Real-Time Cloud-Based Website Crawler for Technical SEO Analysis
Crawl the website for technical issues and get a prioritized to-do list with detailed guides on how to fix errors.
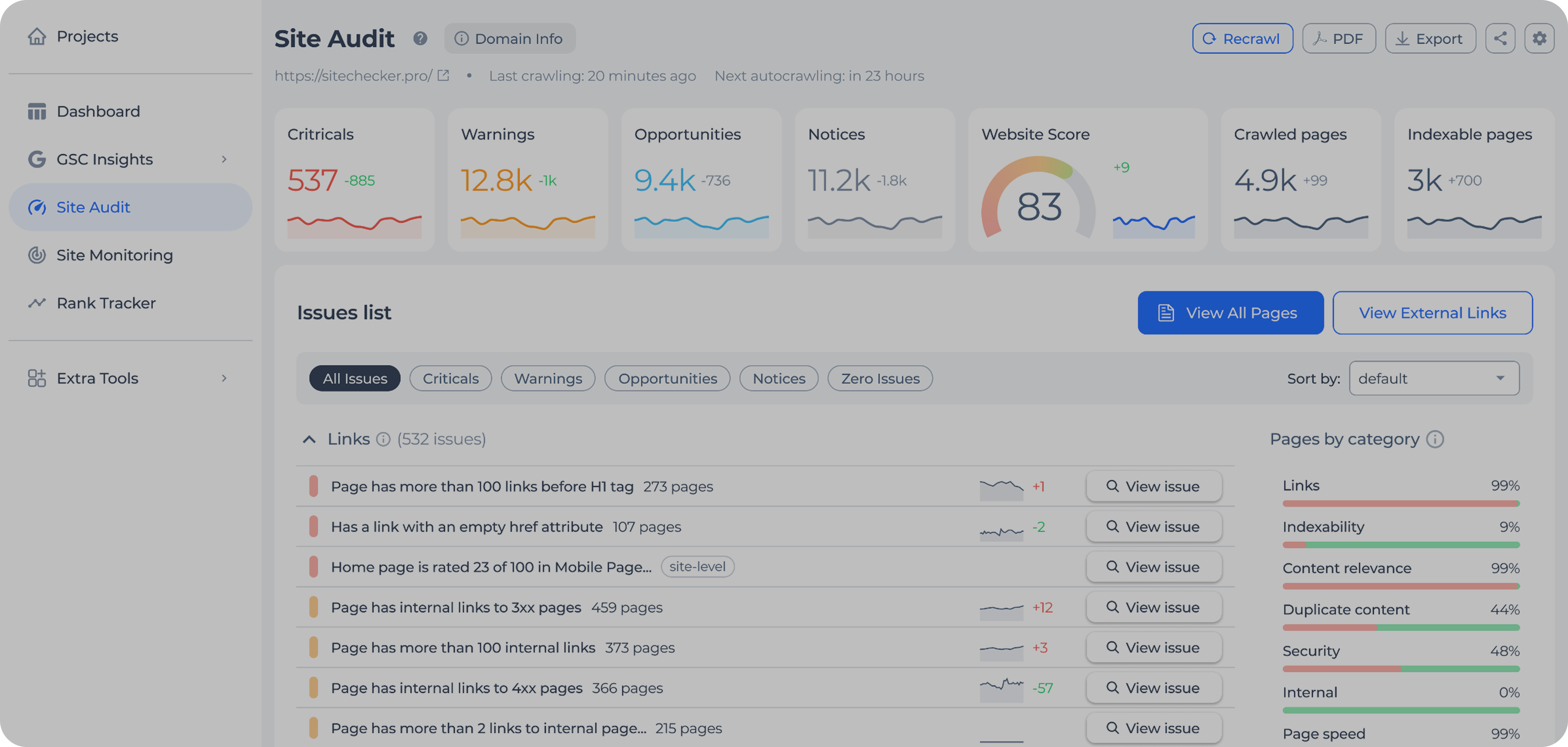
How Sitechecker website crawler can help you

Business owners
Find problems and issues that slow down the growth of organic search traffic. Fix issues yourself or send a report to subordinates or freelancers.

Agencies
Speed up the process of technical SEO audits and decrease the service's net cost. Let clients know what issues you have fixed, brand your reports, and increase your customer retention rate.

In-house marketers
Get a prioritized checklist on how to improve website technical health. Set up email notifications to receive alerts about new issues.
Website on any CMS can be crawled
What’s inside
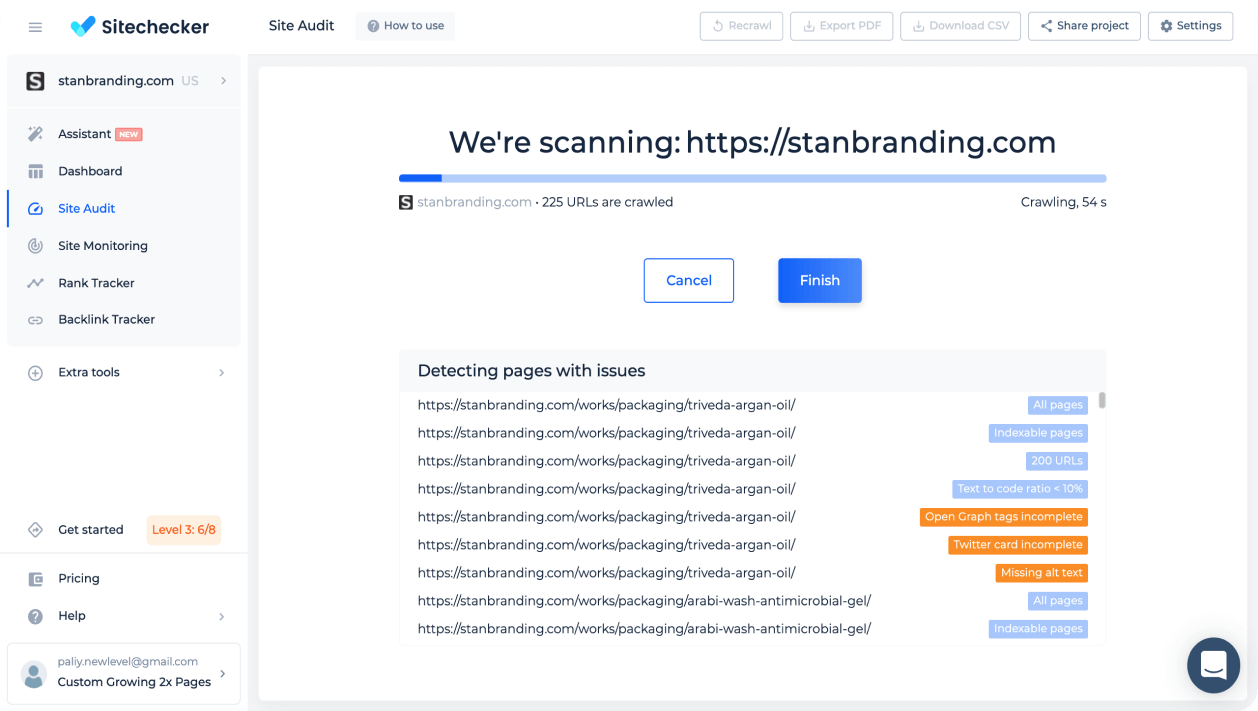
Get a full technical SEO audit in 2 minutes
The average scanning time for websites up to 300 pages is 120 seconds. The crawling will end just as you finish making yourself a cup of tea.
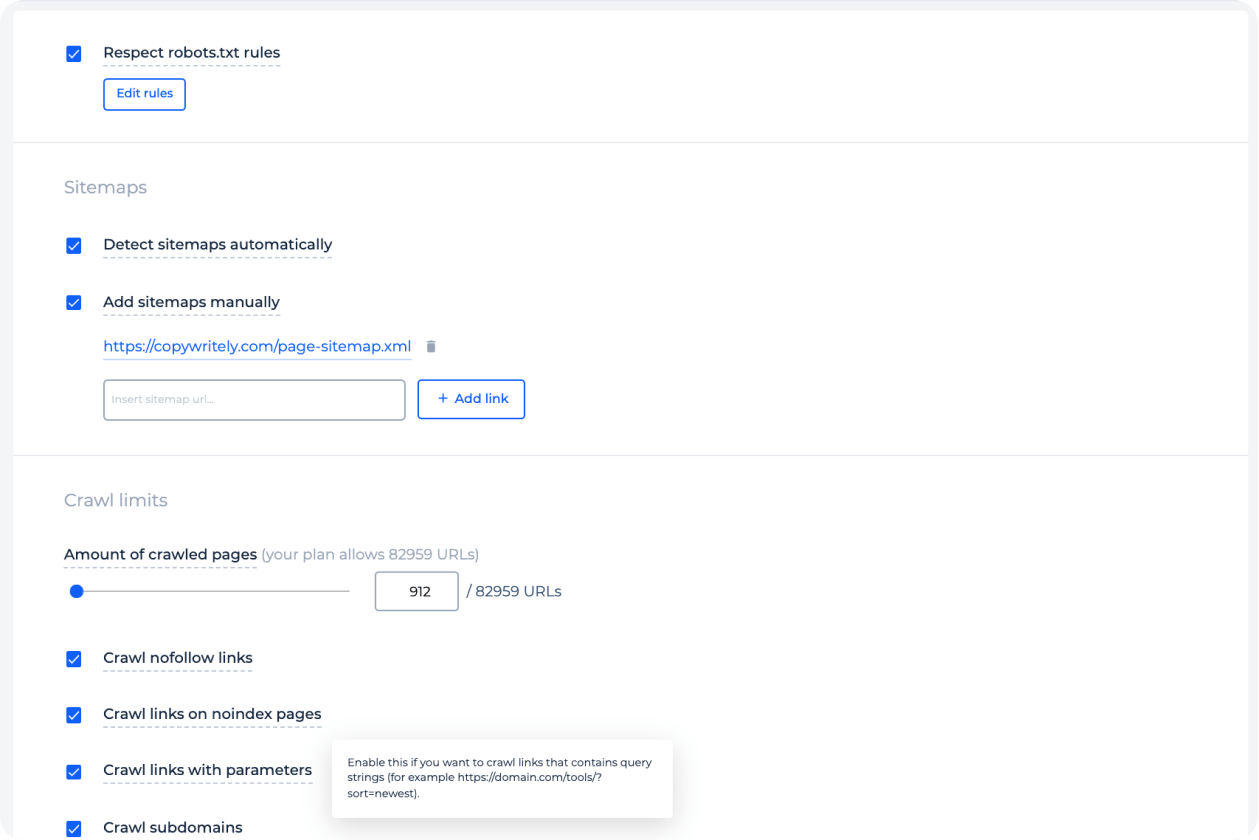
Use flexible crawling settings
Set up rules to find all pages and errors or vice versa; exclude specific URLs, categories, and checks from crawling.
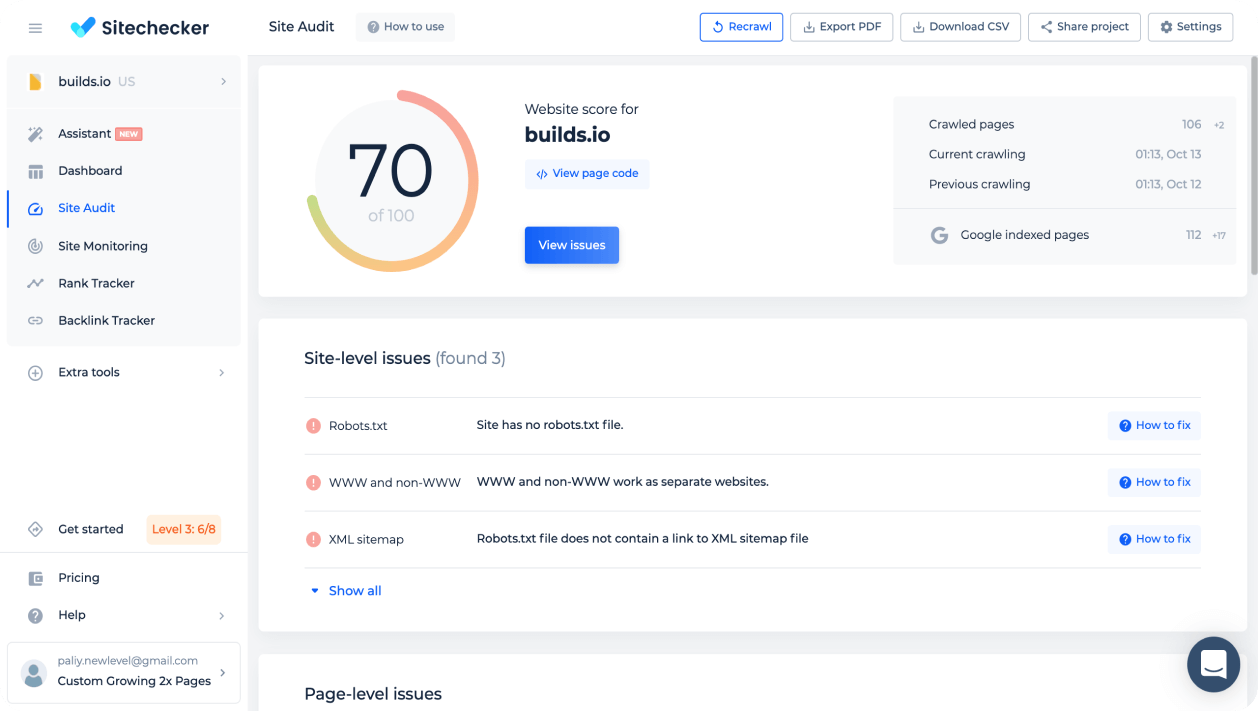
Use Website Score to measure website health
Website Score is an overall indicator of technical website health. It depends on the number of pages and site-level and page-level issues that the website has.
Learn about new or fixed issues
You will receive an email each time critical issues or warnings appear in the project. Such notifications help to ensure that fixes are really implemented and allow you to act immediately on new issues.
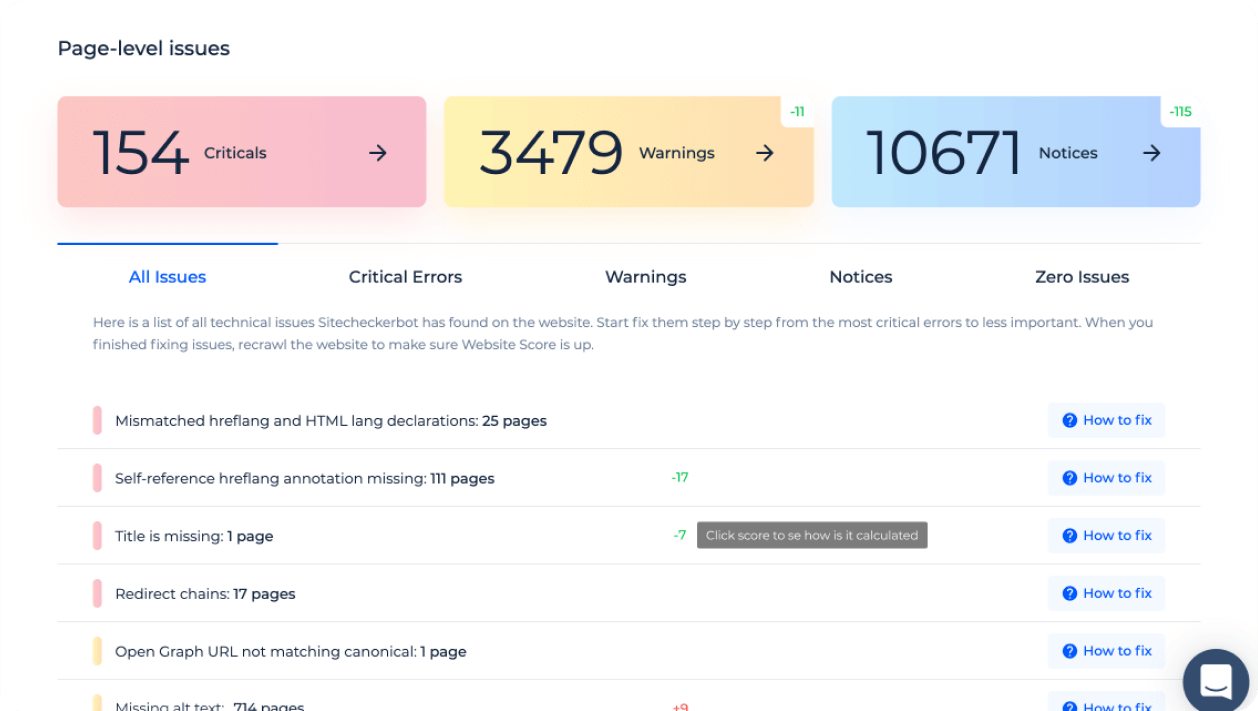
Ignore issues you don't want to fix
You can ignore issues that, in your opinion, aren’t dangerous for the website.
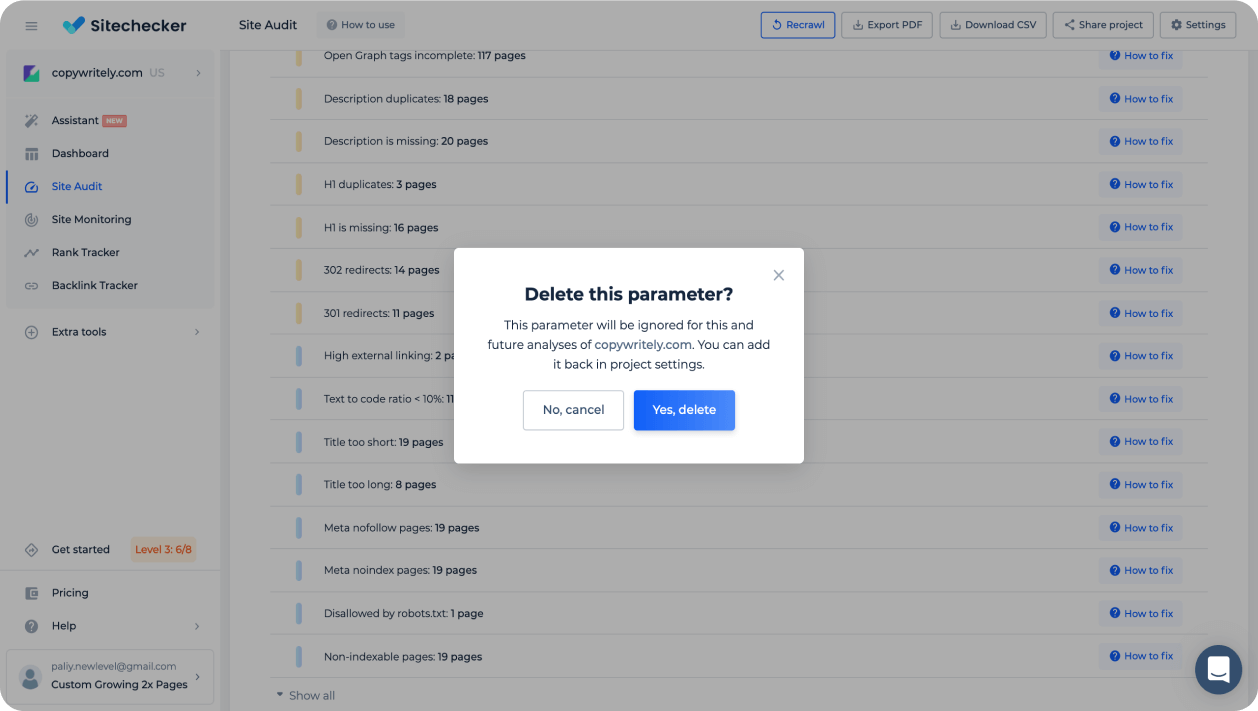
Fix issues yourself with how-to fix guides
Use text and video instructions to understand why the specific issue is important and how to fix it. Delegate fixing issues to developers or junior marketers who have no experience with SEO.
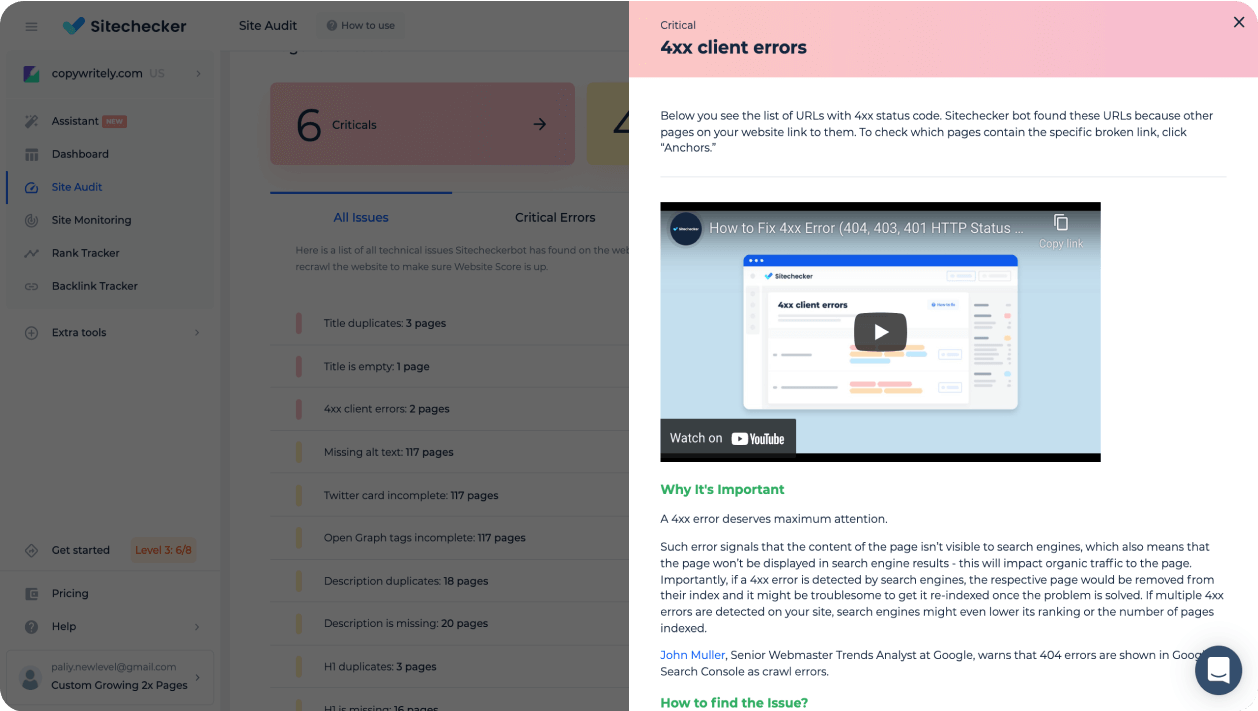
Speed up the fixing process with easy navigation
The sidebar with the list of SEO issues at the right, default sorting by Page Weight, displaying of all issues that the specific page has: All these things will help you improve the Website Score faster.
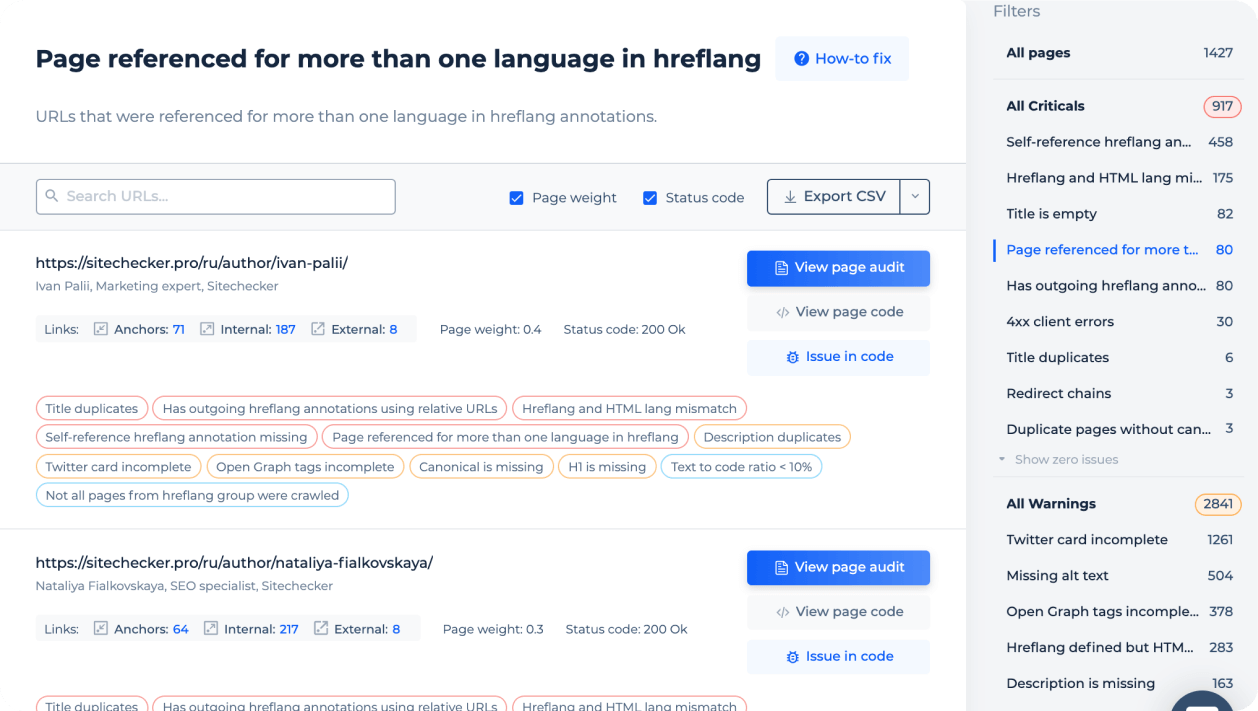
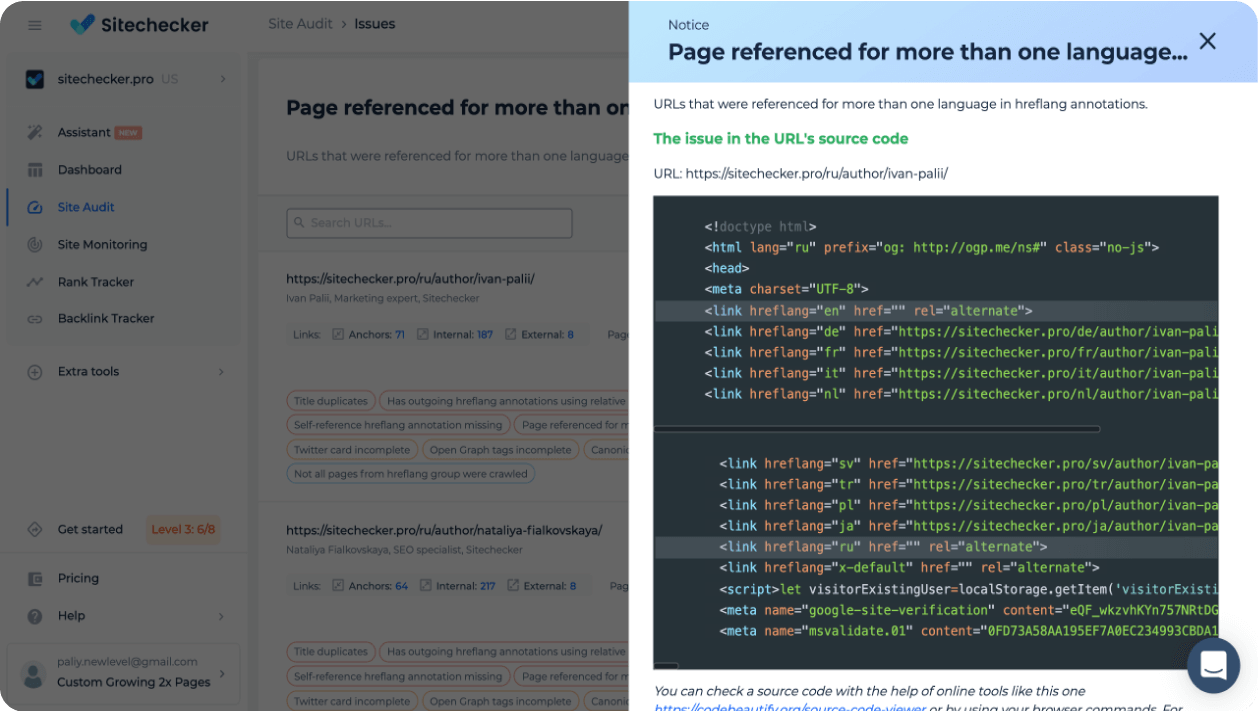
View what the issues will look like in the code
For specific errors, you can see the lines of code that trigger the problem.
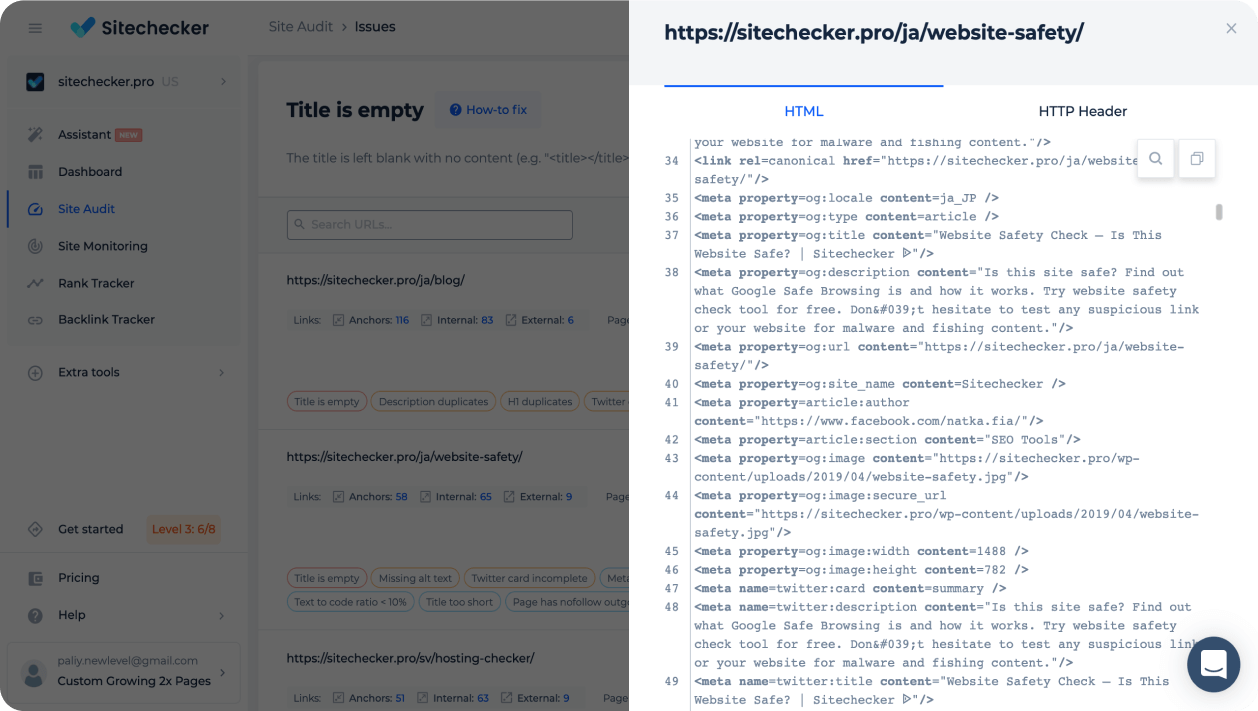
View page code and HTTP headers without leaving Sitechecker
Search for any information in HTML code and HTTP headers without needing to open a new tab in the browser for each page.
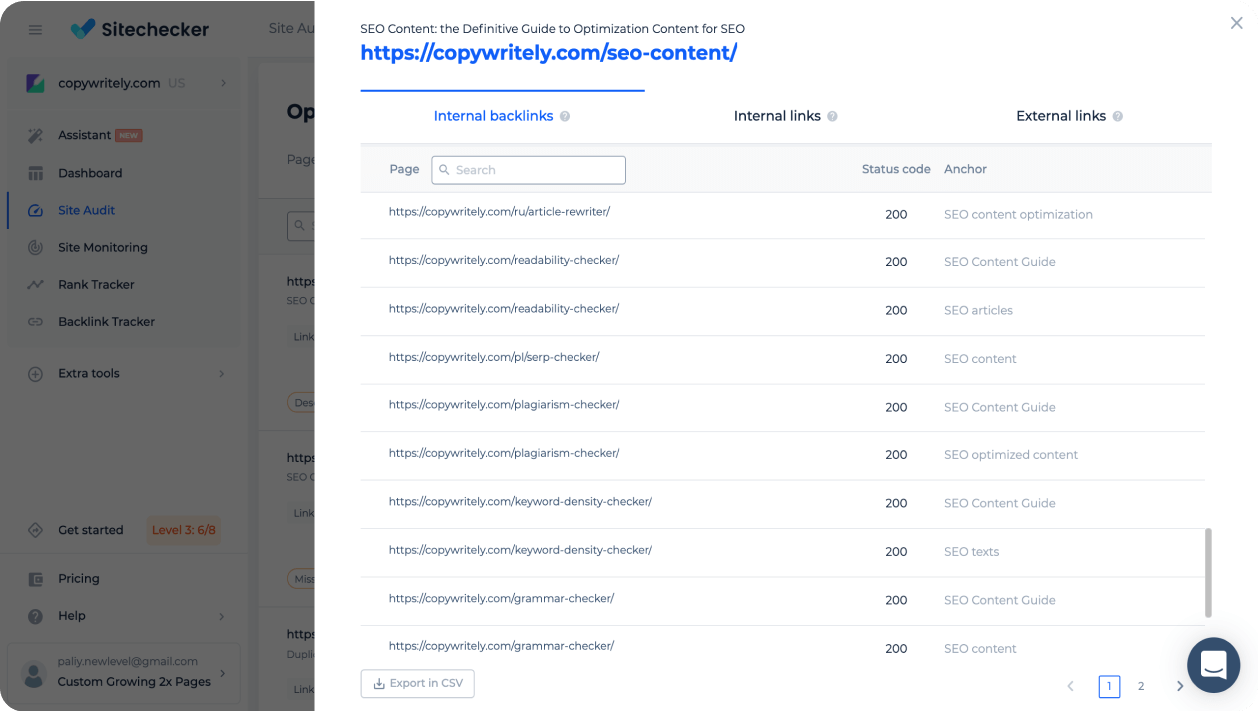
Crawling internal and external links
Check the relevance and HTTP status codes of internal and external links. Explore the anchor list of internal backlinks for the specific page.
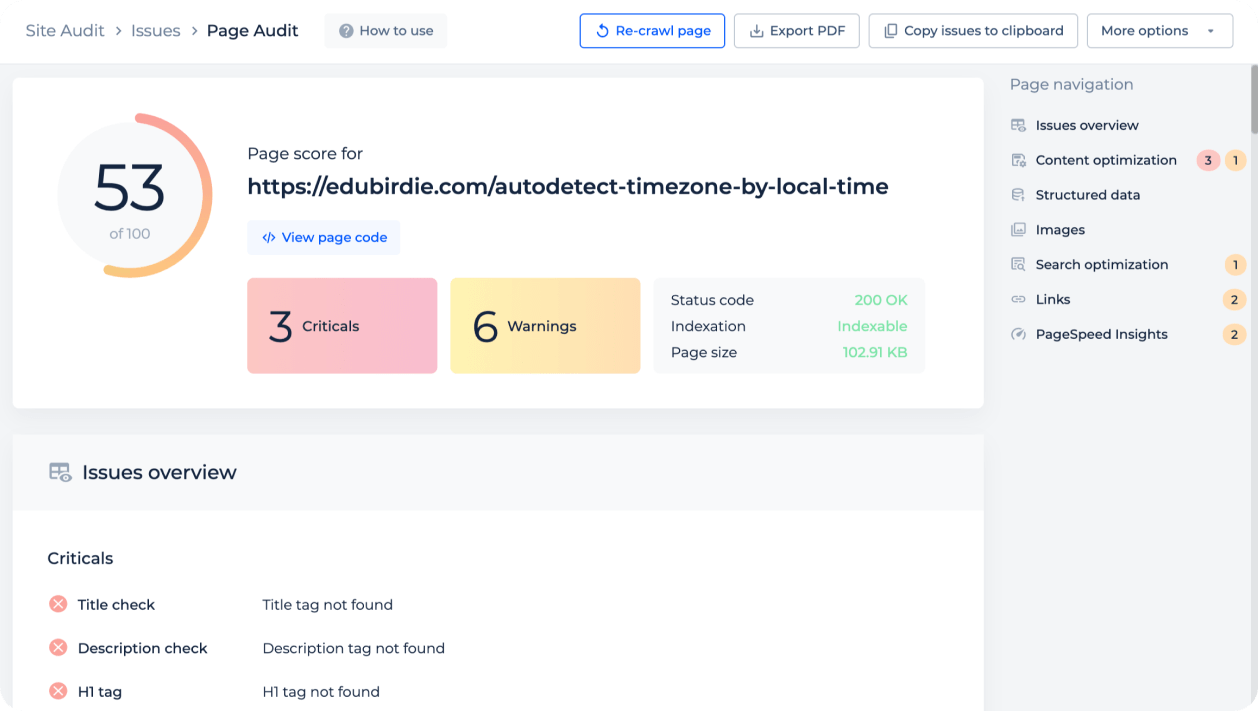
Launch on-page SEO audit for top pages
Get a quick overview of the issues that the specific page has. Test meta tags, content relevance, structured data, images, links, and PageSpeed Insights.
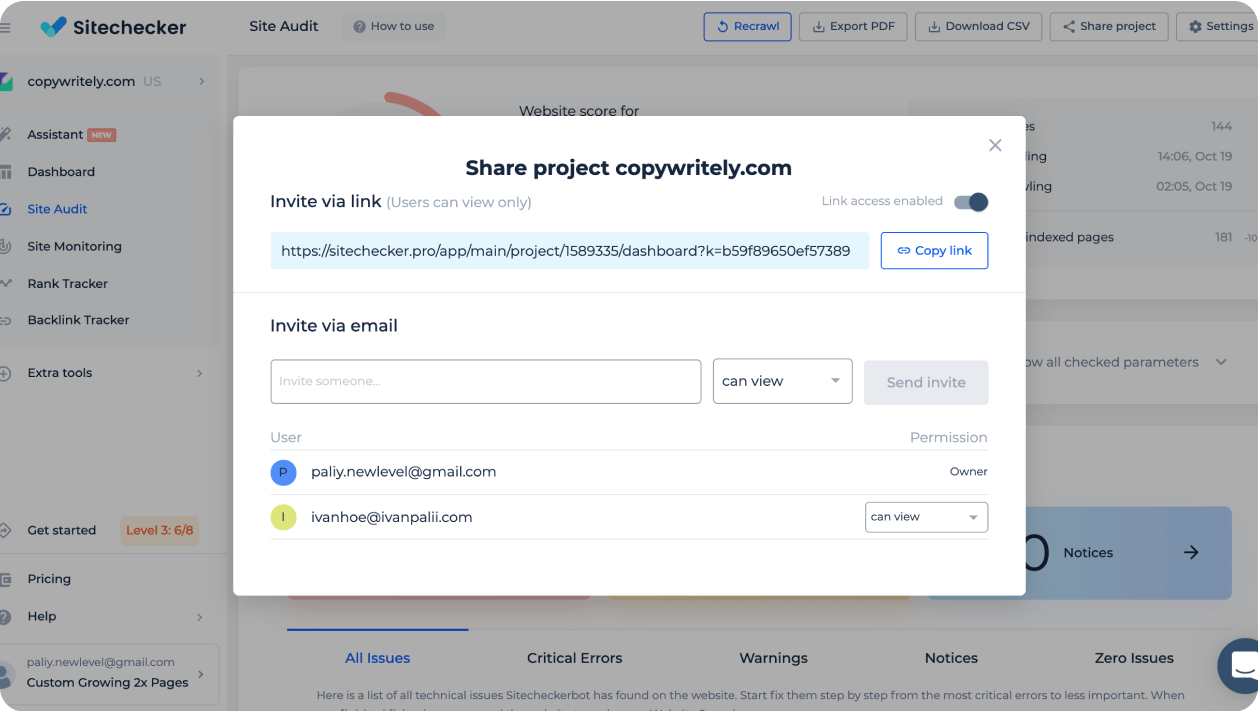
Invite teammates and freelancers
Delegate technical errors to your subordinates or contractors. Simply provide access to the project via link or email and recrawl a website when the work is finished.
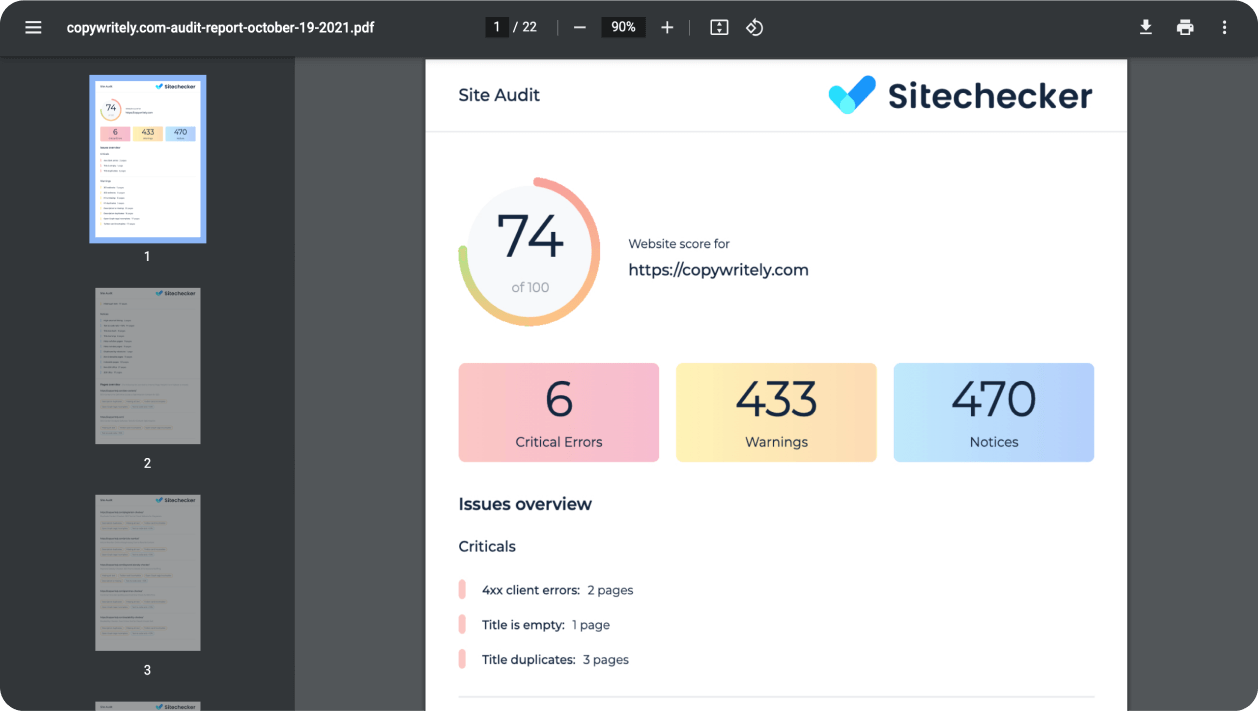
Export branded PDF reports
Add your logo to download branded PDF files. Use these summaries as a lead generator or work progress report.
Checklists on how to use the website crawler for any purpose
Join the 1,000+ businesses growing with Sitechecker





