



O arquivo Robots.txt serve para fornecer dados valiosos aos sistemas de busca que escaneiam a Web. Antes de examinar as páginas o seu site, os robôs de busca executam a verificação desse arquivo. Devido a esse procedimento, eles podem aumentar a eficiência da exploração. Desta forma, você pode ajudar a procurar sistemas que executem primeiro a indexação dos dados mais importantes em seu site. Mas isso só é possível se você configurar corretamente o robots.txt.
Assim como as diretrizes do gerador de arquivos robots.txt, a instrução noindex nos robôs meta-tag não são mais que apenas recomendações. Essa é a razão pelas qual eles não podem garantir que as páginas fechadas não sejam indexadas e não sejam incluídas no índice. Garantias dessa natureza são descabidas. Se você precisa fechar alguma parte do seu site para indexação, você pode usar uma senha para fechar diretórios.
Sintaxe Principal
Agente Usuário: o robô ao qual serão aplicadas as regras a seguir (por exemplo: “Googlebot”)
Proibição: as páginas que se deseja fechar para acesso (ao iniciar cada nova linha, você pode incluir uma enorme lista de diretrizes).
Todo Grupo Agente Usuário / Proibição deve ser dividido com um espaço em branco. Mas as cadeias não vazias não devem ocorrer dentro dos grupos (entre agente usuário e a última diretiva proibição).
Marca Jogo da Velha (#) pode ser usada quando necessário para deixar comentários no arquivo robots.txt na linha corrente. Qualquer coisa mencionada após a marca jogo da velha será ignorada. Quando você trabalha com o gerador de arquivos robot txt, este comentário é aplicável tanto em toda a linha quanto no final após as diretrizes.
Catálogos e nomes de arquivos são sensíveis ao registro: o sistema de busca reconhece “Catálogo”, “catálogo” e “CATÁLOGO” como diretrizes diferentes.
Host: é usado pelo Yandex para apontar o principal site-espelho. É por isso que se você executar o redirecionamento 301 por página para manter dois sites, não haverá necessidade de repetir o procedimento para o arquivo robots.txt (no site duplicado). Assim, a Yandex irá detectar a diretriz mencionada no site que precisa estar associado.
Atraso de Rastreamento: você pode limitar a frequência do seu site, o que é muito útil em caso de alta frequência de atendimento em seu site. Essa opção é ativada devido à proteção do gerador de arquivos robot.txt para problemas adicionais com uma carga extra do servidor provocada pelos diversos sistemas de busca que processam as informações no site.
Frases Regulares: para fornecer configurações mais flexíveis de diretrizes, você pode usar dois símbolos mencionados abaixo:
* (estrela) – significa qualquer sequência de símbolos,
$ (símbolo do dólar) – significa fim de linha.
Principais exemplos de uso de gerador Robots.txt
Proibir toda indexação do site
Agente Usuário: *
Proibição: /Esta instrução precisa ser aplicada quando você cria um novo site, usa subdomínios e quer fornecer acesso a eles. Você testar site quanto à confiabilidade.
Muitas vezes, ao trabalhar em um site novo, os desenvolvedores da Web esquecem de fechar alguma parte do site para a indexação e, como resultado, os sistemas de index processam uma cópia completa dele. Se o erro ocorreu, deu domínio principal precisa ser submetido a um redirecionamento 301 por página. O Gerador Robot.txt pode ser de grande utilidade!
A seguinte construção PERMITE a indexação de um site inteiro:
Agente Usuário: *
Proibição:
Proibir a indexação de uma página específica:
Agente Usuário: Googlebot
Proibição: / no-index/
Proibir a visita à página por um determinado robô
Agente Usuário: Googlebot
Proibição: / no-index/this-page.html
Proibir a indexação de certo tipo de arquivo
Agente Usuário: *
Proibição: /*.pdf$
Permitir a visita a uma determinada página por um determinado web robô
Agente Usuário: *
Proibição:/no-bots/block-all-bots-except-rogerbot-page.html
Agente Usuário: Yandex
Permitir: /no-bots/block-all-bots-except-Yandex-page.html
Link do site para o sitemap
Agente Usuário: *
Proibição:
Sitemap: http://www.example.com/none-standard-location/sitemap.xml
Peculiaridades que se deve levar em consideração ao usar essa diretiva se você estiver constantemente preenchendo seu site com conteúdo exclusivo:
- Não adicione um link ao seu mapa do site no gerador de arquivo robots txt;
- escolha um nome não padronizado para o mapa do site do sitemap.xml (por exemplo, my-new-sitemap.xml e, em seguida, adicione este link aos sistemas de pesquisa usando webmasters);
porque muitos webmasters desleais analisam o conteúdo de outro site, dos seus próprios e os usam para seus próprios projetos.
Verifique as páginas do seu site para o status de indexação Detectar todos os URLs não indexados e descobrir quais páginas do site podem ser rastreadas pelos robôs do mecanismo de pesquisa
Qual é o melhor gerador de robô TXT ou noindex?
Se você não quiser que algumas páginas sejam submetidas a indexação, o noindex em robôs meta-tags é mais aconselhável. Para implementá-lo, você precisa adicionar a seguinte meta-tag na seção de sua página:
<meta name=”robots” content=”noindex, follow”>Usando essa abordagem, você irá:
- evitar a indexação de determinada página durante a próxima visita do robô web (você não precisará, em seguida, excluir a página manualmente usando webmasters);
- gerenciar a transmissão link juice da sua página.
O gerador de arquivos txt do Robots serve para fechar melhor esses tipos de páginas:
- páginas administrativas do seu site;
- pesquisas de dados no site;
- páginas de registro/autorização/redefinição de senha.
Quais as ferramentas e como isso pode ajudá-lo a verificar arquivos robots.txt?
Quando você gera Robots.txt, você precisa verificar se ele contém erros. A verificação robots.txt do sistema de pesquisa pode lhe ajudar a concretizar essa tarefa:
Faça o login na conta do site corrente confirmando sua plataforma, clique em Rastrear e, em seguida, Robots.txt tester.
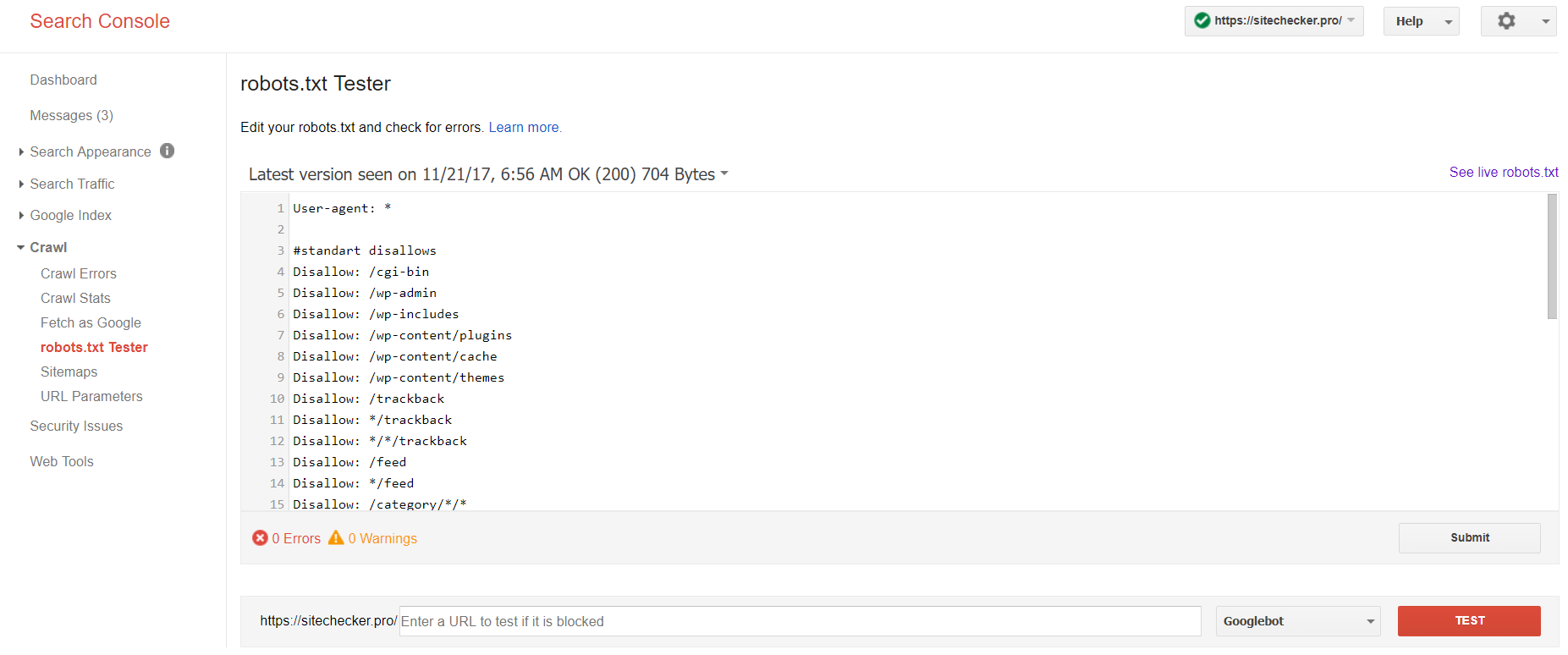
Este teste txt do robô permite que você:
- detecte todos os erros e problemas possíveis ao mesmo tempo;
- verifique os erros e faça as correções necessárias para instalar um novo arquivo em seu site sem verificações adicionais;
- examine se você fechou adequadamente as páginas que você deseja evitar, a indexação, e se as que devem ser indexadas estão apropriadamente abertas.
Faça o login na conta do site corrente confirmando sua plataforma, clique em Ferramentas e, em seguida, Robots.txt. analysis.
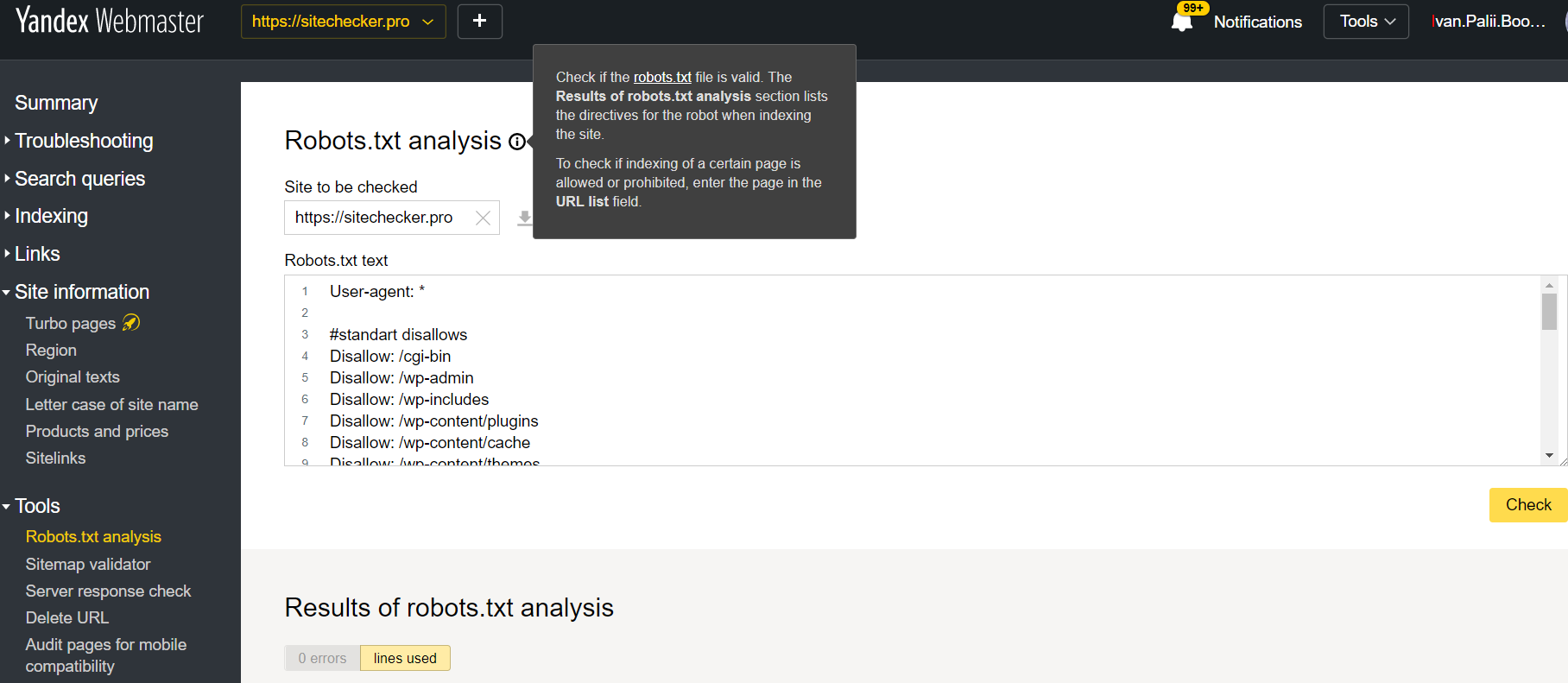
Este teste oferece quase as mesmas oportunidades de verificação já vistas acima. A diferença está em:
- aqui você não precisa autorizar ou aprovar os direitos de um site que oferece uma verificação imediata do seu arquivo robots.txt;
- não há necessidade de uma análise por página: toda a lista de páginas será verificada dentro da sessão;
- você terá certeza de que o Yandex identificou adequadamente suas instruções.




