content=”noindex”> tag in the HTML <head> section of duplicate pages to prevent them from being indexed.
6. Consistent URL Structure
Maintain a consistent URL structure and use lowercase URLs. Ensure that URLs with and without trailing slashes are consistently handled, preferably redirecting one to the other.
Always redirect example.com/page/ to example.com/page or vice versa.
7. HTTPS
Ensure your site uses HTTPS, and implement 301 redirects from HTTP to HTTPS versions of your pages to avoid duplicates caused by protocol differences.
Domain Consolidation:
- Decide whether you want to use www or non-www versions of your domain, and redirect the non-preferred version to the preferred one.
- Example: Redirect www.example.com to example.com or vice versa.
8. Avoid Creating Duplicate Content
Ensure that different site versions (e.g., desktop and mobile) do not create duplicate content. Use responsive design instead of separate URLs for mobile and desktop versions whenever possible.
9. Hreflang for Internationalization
If you have multiple versions of a page for different languages or regions, use the hreflang attribute to indicate the language and regional targeting of each version.
<link rel="alternate" href="https://example.com/page" hreflang="en">
<link rel="alternate" href="https://example.com/page-fr" hreflang="fr">
Implementing these strategies will help search engines correctly identify the preferred version of your pages, improving your site’s SEO and avoiding penalties for duplicate content.





