



Il file Robots.txt serve a fornire dati preziosi ai sistemi di ricerca che eseguono la scansione del Web. Prima di esaminare le pagine del tuo sito, i robot di ricerca eseguono la verifica di questo file. A causa di tale procedura, possono migliorare l’efficienza della scansione. In questo modo aiuterai i sistemi di ricerca a eseguire l’indicizzazione dei dati più importanti sul tuo sito. Ma questo è possibile solo se hai correttamente configurato robots.txt.
Proprio come le direttive del generatore di file robots.txt, l’istruzione noindex nei robot meta tag non è altro che una semplice raccomandazione per i robot. Questo è il motivo per cui non possono garantire che le pagine chiuse non saranno indicizzate e non saranno incluse nell’indice. Le garanzie in questa preoccupazione sono fuori luogo. Se è necessario chiudere per l’indicizzazione alcune parti del proprio sito, è possibile utilizzare una password per chiudere le directory.
Sintassi principale
User-Agent: il robot a cui verranno applicate le seguenti regole (ad esempio, “Googlebot”)
Disallow: le pagine che si desidera chiudere per l’accesso (quando si inizia ogni nuova riga è possibile includere una grande lista delle direttive allo stesso modo)
Ogni gruppo User-Agent / Disallow dovrebbe essere diviso con una riga vuota. Ma le stringhe non vuote non dovrebbero verificarsi all’interno del gruppo (tra User-Agent e l’ultima direttiva Disallow).
Hash mark (#) può essere utilizzato quando necessario per lasciare commenti nel file robots.txt per la riga corrente. Qualsiasi cosa menzionata dopo il segno cancelletto verrà ignorata. Quando si lavora con il generatore di file txt robot, questo commento è applicabile sia per l’intera linea che alla fine di esso dopo le direttive.
Cataloghi e nomi di file sono sensibili al registro: il sistema di ricerca accetta “Catalogo”, “catalogo” e “CATALOGO” come diverse direttive.
Host: viene utilizzato per Yandex per indicare il sito mirror principale. Ecco perchè se esgui il redirect 301 per pagina per incollare due siti, non è necessario ripetere la procedura per il file robots.txt (sul sito duplicato). Pertanto, Yandex rileverà la direttiva citata sul sito che deve essere bloccata.
Crawl-delay: puoi limitare la velocità del tuo attraversamento del sito che è di grande utilità in caso di alta frequenza di frequenza sul tuo sito. Tale opzione è abilitata a causa della protezione del generatore di file robot.txt da ulteriori problemi con un carico aggiuntivo del server causato da diversi sistemi di ricerca che elaborano le informazioni sul sito.
Frasi regolari: per fornire impostazioni di direttive più flessibili, puoi utilizzare due simboli menzionati di seguito:
* (star) – significa qualsiasi sequenza di simboli,
$ (dollar sign) – sta per la fine del rigo.
Esempi principali di uso del robots.txt generator
Divieto dell’intera indicizzazione del sito
User-agent: *
Disallow: /Questa istruzione deve essere applicata quando si crea un nuovo sito e si utilizzano i sottodomini per fornire l’accesso ad esso.
Molto spesso quando si lavora su un nuovo sito, gli sviluppatori Web dimenticano di chiudere alcune parti del sito per l’indicizzazione e, di conseguenza, i sistemi di indicizzazione ne elaborano una copia completa. Se si verifica tale errore, il dominio principale deve essere sottoposto a reindirizzamento 301 per pagina. Il generatore di Robot.txt può essere di grande utilità!
Il costrutto seguento PERMETTE di indicizzare l’intero sito:
User-agent: *
Disallow:
Escludere l’indicizzazione di una determinata cartella
User-agent: Googlebot
Disallow: /no-index/
Divieto di visitare la pagina per un certo robott
User-agent: Googlebot
Disallow: /no-index/this-page.html
Divieto di indicizzare determinati tipi di file
User-agent: *
Disallow: /*.pdf$
Per consentire una visita alla pagina determinata per un determinato robot web
User-agent: *
Disallow: /no-bots/block-all-bots-except-rogerbot-page.html
User-agent: Yandex
Allow: /no-bots/block-all-bots-except-Yandex-page.html
Link sito alla sitemap
User-agent: *
Disallow:
Sitemap: http://www.example.com/none-standard-location/sitemap.xml
Peculiarità da tenere in considerazione quando si utilizza questa direttiva se si riempie costantemente il proprio sito di contenuti unici:
- non aggiungere un collegamento alla Sitemap nel generatore di file txt di robot;
- scegli un nome non standardizzato per la mappa del sito di sitemap.xml (ad esempio my-new-sitemap.xml e quindi aggiungi questo link ai sistemi di ricerca usando i webmaster);
perché un gran numero di webmaster abusivi analizzano il contenuto da altri siti ma sono i loro e li usano per i propri progetti.
Controlla le pagine del tuo sito web per lo stato di indicizzazione Rileva tutti gli URL senza indirizzo e scopri quali pagine del sito possono essere scansionate dai robot dei motori di ricerca
È meglio generatore robots txt generator o noindex?
Se non vuoi che alcune pagine vengano sottoposte a indicizzazione, è meglio consigliare noindex nei robot meta tag. Per implementarlo, è necessario aggiungere i seguenti meta tag nella sezione della tua pagina:
<meta name=”robots” content=”noindex, follow”>Usando questo approccio, otterrai:
- evitare l’indicizzazione di determinate pagine durante la visita successiva del robot Web (non sarà quindi necessario eliminare manualmente la pagina utilizzando i webmaster);
- riesci a comunicare il succo di collegamento della tua pagina.
Robots txt file generator serve meglio per chiudere tali tipi di pagine:
- pagini amministrative del tuo sito;
- dati di ricerca del sito;
- pagina di registrazione/autorizzazione/reset password.
Quali strumenti e come possono aiutarti per fare un check del file robots.txt?
Quando generi robots.txt, devi verificare se contengono errori. Il controllo robots.txt dei sistemi di ricerca può aiutarti a far fronte a questa attività:
Fai il login al tuo account per confermare il sito attuale sulla piattaforma, passare ai Crawl and poi al robots.txt Tester.
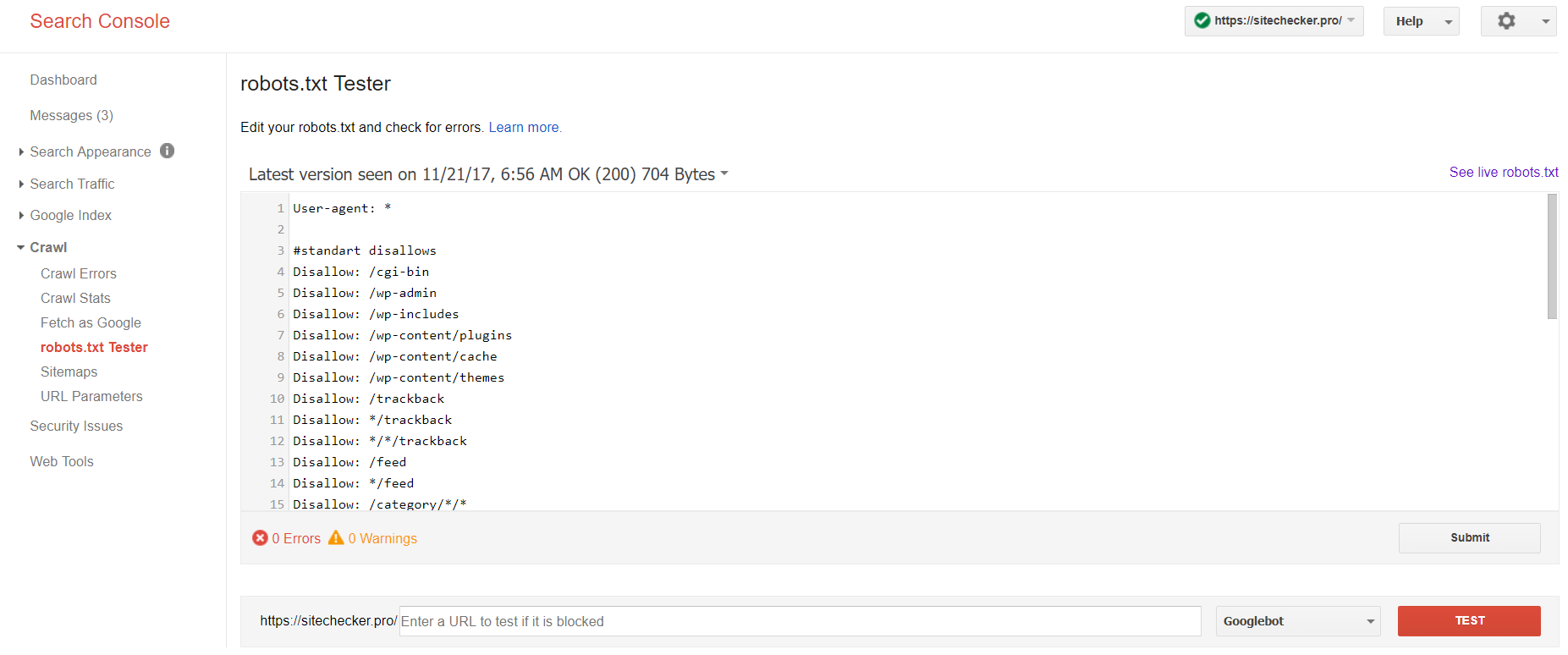
Questo robot txt test ti permette di:
- Rileva tutti i tuoi errori e possibili problemi contemporaneamente;
- controlla gli errori e apporta le correzioni necessarie qui per installare il nuovo file sul tuo sito senza ulteriori verifiche;
- esamina se hai giustamente chiuso le pagine che desideri evitare l’indicizzazione e se quelle che dovrebbero essere sottoposte a indicizzazione sono adeguatamente aperte.
Entra nel tuo account con il sito confermato sulla piattaforma, passa a Tools poi a Robots.txt analysis.
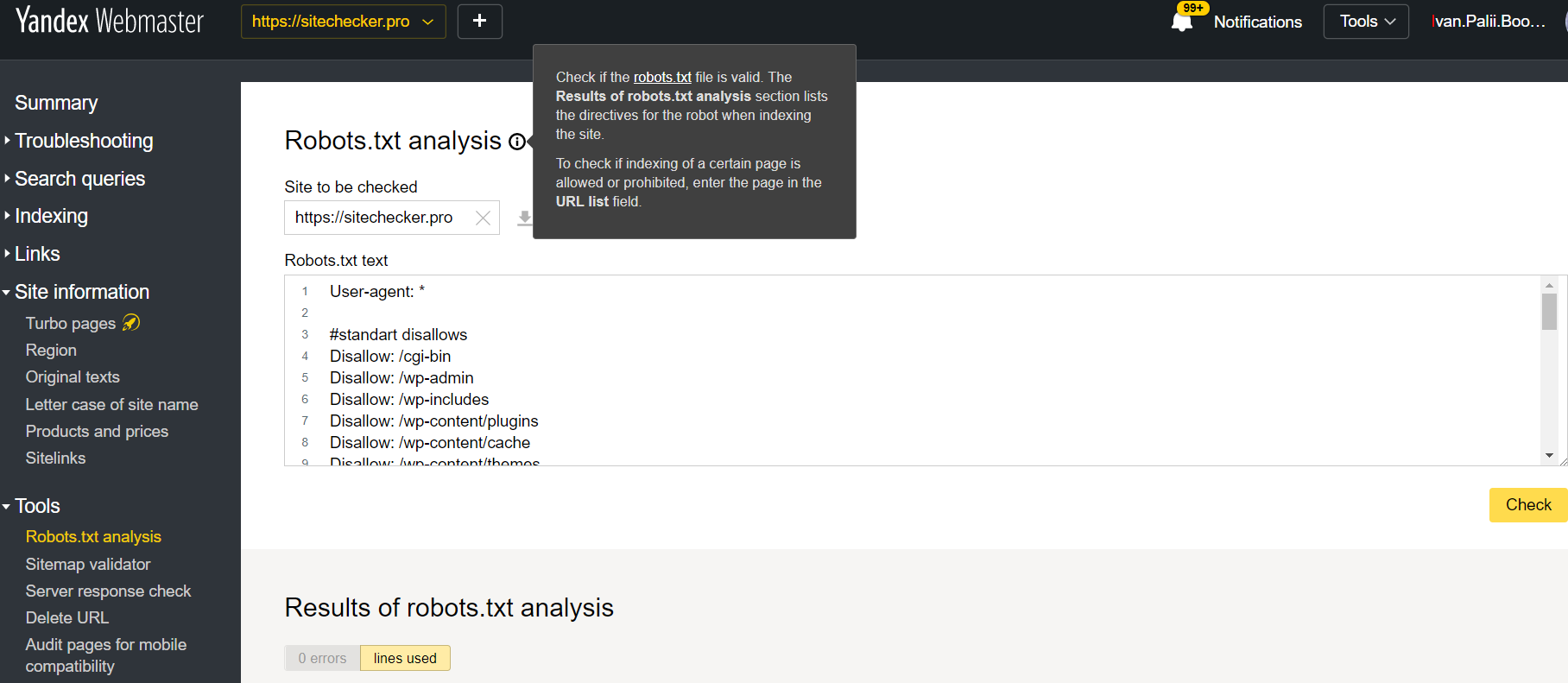
Questo tester offre quasi le stesse opportunità di verifica come quella sopra descritta. La differenza risiede in:
- qui non è necessario autorizzare e provare i diritti per un sito che offre una verifica immediata del tuo file robots.txt;
- non è necessario inserire per pagina: l’intero elenco di pagine può essere controllato all’interno di una sessione
- puoi assicurarti che Yandex abbia correttamente identificato le tue istruzioni.





