


What is a Link Extractor?
The link extractor tool serves to grab all links from a website or extract links on a specific webpage, including internal links and internal backlinks, internal backlinks anchors, and external outgoing links for every URL on the site.
What can this tool help you with?
Extraction of All Links: It can grab all links from a website or a specific webpage. This includes both internal links and external outgoing links.
Identifies all anchors linking to the landing page. Discover every anchor link that directs to your landing page.
Detailed Analysis of Internal Links: The tool provides comprehensive data on internal hyperlink addresses, including internal backlinks.
Identification of Link-Related Issues: It helps detect problems on your website, providing an exhaustive list of troublesome URLs.
Continuous Tracking and Monitoring: Offers capabilities for continuous tracking and monitoring of hyperlink addresses, maintaining a log of changes and errors.
General features of Website Links Extractor
Unified Dashboard: Provides a centralized platform where you can access and manage all SEO tools and data. This dashboard presents a comprehensive view of your website’s SEO performance, making it easier to monitor and analyze key metrics.
User-Friendly Interface: The interface is designed to be intuitive and easy to navigate, even for those who are not experts in SEO. This user-friendliness ensures users can effectively utilize all the features without a steep learning curve.
Complete SEO Toolset: Sitechecker offers a full range of SEO tools, covering various aspects such as site auditing, rank tracking, backlink checking, and more. This complete toolset allows for a thorough and integrated approach to managing and improving your website’s SEO.
How to Use the Tool
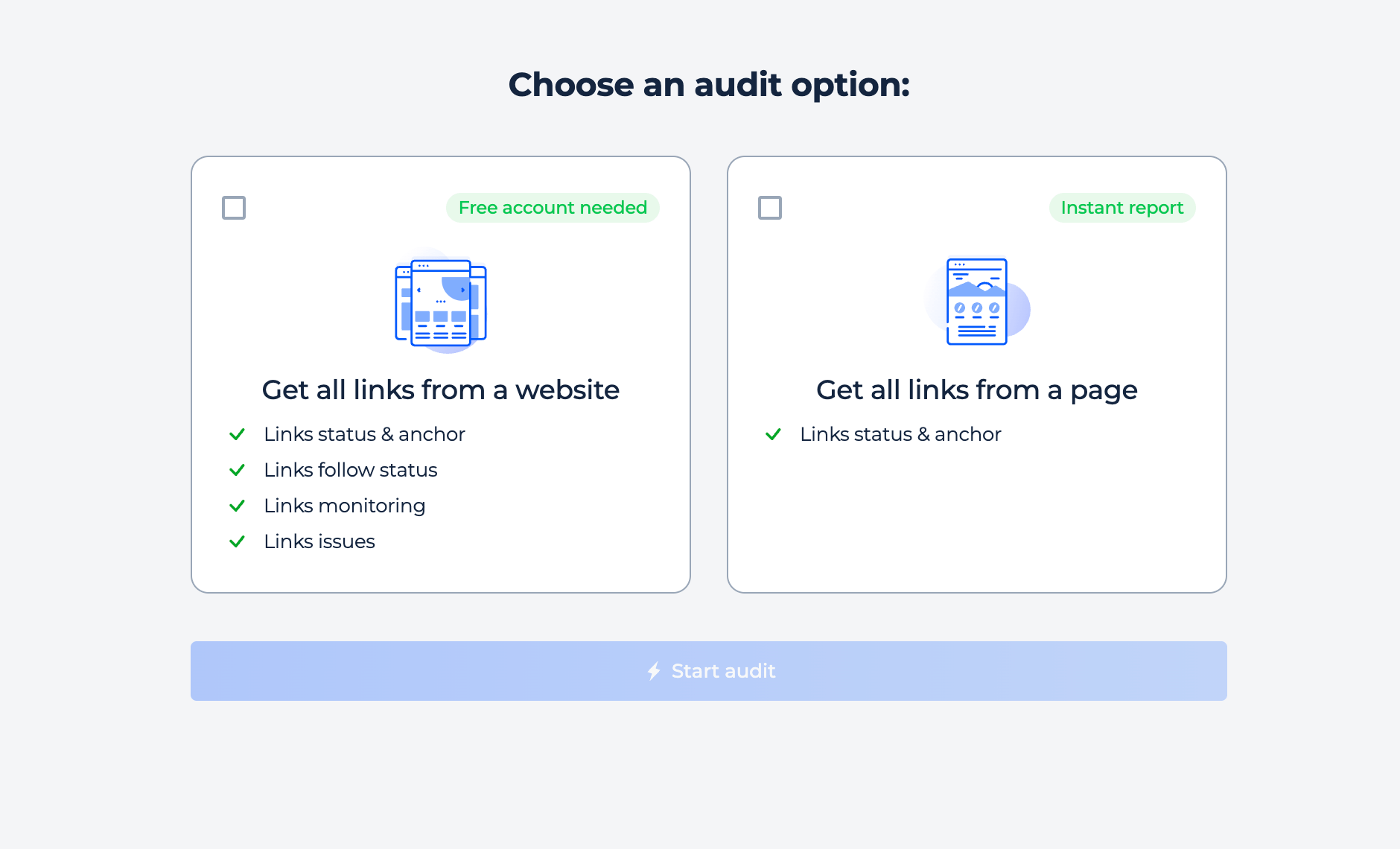
For link extraction, choose the domain method to analyze all links on a website (requires an account and free trial), or select the single-page method for detailed information on a specific page (available with 1-click, free of charge). Enter your domain or URL and click “Get all links” to start. Once ready, the tool begins scraping the site data.
Domain Check
Step 1: Choose the domain option, enter the domain you want to analyze, and click the “Get all links” button
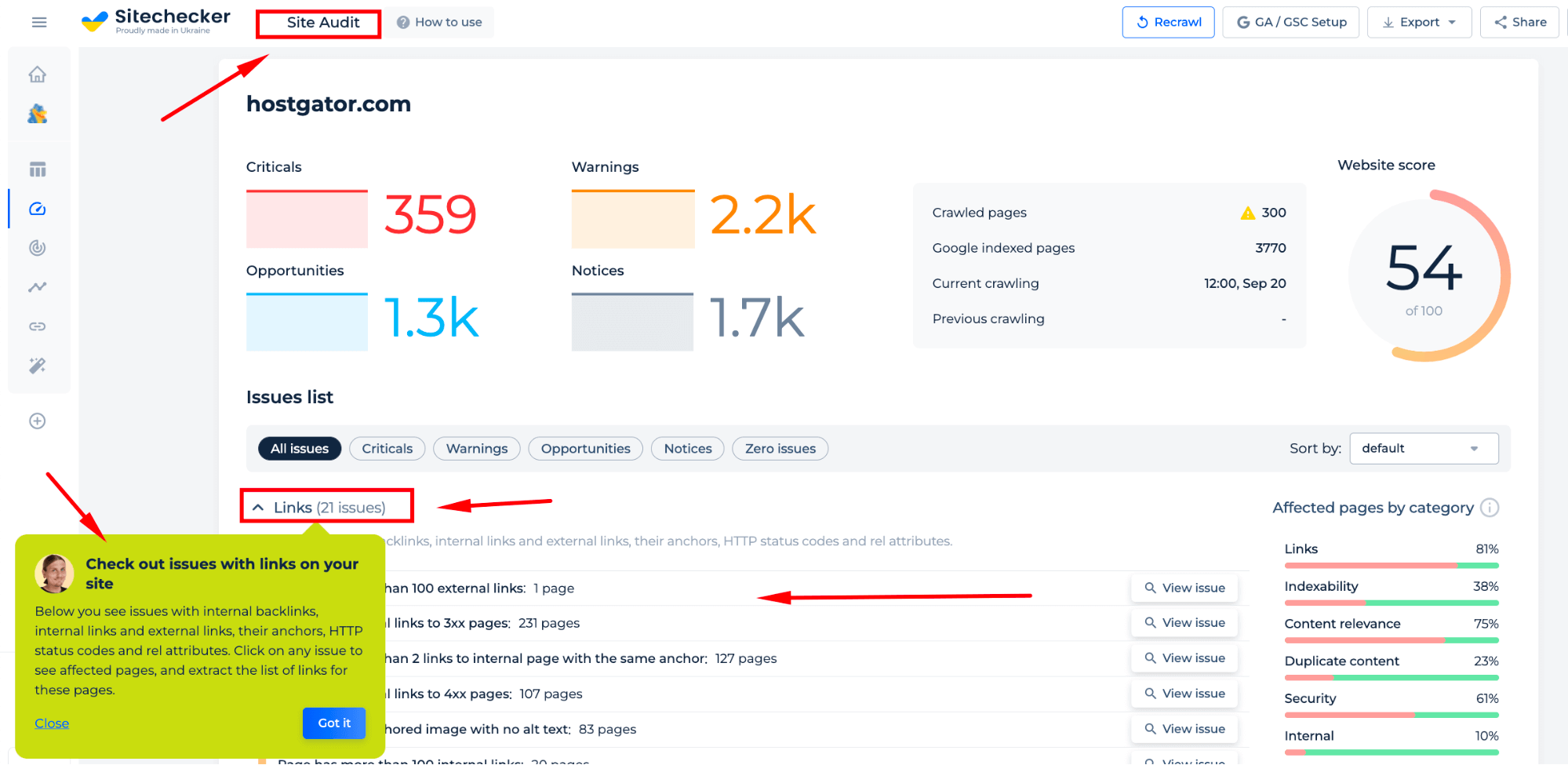
Step 2: Interpreting the domain link extractor results via domain check
The scan you perform will generate a site audit for the domain you enter, revealing various issues with links, such as backlinks, internal and external URLs, their anchors, HTTP status codes, and rel attributes. By clicking on any given issue, you can see which pages are affected and extract a list of references for those pages. This way, easily identify and resolve any possible problems.
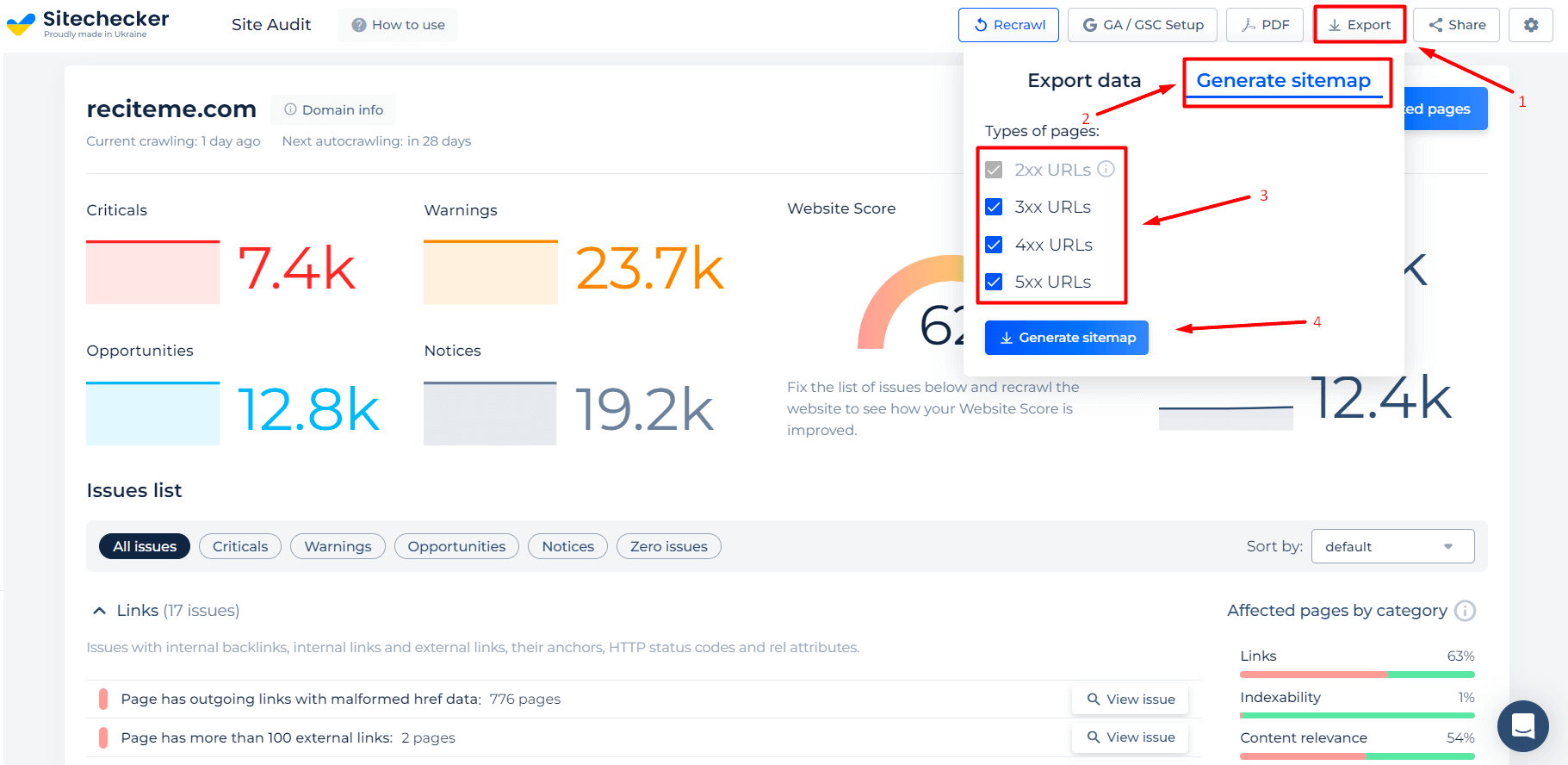
Do you want to extract all URLs from a website to get a comprehensive list for sitemap creation? We’ve already done this for you. You can download the sitemap generated from the URLs that our SEO checker has previously crawled.
Additional features of the website link extractor
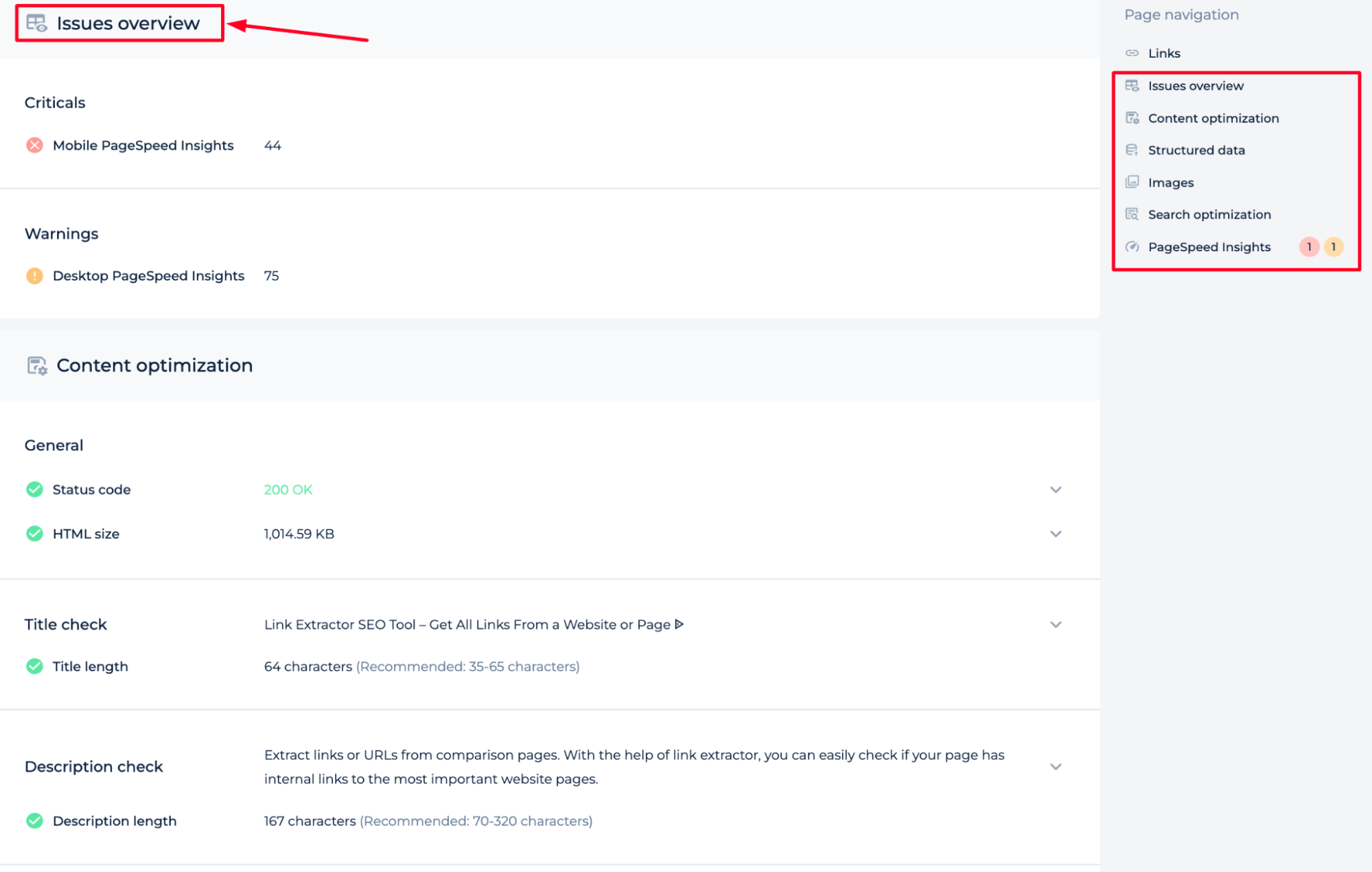
The Website Link Extractor tool demonstrates its ability to analyze and report various SEO issues. Within its dashboard, you’ll find an organized ‘Issues List’ where you can review and address specific problems such as excessive internal links, missing alt text in images, and inconsistent anchor text.
The sidebar provides a statistical breakdown of affected pages, allowing for efficient prioritization and remediation. This tool enables you to take actionable steps towards optimizing your website’s URL structure and overall SEO health.
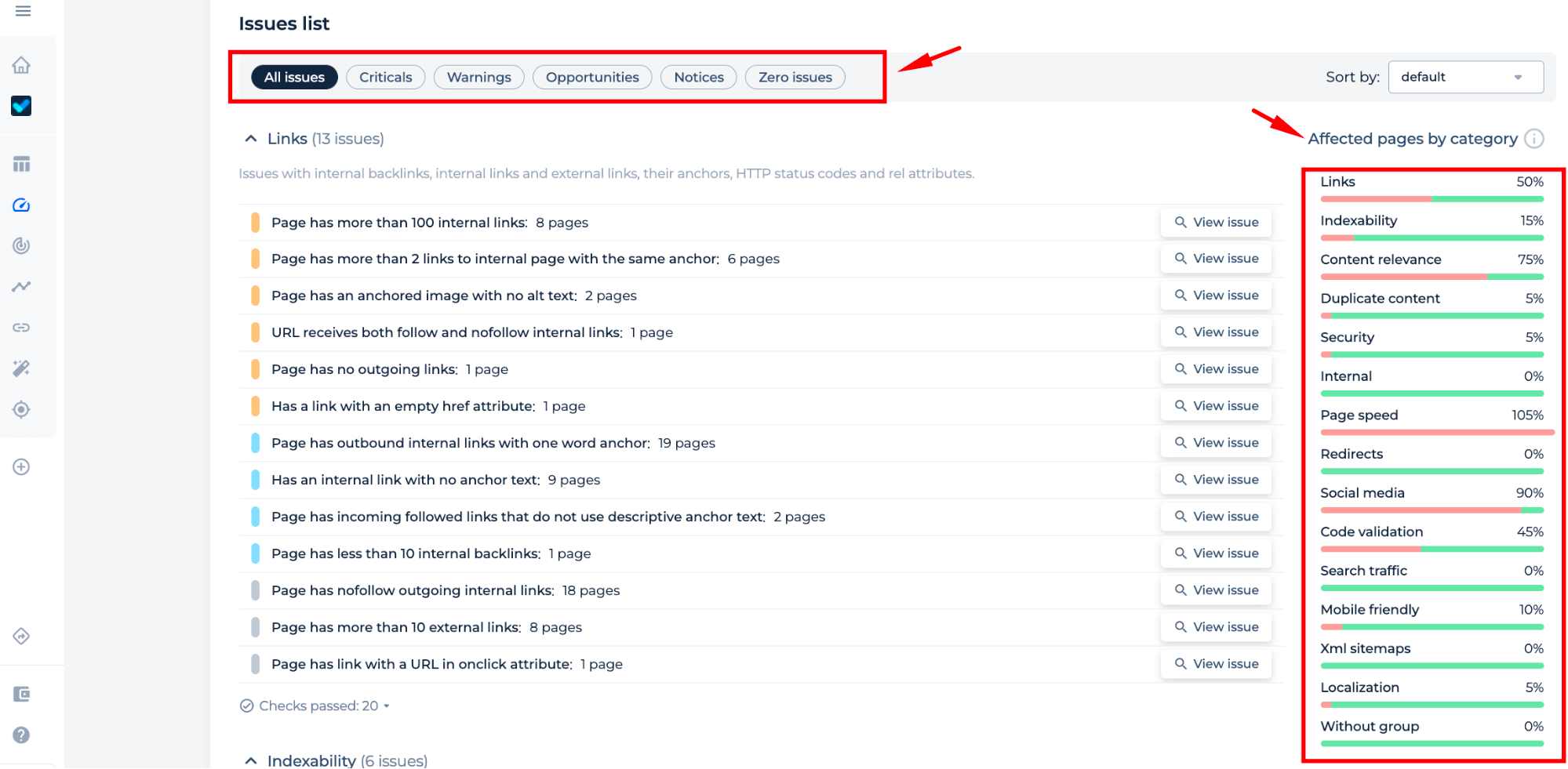
The Website Link Extractor provides a streamlined solution for SEO professionals to monitor and export data on outgoing URLs with malformed href attributes. It ensures that issues can be addressed directly within the tool, with functionalities to view the specific code snippet of the issue. Additionally, the tool offers robust export options, including CSV, Google Sheets, and a convenient URL copy feature, optimizing the workflow for site audits and maintenance. Its integrated sitemap generation capability further assists in efficient site management.
You can also check out our tutorial below:
Page Check
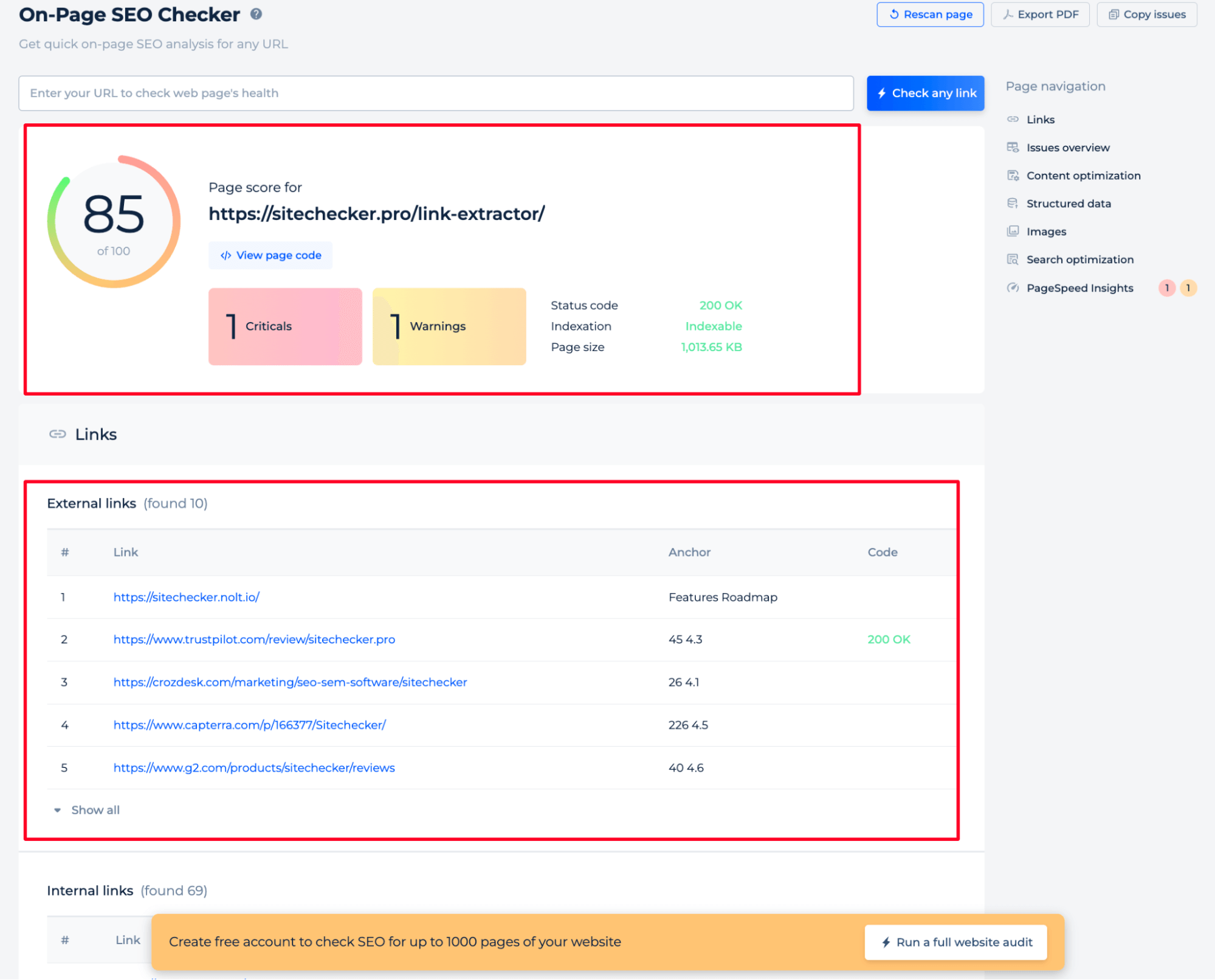
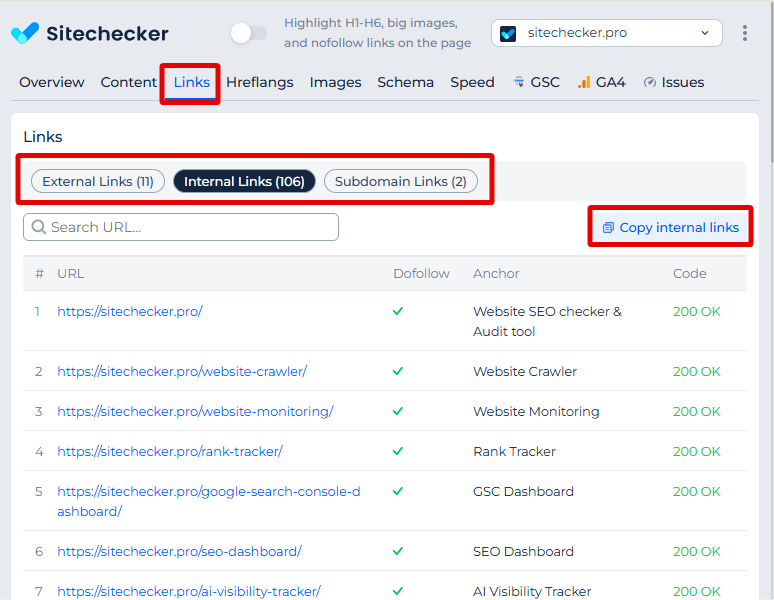
The online tool lists external URLs found on the page, complete with anchor texts and HTTP status codes, for a detailed review.
Step 2: Interpreting results via page check
It lists external links, internal links, and subdomain links with corresponding anchors and status codes, facilitating an easy review of outbound SEO elements.
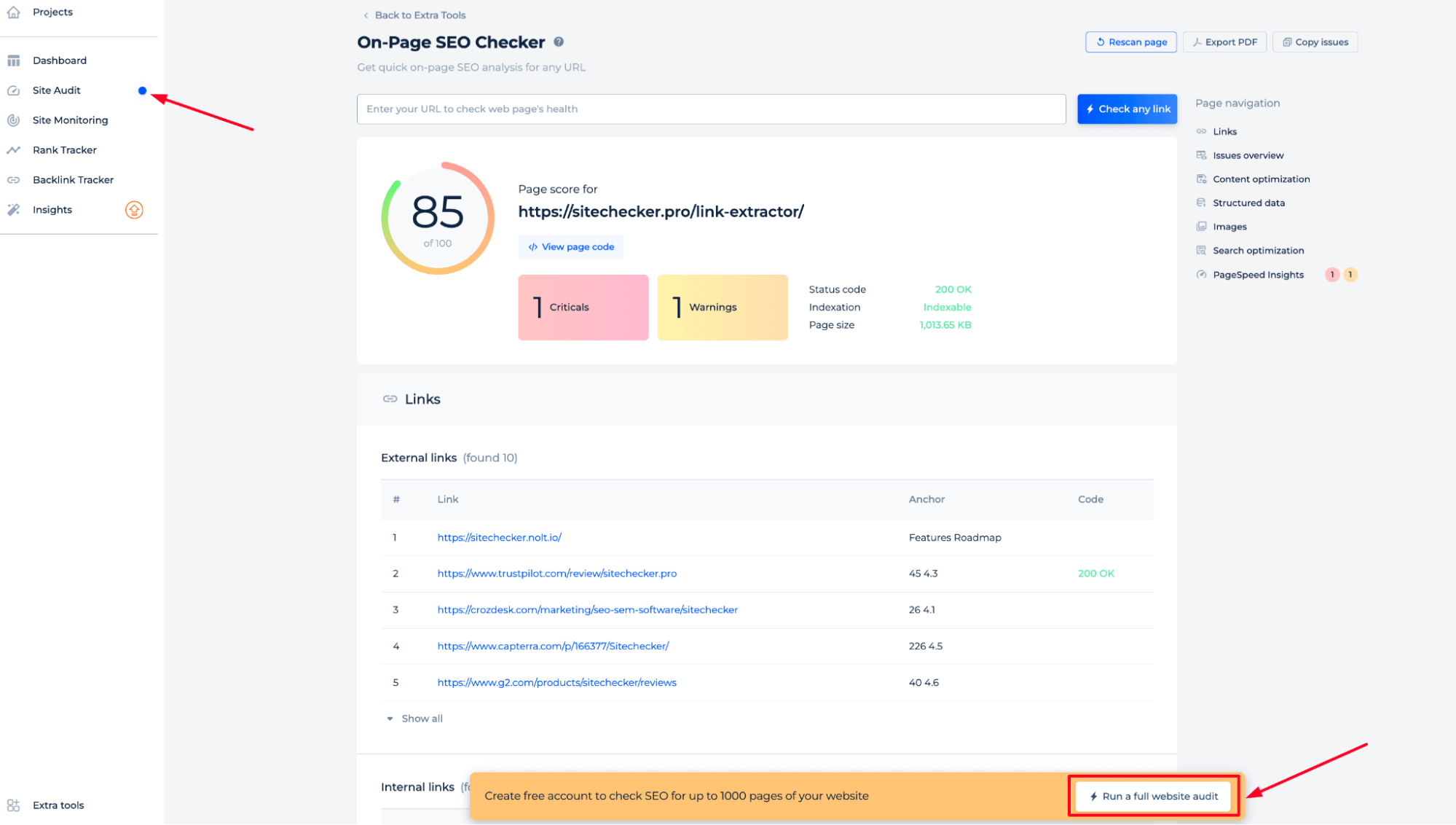
The tool displays a web page’s health with an SEO score and offers quick access to detailed information such as status code, indexation, and page size.
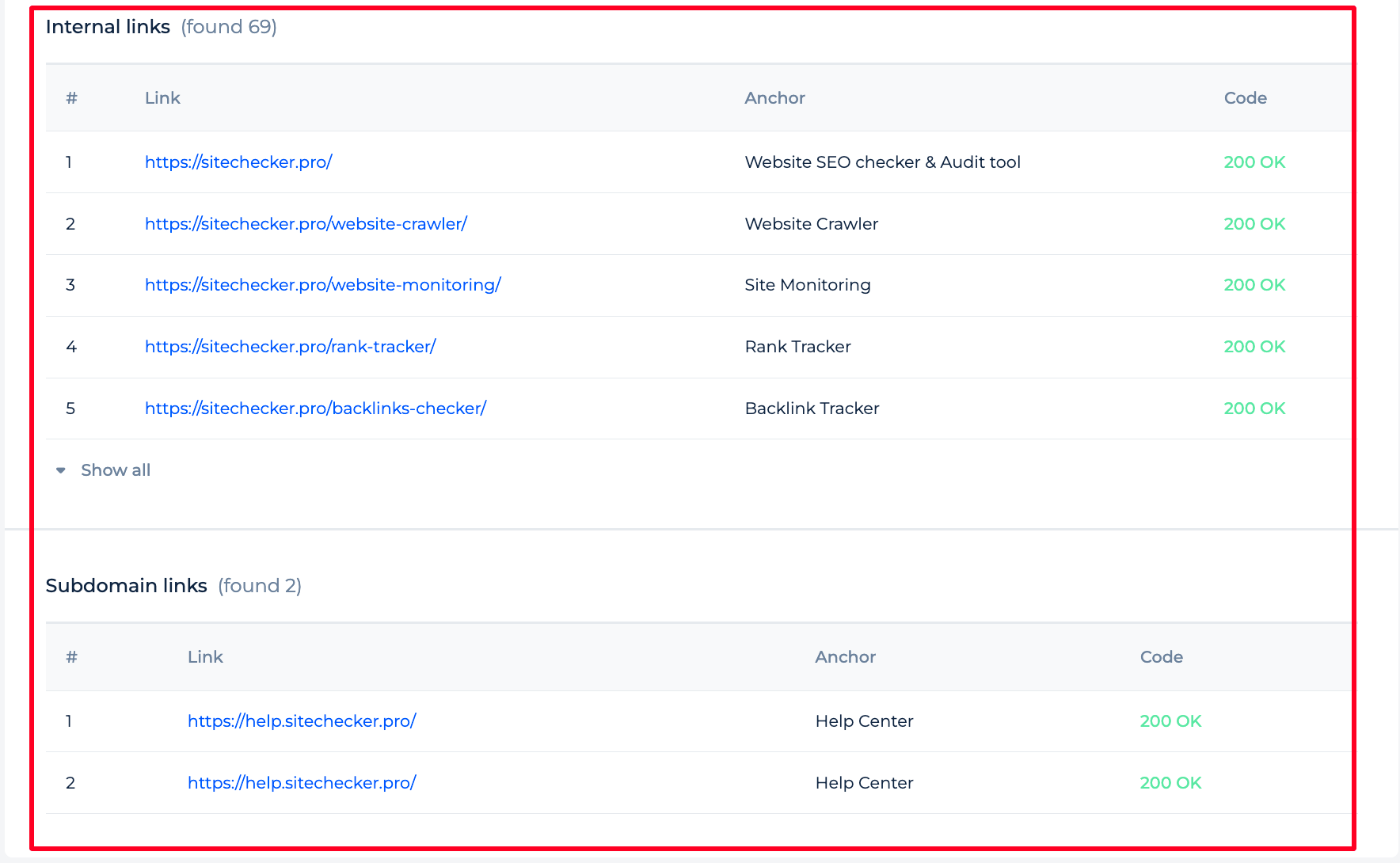
The tool provides an analysis of internal and subdomain links on a website. It lists internal links, displaying the anchor text used for each link and the HTTP status code, indicating successful navigation within the site. It also identifies links to subdomains, which are treated separately, showing their anchors and status codes to ensure they are correctly set up for optimal website structure and SEO performance.
The tool also assists with key aspects of website optimization. It identifies critical SEO issues for resolution, enhances content by reviewing titles and metadata, ensures structured data is in place, and checks for proper search index settings. Additionally, it evaluates mobile site speed to improve user experience.
Check and copy links instantly with the Sitechecker Chrome Extension
The Sitechecker Chrome Extension lets you analyze all links on a page without leaving your browser page.
It instantly detects internal and external links, shows their anchor texts, dofollow/nofollow attributes, and HTTP status codes, and highlights them directly on the page for quick review.
You can also filter and copy links in one click, making it easy to build outreach lists, audit link structure, or extract internal URLs for further analysis — all without running a separate crawl.
Additional features of the page check
For a thorough SEO audit of your website, create a free account to perform an extensive analysis on up to 1,000 pages. With access to your account, you can review all internal and external pages on your site, identify any errors, investigate response codes, analyze your site’s entire anchor strategy, and so on.
To gain a more thorough insight into the tool’s features after scanning your domain, consult the domain verification screens in the first section of this manual. Alternatively, the interactive demo project provides a practical example of how the tool can benefit you.
Additionally, using the Subdomain Finder will help you locate and analyze all subdomains associated with your domain, ensuring they are optimized and free of errors. This is especially useful for large websites with multiple subdomains that may need individual attention for SEO improvements.
Concluding Remarks
To wrap up, the website link finder extracts, analyzes, and monitors all links on a website, providing comprehensive insights for each URL. It detects and helps rectify link-related issues while offering holistic SEO capabilities, including on-page and off-page audits, rank tracking, and site monitoring. Users can leverage this tool for various purposes, such as verifying link status, generating sitemaps, or testing new landing pages. With easy-to-use features, users can analyze an entire domain or a specific page. Furthermore, the tool offers a customizable reporting system, making it ideal for SEO consultants, agency professionals, and website owners.







