



Introduction to AJAX and Its Role in SEO
In the ever-evolving world of web development and design, AJAX stands out as a transformative technology that has reshaped how web pages behave and interact with users. Before delving into its role in SEO, let’s understand what AJAX is and why it’s significant.
What is AJAX?
AJAX, which stands for Asynchronous JavaScript and XML, is a technique used in web development to create dynamic and interactive user experiences. Unlike traditional web interactions where a full page reload is required to fetch or send data to the server, AJAX allows for the exchange of data with the server behind the scenes. This means that parts of a web page can be updated without requiring the entire page to reload, leading to smoother and more responsive user interactions.
The SEO Challenge with AJAX
While AJAX offers improved user experience, it poses unique challenges for search engine optimization (SEO). Historically, search engines primarily indexed static HTML content. With AJAX, much of the content is loaded dynamically, which means that without the right implementations, this content might remain invisible to search engine crawlers. If search engines can’t see the content, it can’t be indexed, leading to potential losses in organic search visibility.
The Importance of AJAX in Modern Web Design
With the rise of single-page applications (SPAs) and the demand for real-time data interactions, AJAX has become a cornerstone in modern web design. Websites like social media platforms, e-commerce stores, and news outlets often use AJAX to load new content, update user interfaces, or submit forms without the need for a full-page refresh.
Balancing User Experience and SEO
The key challenge for webmasters and SEO professionals is ensuring that AJAX-driven content is not only user-friendly but also accessible to search engines. Techniques like AJAX Crawling come into play here, ensuring that dynamically loaded content is also crawlable and indexable by search engines. Proper implementation ensures that websites maintain their SEO integrity while delivering top-notch user experiences.
AJAX has revolutionized the way users interact with web content, providing faster and more fluid experiences. However, with these advancements come new challenges in the realm of SEO. As we delve deeper into this topic, we’ll explore how to navigate these challenges and ensure that AJAX-driven websites remain both user-friendly and search engine-friendly.
What is Crawling?
In the vast expanse of the World Wide Web, with billions of web pages and an ever-growing amount of content, search engines have a monumental task: to discover, understand, and organize this information so that users can find what they’re looking for in mere seconds. The process that enables this rapid discovery and indexing of web content is known as “crawling.”
The Basics of Web Crawling
At its core, crawling is the process by which search engines discover and retrieve web pages. Think of it as sending out virtual “spiders” or “bots” that traverse the web, hopping from one webpage to another, collecting data along the way. These bots start with a list of known web addresses and then follow links on those pages to discover more content.
How Crawlers Work
- Starting Point: Crawlers begin with a predefined list of URLs known as seeds. These seeds can be popular web pages or sitemaps submitted by website owners.
- Following Links: As crawlers visit a webpage, they “read” the content and identify links on that page. They then add these links to their list of pages to visit next.
- Content Retrieval: In addition to identifying links, crawlers fetch the content of the web page, which can include text, images, videos, and other media.
- Respecting Rules: Not all pages should or want to be crawled. Websites can use a file called “robots.txt” to specify which parts of their site should not be accessed by crawlers. Respectful bots always check this file before crawling to ensure they adhere to the website’s wishes.
Why Crawling is Crucial for SEO
For a webpage to appear in search engine results, it first needs to be discovered and indexed. If a page is not crawled, it remains invisible to the search engine, and thus, to users. SEO professionals often work to ensure that important pages are easily discoverable by search engine crawlers and that unnecessary or sensitive pages are kept out of the crawl using methods like the “noindex” directive or adjustments to the robots.txt file.
Is Ajax Crawling Supported by Google?
Yes, AJAX crawling still exists, but it is no longer recommended by Google. In 2009, Google published a proposal for how to make AJAX pages crawlable, but in 2015, they deprecated this proposal. This was because Google had improved its ability to crawl and render AJAX pages without any special assistance from webmasters.
However, Google still supports the old AJAX crawling proposal, and some webmasters may still choose to use it. If you are using the old AJAX crawling proposal, you do not need to change anything. Your site will still be crawled and indexed by Google. However, Google recommends that you implement industry best practices when you are making the next update for your site.
Here are some tips for making your AJAX site crawlable:
- Use HTML5 history pushState and replaceState to update the URL in the browser without reloading the page.
- Use server-side rendering to pre-render some of your AJAX content.
- Use a JavaScript framework like React or Angular that supports server-side rendering.
- Use a sitemap to help Google discover your AJAX pages.
John Mueller of Google About the AJAX Crawling Scheme
On Twitter, John Mueller of Google has said that the AJAX crawling scheme is being deprecated and will be fully removed in the future. He has also advised website owners to stop using it and move to a different URL pattern.
On May 24, 2018, Mueller tweeted:
On the same day, he also tweeted:
Google has been deprecating the AJAX crawling scheme since 2015, but it is still unclear when it will be fully removed. However, it is clear that Google is no longer actively supporting it, and website owners are advised to move to a different URL pattern.
In this Ask Google Webmasters episode, John Mueller explores the latest on AJAX crawling, hash-bang URLs, and transitioning to a new URL structure.
Challenges in Crawling
While the concept might sound straightforward, the reality of crawling is complex. With websites employing AJAX, JavaScript, and other dynamic content generation techniques, traditional crawling methods might not capture all the content. This has led to the evolution of more sophisticated web crawlers that can execute scripts, similar to how modern web browsers operate, ensuring that dynamically generated content is also discoverable.
Ajax Crawling – Rendering Before Crawling
The web has transformed from being primarily static to becoming highly dynamic. With the adoption of technologies like AJAX, websites can deliver content on-demand, updating parts of a page without requiring a full refresh. While this has significantly improved user experience, it has introduced challenges for search engine crawlers, which were initially designed to index static HTML. This is where AJAX crawling and the concept of rendering before crawling come into play.
Understanding the Challenge
Traditionally, search engine crawlers fetched the raw HTML of a page and indexed it. However, with AJAX-driven content, the HTML fetched by the crawlers might not contain all the page’s content. Instead, it often has placeholders that are filled with content only after executing JavaScript AJAX requests. Since older crawlers don’t execute JavaScript, they miss out on this dynamically loaded content.
If crawlers can’t execute AJAX requests, how does AJAX crawling work?
The crux of the challenge lies in the asynchronous nature of AJAX. Content loaded via AJAX may not be immediately available when the page loads, especially if it relies on user interactions or other triggers. So, even if crawlers were to execute JavaScript, there’s no guarantee they’d capture all AJAX-driven content. This dilemma led to the development of AJAX crawling techniques that ensure search engines can access and index this content.
| Prerendering | One of the primary methods used is prerendering. Websites can generate a fully rendered version of the page, complete with all AJAX-loaded content, and serve this version to search engine crawlers. Tools and services are available that can create these prerendered snapshots for websites, ensuring that what the crawler sees is what the user sees. |
| Using the #! (Hashbang) URL Structure | Earlier, a method advocated by Google involved using a special URL structure with #! to indicate AJAX-driven content. When search engines encountered such URLs, they would request a static snapshot of the page from the server, which would then be indexed. However, this method is now outdated and not recommended, as search engines have evolved to better understand and index JavaScript-heavy sites. |
| Modern Crawlers Execute JavaScript | Recognizing the shift towards dynamic web content, major search engines have updated their crawlers to execute JavaScript. This means that, to some extent, they can process AJAX requests and index the resulting content. However, relying solely on this can be risky, as not all search engines or their versions might fully render JavaScript content. |
| Server-Side Rendering (SSR) | Another effective method, especially for single-page applications (SPAs), is to use server-side rendering. With SSR, the server sends a fully rendered page to both users and crawlers, ensuring that dynamic content is accessible even without executing JavaScript on the client side. |
Two Ways of Prerendering AJAX Web Pages
Prerendering is a powerful technique that serves search engine crawlers a fully rendered version of a web page, ensuring that all AJAX-driven content is accessible and indexable. This process helps bridge the gap between dynamic web pages and the traditionally static content that search engines are accustomed to indexing. Let’s explore two primary methods of prerendering AJAX web pages.
1. Server-Side Rendering (SSR)
What is SSR? Server-Side Rendering, commonly referred to as SSR, involves generating the final HTML content on the server itself before sending it to the client (browser or crawler). This ensures that the page is fully rendered with all its content, including that loaded via AJAX, when it reaches the client.
Benefits of SSR:
- SEO Boost: Since the server sends a fully rendered page, search engine crawlers can easily index the content, leading to better SEO performance.
- Faster Initial Load: The browser receives a ready-to-display page, which can lead to quicker initial page render times, enhancing user experience.
- Consistency: Both users and search engine crawlers see the same version of the page, ensuring content consistency.
Challenges with SSR:
- Server Load: Rendering pages on the server can be resource-intensive, especially for high-traffic sites.
- Complexity: Implementing SSR can be complex, especially for sites not originally designed with SSR in mind.
2. Prerendering Services
What are Prerendering Services? Prerendering services are third-party solutions that automatically generate static snapshots of web pages. These snapshots are then served to search engine crawlers. The process typically involves browsing the website using a headless browser, capturing the fully rendered content, and then storing these snapshots for future requests.
Benefits of Prerendering Services:
- Ease of Implementation: These services often provide plug-and-play solutions, reducing the technical overhead for website owners.
- Up-to-Date Snapshots: Many services regularly refresh the prerendered content, ensuring that search engines always access the latest version.
- Reduced Server Load: Since the prerendering happens off-site, there’s minimal impact on the original server’s resources.
Challenges with Prerendering Services:
- Cost: These are third-party services, and there might be associated costs depending on the volume of pages and frequency of updates.
- Reliability: Relying on an external service introduces another point of potential failure. It’s essential to choose reputable providers to ensure uptime and reliability.
Automation Frameworks And Headless Browsers
The evolution of web technologies and the need for more sophisticated testing and rendering solutions have given rise to automation frameworks and headless browsers. These tools play a pivotal role in modern web development, especially when dealing with dynamic, AJAX-driven content. Let’s dive into understanding these concepts and their significance.
What are Automation Frameworks?
Automation frameworks are structured systems that standardize the test automation process. They provide a set of guidelines, tools, and practices to facilitate the creation, execution, and reporting of automated tests. These frameworks enable developers and testers to validate functionality, performance, and user experience without manual intervention.
Popular Automation Frameworks:
- Selenium: An open-source framework that supports multiple programming languages and browsers. It allows testers to write scripts that can simulate user interactions on web pages.
- Cypress: A JavaScript-based end-to-end testing framework that provides real-time reloading and automatic waiting, making it easier to test modern web applications.
- Puppeteer: A Node library developed by Google that offers a high-level API to control headless Chrome browsers.
What are Headless Browsers?
Headless browsers are web browsers without a graphical user interface (GUI). They can access web pages, render content, and execute JavaScript, just like regular browsers. However, they do so in the background, making them ideal for automated tasks, such as web scraping, testing, and prerendering.
Advantages of Headless Browsers:
- Speed: Without the overhead of rendering graphics and user interfaces, headless browsers can operate much faster than traditional browsers.
- Automation: They seamlessly integrate with automation tools and frameworks, allowing for efficient testing and data extraction.
- Resource Efficiency: Headless browsers use fewer system resources, making them suitable for continuous integration pipelines and cloud environments.
Popular Headless Browsers:
- Headless Chrome: Google Chrome’s version that can run in headless mode, enabling automated testing and server-side rendering.
- PhantomJS: A scriptable headless browser used for automating web page interactions.
- SlimerJS: Similar to PhantomJS but for the Gecko layout engine (used in Firefox).
Combining Automation Frameworks with Headless Browsers
The fusion of automation frameworks with headless browsers creates a powerful synergy. For instance:
- Developers can write scripts using Selenium to automate user interactions on a web page and run these scripts in Headless Chrome, simulating real user behavior without the need for visual rendering.
- Tools like Puppeteer not only provide automation capabilities but are intrinsically tied to headless browsing, making tasks like screenshot capture, PDF generation, and web scraping more efficient.
Prerendering as a Service
In an era where web interactivity and dynamism are at the forefront, ensuring that AJAX-driven content remains accessible to search engines is paramount. Prerendering, as we’ve discussed, is a technique to tackle this challenge. However, implementing prerendering in-house can be resource-intensive and technically challenging. This has given rise to “Prerendering as a Service” – a cloud-based solution that handles the complexities of prerendering for website owners. Let’s delve deeper into this service and its advantages.
What is Prerendering as a Service?
Prerendering as a Service is an outsourced solution where third-party providers automatically generate and store static snapshots of dynamic web pages. When search engine crawlers request a page, the prerendered version, complete with all AJAX-loaded content, is served, ensuring that the content is indexable.
How It Works:
| Integration | Website owners integrate with the prerendering service, often through simple plugins or changes in server configuration. |
| Page Rendering | The service uses headless browsers to access and render the website’s pages, capturing the fully loaded content, including AJAX-driven components. |
| Snapshot Storage | The rendered pages are stored as static snapshots on the service’s servers or cloud infrastructure. |
| Serving to Crawlers | When search engine bots request a page, the prerendered snapshot is served, ensuring the bot can access all content, including dynamically loaded elements. |
| Regular Updates | To ensure that search engines access up-to-date content, the service periodically refreshes the stored snapshots. |
Advantages of Prerendering as a Service:
- Ease of Implementation: Many services offer plug-and-play solutions, making integration straightforward even for non-technical website owners.
- Scalability: These services are built to handle websites of all sizes, from small blogs to large e-commerce platforms, ensuring consistent performance.
- Reduced Server Load: Prerendering can be resource-intensive. Offloading this task to a third-party service ensures that the website’s primary servers remain efficient and responsive to user requests.
- Up-to-Date Content: With regular snapshot refreshes, website owners can be confident that search engines are indexing the most recent and relevant content.
Popular Prerendering Services:
-
Prerender.io: A widely-used service that provides easy integrations with many platforms and frameworks.
-
SEO4Ajax: A solution designed specifically for single-page applications (SPAs) to boost their SEO performance.
How to Crawl JavaScript Websites
JavaScript and Ajax Crawling
JavaScript, the driving force behind many interactive and dynamic web applications, plays a pivotal role in shaping modern web experiences. AJAX, as a subset of JavaScript functionalities, further augments this by allowing for asynchronous data fetching and updating webpage content without a full reload. However, these advancements in web interactivity bring forth challenges in ensuring the content remains accessible and indexable by search engines. Let’s delve into the relationship between JavaScript, AJAX, and the intricacies of web crawling.
The Dynamics of JavaScript-Driven Content
Traditionally, web content was largely static, with HTML serving the bulk of the page’s content. With the advent of JavaScript, web pages have become more dynamic. Content can now be loaded, altered, or hidden based on user interactions, browser events, or other triggers. AJAX, in particular, facilitates fetching data from the server without reloading the entire page, allowing for seamless updates to specific parts of the page.
The Challenge for Search Engines
Search engine crawlers, designed initially to index static HTML, face challenges when encountering JavaScript-driven content:
- Delayed Content Loading: Content loaded via AJAX might not be immediately available when the crawler accesses the page. This can result in the crawler missing out on vital content.
- User Interactions: Some content might only appear or load based on specific user actions, like clicking a button or hovering over an element. Traditional crawlers can’t simulate these actions.
- Complex Execution: Advanced JavaScript functionalities or errors in scripts can hinder the proper rendering of content for crawlers.
Solutions for Effective AJAX Crawling
To ensure that AJAX-driven content is crawlable, several strategies have been developed:
- Prerendering: As discussed earlier, prerendering involves generating a fully rendered version of the page, with all AJAX content loaded, and serving this to crawlers. This ensures that search engines can access the entire content as users see it.
- Progressive Enhancement: A web design principle where the basic content and functionality of a page are accessible without JavaScript. Additional layers of interactivity and complexity (like AJAX) enhance the experience for browsers that support it.
- Dynamic Rendering: Websites can detect the user-agent of the accessing entity. If it’s a search engine crawler, the server can provide a fully rendered, static version of the page. For regular users, the dynamic, interactive version is served.
Modern Search Engines Adapt
Recognizing the growing importance of JavaScript and AJAX in web development, major search engines have made strides in evolving their crawling capabilities:
- JavaScript Execution: Modern crawlers, especially those from leading search engines like Google, can execute JavaScript, allowing them to access content loaded via AJAX to a certain extent.
- Rendering Budget: Given the resource-intensive nature of rendering JavaScript-heavy pages, search engines allocate a ‘budget’ for rendering. If a site takes too long to load or is too resource-intensive, not all content might be indexed.
Real-World Experiment on AJAX Crawling
The theory and techniques surrounding AJAX crawling can be intricate, and while understanding the fundamentals is essential, there’s no substitute for real-world experimentation to grasp the practical implications. Let’s delve into a hypothetical experiment on AJAX crawling to better understand its challenges and outcomes in a real-world context.
Setting the Stage: The AJAX-Driven Website
Imagine a fictional e-commerce website named “ShopTrendy” that heavily relies on AJAX to load product listings. When users filter products based on categories like “shoes” or “bags”, AJAX requests fetch and display the relevant products without reloading the entire page.
The Goal
Determine how effectively search engines can index product listings on “ShopTrendy” that are loaded dynamically through AJAX.
Experiment Steps
- Baseline Data Collection: Before making any changes, monitor the site’s current performance in search engine results for targeted keywords related to its products.
- Implementing Prerendering: Integrate a prerendering solution to ensure that search engines receive a fully rendered version of the page, including all AJAX-loaded content.
- Monitoring & Data Collection: Over the next few months, monitor the website’s performance in search engine rankings. Track metrics like organic traffic, indexed pages, and keyword rankings.
- Comparing Results: Compare the post-implementation data with the baseline to gauge the impact of prerendering on search engine visibility.
Hypothesized Outcomes
- Increased Indexed Pages: With prerendering in place, search engines should be able to index more product listings that were previously loaded via AJAX, resulting in a higher number of indexed pages.
- Improved Keyword Rankings: As more product listings become accessible to search engines, the website might see improved rankings for specific product-related keywords.
- Boost in Organic Traffic: With better visibility and more indexed content, the site could experience an increase in organic traffic.
Challenges Encountered
- Technical Hurdles: Implementing prerendering on an existing AJAX-heavy site can introduce technical challenges. Ensuring that the prerendered content aligns perfectly with the dynamically loaded content is crucial.
- Rendering Costs: Prerendering, while effective, can be resource-intensive. Monitoring server loads and optimizing as necessary is essential to prevent site slowdowns or outages.
- SEO Monitoring: SEO is multifaceted, and while AJAX crawling is a significant factor, other elements like backlinks, content quality, and site structure also play a role. It’s vital to ensure that other SEO aspects are consistent to attribute any changes in performance to the prerendering implementation accurately.
AddSearch and AJAX Crawling
In the vast realm of SEO and web crawling, various tools and platforms aim to enhance the discoverability of dynamic web content. One such solution is AddSearch, which provides site search functionalities for websites. When dealing with AJAX-driven sites, understanding how tools like AddSearch interact with and support AJAX crawling becomes crucial. Let’s explore this relationship.
Understanding AddSearch
AddSearch is a hosted search platform that offers an easy-to-implement search solution for websites. It’s designed to provide fast and relevant search results, with features like real-time indexing, customizable result ranking, and a user-friendly dashboard for analytics.
How AddSearch Supports AJAX-driven Sites
- Real-time Indexing: One of the challenges with AJAX content is its dynamic nature. AddSearch’s real-time indexing ensures that as content changes or updates via AJAX, it’s quickly indexed and made searchable.
- JavaScript Integration: AddSearch is inherently designed to work well with JavaScript-heavy sites. Its search functionality can be easily integrated into web pages using JavaScript, making it compatible with AJAX-driven content.
- Customizable Crawling: Website owners can customize how AddSearch crawls their site, ensuring that AJAX-loaded content is appropriately prioritized and indexed.
- Handling Single Page Applications (SPAs): SPAs, which heavily rely on AJAX and JavaScript to load content, can sometimes pose challenges for search solutions. AddSearch’s capabilities are tailored to effectively index and search content within SPAs.
Advantages of Using AddSearch for AJAX-driven Sites
- Enhanced User Experience: With fast and relevant search results, users can quickly find what they’re looking for, even on dynamic, AJAX-heavy sites.
- SEO Boost: While AddSearch primarily enhances on-site search, having a robust search functionality can indirectly benefit SEO. When users can quickly find what they need, they’re more likely to stay longer and engage more with the site, improving metrics like bounce rate and session duration.
- Reduced Server Load: As a hosted search solution, AddSearch handles the indexing and search queries, reducing the load on the website’s primary servers.
Challenges and Considerations
- External Dependency: Relying on an external service like AddSearch introduces a dependency. It’s crucial to ensure the service’s uptime and reliability.
- Costs: AddSearch, like many hosted solutions, comes with associated costs based on usage, features, and the number of indexed pages.
AJAX-driven sites, with their dynamic and interactive content, offer enhanced user experiences but can pose challenges for effective search functionality. Tools like AddSearch bridge this gap, ensuring that even the most dynamic content is easily searchable. By understanding and leveraging such solutions, website owners can ensure that they offer both interactivity and discoverability, catering to users and search engines alike.
Crawl the Website for Technical Issues With Website Crawler for Technical SEO Analysis
The Website Crawler, offered by SiteChecker, is an essential tool for those looking to dive deep into their website’s SEO health. This comprehensive tool mimics the way search engines crawl a site, providing valuable insights into aspects that affect a website’s search performance. It identifies technical issues like broken links, improper redirects, and meta tag inconsistencies, which are crucial for optimizing a website’s structure to rank better in search engine results.
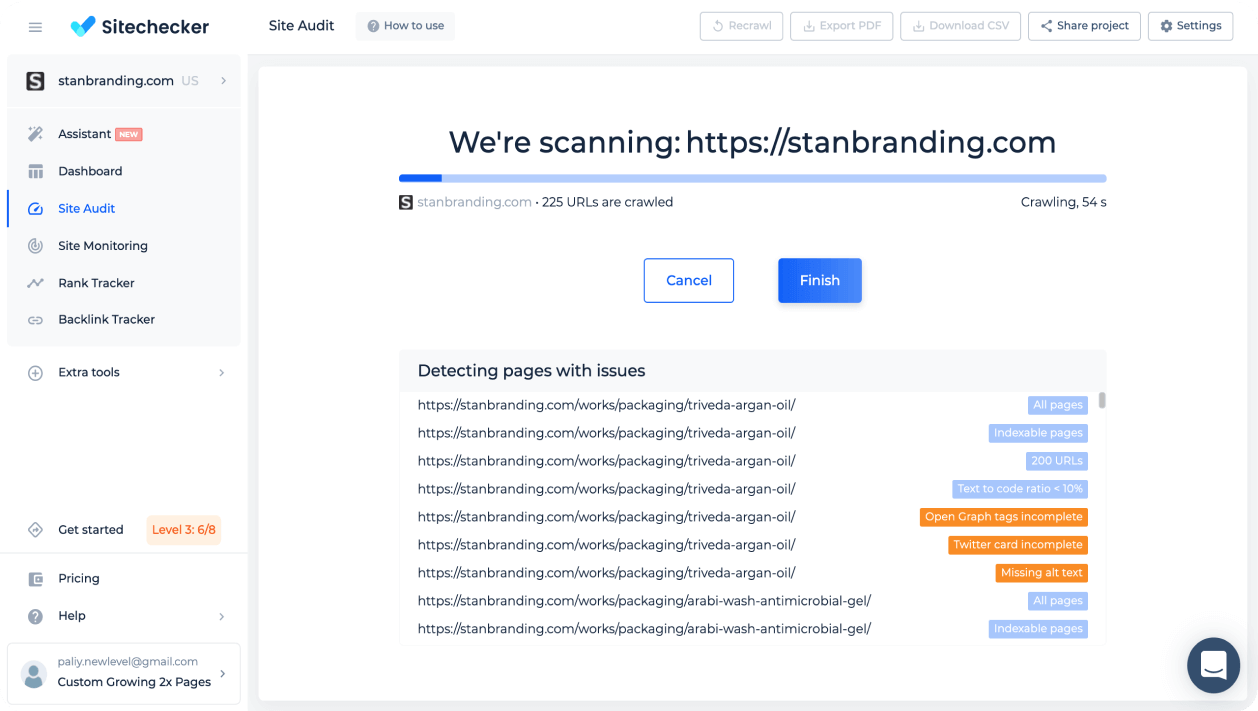
Beyond just identifying issues, this tool also assists in monitoring and improving site-wide SEO elements. It evaluates critical factors such as page loading speed, mobile responsiveness, and overall site structure. The crawler provides detailed reports, including actionable recommendations, allowing webmasters to make informed decisions to enhance their site’s SEO. It’s not only a diagnostic tool but a guide to making strategic improvements for long-term search visibility and success.
Optimize Your Site: Discover SEO Opportunities!
Find and fix hidden technical issues with our comprehensive Website Crawler.
Conclusion
The landscape of web development has undergone transformative shifts, with AJAX and JavaScript playing pivotal roles in enhancing user interactivity and dynamism. While these technologies have enriched the user experience, they’ve also introduced complexities in ensuring content remains accessible and indexable by search engines. Solutions like prerendering, automation frameworks, and tools like AddSearch have emerged to bridge the gap between dynamic content delivery and search engine visibility. As the digital realm continues to evolve, the balance between offering rich, interactive web experiences and ensuring content discoverability remains paramount. Embracing both aspects is the key to a holistic and successful web presence in today’s digital age.





