



Los archives Robots.txt sirven para proveer datos valiosos al sistema de escaneo de búsquedas de una web. Antes de examinar las páginas de tu sitio, los robots de búsquedas llevan a cabo la verificación de este archivo. Debido a tal procedimiento, estos pueden mejorar la eficiencia del proceso de escaneo. De esta manera puedes ayudar a los sistemas de búsquedas a ejecutar primeramente la indexación de los datos más importantes en tu página. Pero esto sólo es posible si configuras correctamente el archivo robots.txt. Al igual que las directrices del generador de archivos robots.txt, la instrucción noindex en la meta etiqueta dirigida a los robots no es más que una recomendación para los bots. Esa es la razón por la que no pueden garantizar que las páginas cerradas no serán indexadas y no serán incluidas en el índice. Las garantías están fuera de lugar en este sentido. Si necesitas cerrar la indexación de alguna parte de tu sitio, puedes usar una contraseña para cerrar ese directorio.
Sintaxis principal
User-Agent: el bot al cual le serán aplicadas las siguientes reglas (por ejemplo: Googlebot).
Disallow: las páginas a las que deseas cerrar el acceso (al inicio de cada línea puedes incluir una larga lista de directrices semejantes).
Cada grupo User-Agent / Disallow debe ser dividido con una línea en blanco. Pero dentro del grupo no debe haber cadenas vacías (entre User-Agent y la última línea del comando Disallow).
Hash mark o Numeral (#): puede ser usado cuando necesitamos dejar comentarios en el archive robots.txt para esa línea. Cualquier cosa mencionada después del numeral será ignorada. Cuando trabajar con un generador archivos robots.txt, este comentario es aplicable a ambas,
tanto para la línea como para el final contenido luego de las directrices.
Catálogos y nombres de archivos son sensibles al registro: los sistemas de búsquedas aceptan «Catalogo», «catalogo», and «CATALOGO» como instrucciones diferentes.
Host:: es usado por Yandex señalar el sitio espejo. Es por esto que si aplicas una redirección 301 por página para mantener dos sitios juntos, no hay necesidad de repetir el procedimiento para el archivo robots.txt (en el sitio duplicado). En consecuencia, Yandex detectará la directriz mencionada en el sitio web que necesita ser adherido.
Crawl-delay: puedes limitar la velocidad de desplazamiento de tu sitio web, lo cual es de gran utilidad si tienes una gran audiencia en tu sitio. Tales opciones están disponibles dada la protección del generador de archivos robots.txt de problemas adicionales con una carga extra de tu servidor, la cual es causada porque diversos sistemas de búsqueda están procesando información de tu sitio web.
Frases regulares: para configurar de una manera más flexible las directrices, pues usar dos símbolos mencionados a continuación:
* (asterisco) – significa cualquier secuencia de símbolos,
$ (signo de dólar) representa en final de la fila.
Principales ejemplos del uso del generador robots.txt
Prohibición de indexación del sitio entero
User-agent: *
Disallow: /Esta instrucción necesita ser aplicada cuando se crea un Nuevo sitio y usa sub dominios para proveer el acceso al mismo. Al trabajar en un sitio nuevo, es muy común que los desarrolladores web olviden cerrar para indexación algunas partes del sitio, y como resultado, los sistemas de indexación procesarán una copia completa del mismo. Si ocurre tal error, tu dominio maestro necesita ser sometido a una redirección de tipo 301. ¡Un Robot.txt puede ser de gran uso aquí!
El siguiente comando permite la indexación del sitio completo:
User-agent: *
Disallow:
Prohibición de indexación de una carpeta en particular
User-agent: Googlebot
Disallow: /no-index/
Prohibición de visitas a la página a cierto tipo de robot
User-agent: Googlebot
Disallow: /no-index/this-page.html
Prohibición de indexación de cierto tipo de archivo
User-agent: *
Disallow: /*.pdf$
Para permitir una visita a la página determinada para un determinado robot web
User-agent: *
Disallow: /no-bots/block-all-bots-except-rogerbot-page.html
User-agent: Yandex
Allow: /no-bots/block-all-bots-except-Yandex-page.html
Sitio web enlazado al sitemap
User-agent: *
Disallow:
Sitemap: http://www.example.com/none-standard-location/sitemap.xml
Peculiaridades a tomar en cuenta cuando se usan estas directrices si constantemente estás llenando tu sitio con contenido único:
- No añadas un enlace a tu sitemap en un generador de archivos robots.txt;
- Escoge algunos nombres no estandarizados o poco comunes para llamar al sitemap o sitemap.xml (por ejemplo: mi-nuevo-sitemap.xml y entonces añade este enlace al sistema de búsquedas usando el webmaster)
Esto se debe a que una gran cantidad de webmasters desleales analizan el contenido de otros sitios que no sean los suyos y los utilizan para sus propios proyectos.
Compruebe las páginas de su sitio web para el estado de indexación Detecte todas las URL no indexadas y descubra qué páginas de sitios pueden ser rastreadas por los robots de los motores de búsqueda
¿Qué es mejor? ¿Generador Robots.txt o Noindex?
Si no quieres que alunas páginas sean indexadas, el noidex como meta etiqueta es lo más recomendable. Para implementarla, necesitas añadir la siguiente metaetiqueta en tu página:
<meta name=”robots” content=”noindex, follow”>Usando este abordaje podrás:
- Evitar las indexación de ciertas páginas durante la visita del robot web (no habrá necesidad de borrar las páginas manualmente usando un webmaster);
- Administrar para transmitir el link juice de tu página.
Los creadores de archivos Robots.txt funcionan mejor para cerrar este tipo de páginas:
- Páginas administrativas de tu sitio;
- Buscar datos en el sitio;
- Páginas de registro, autorización y/o cambio de clave.
¿Qué herramientas y cómo estas puede ayudarme a revisar el archivo robots.txt?
Cuando generas robots.txt necesitas verificar si estos contienen algún error. Los robots.txt de los sistemas de búsqueda pueden ayudarte a hacer frente a estas tareas:
Google Webmasters
Inicia sesión en la cuenta con el sitio actual confirmado en su plataforma, luego ve a Rastreo Crawl y entonces ve a Robots.txt Tester.
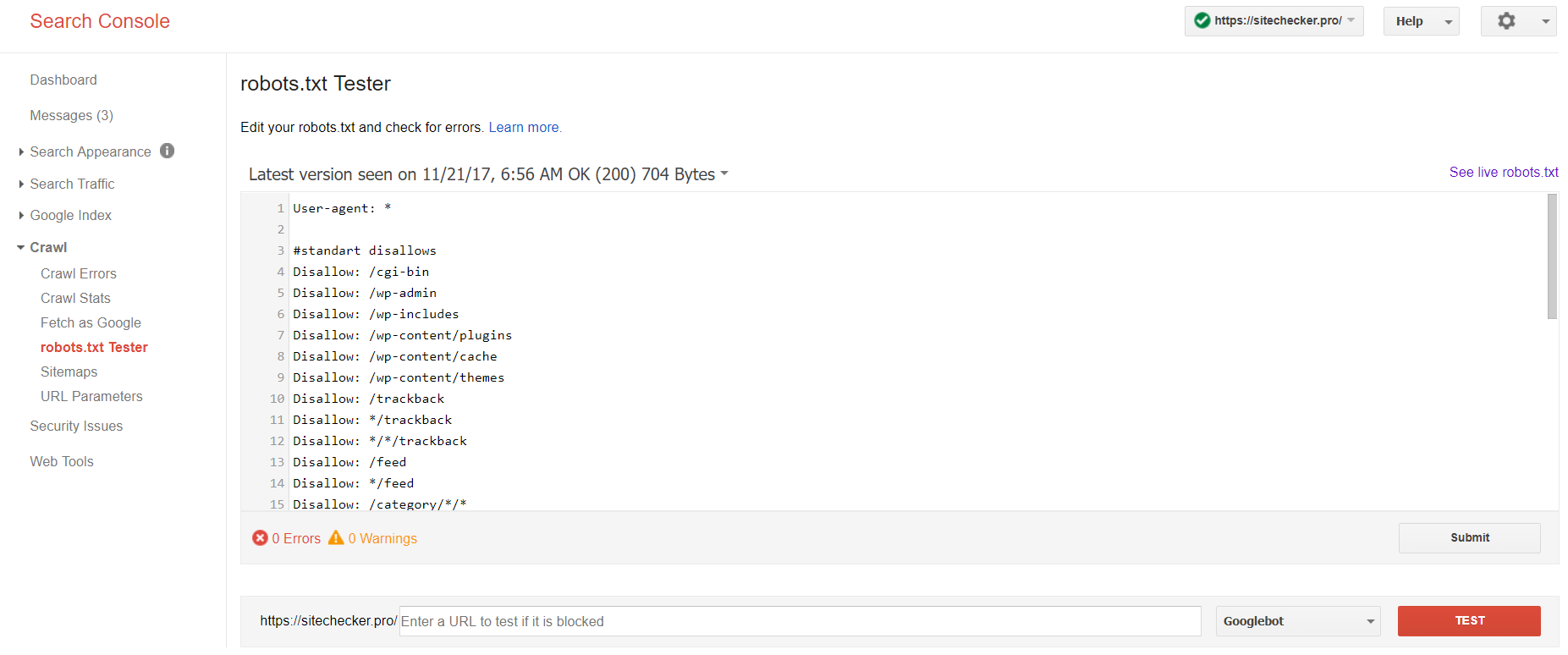
Esta prueba de Robots.txt te permite:
- Detectar todos los errores y posibles problemas de una sola vez;
- Revisar en busca de errores y hacer las correcciones necesarias allí mismo para instalar todos los archivos nuevos en tu sitio sin ninguna verificación adicional;
- Examinar si has cerrado apropiadamente las páginas que te gustaría evitar que sean indexadas y si esas que se supone van a ir a indexación estas abiertas apropiadamente.
Yandex Webmaster
Inicia sesión en la cuenta con el sitio actual confirmado en su plataforma, luego ve a Tools y entonces ve a análisis de Robots.txt.
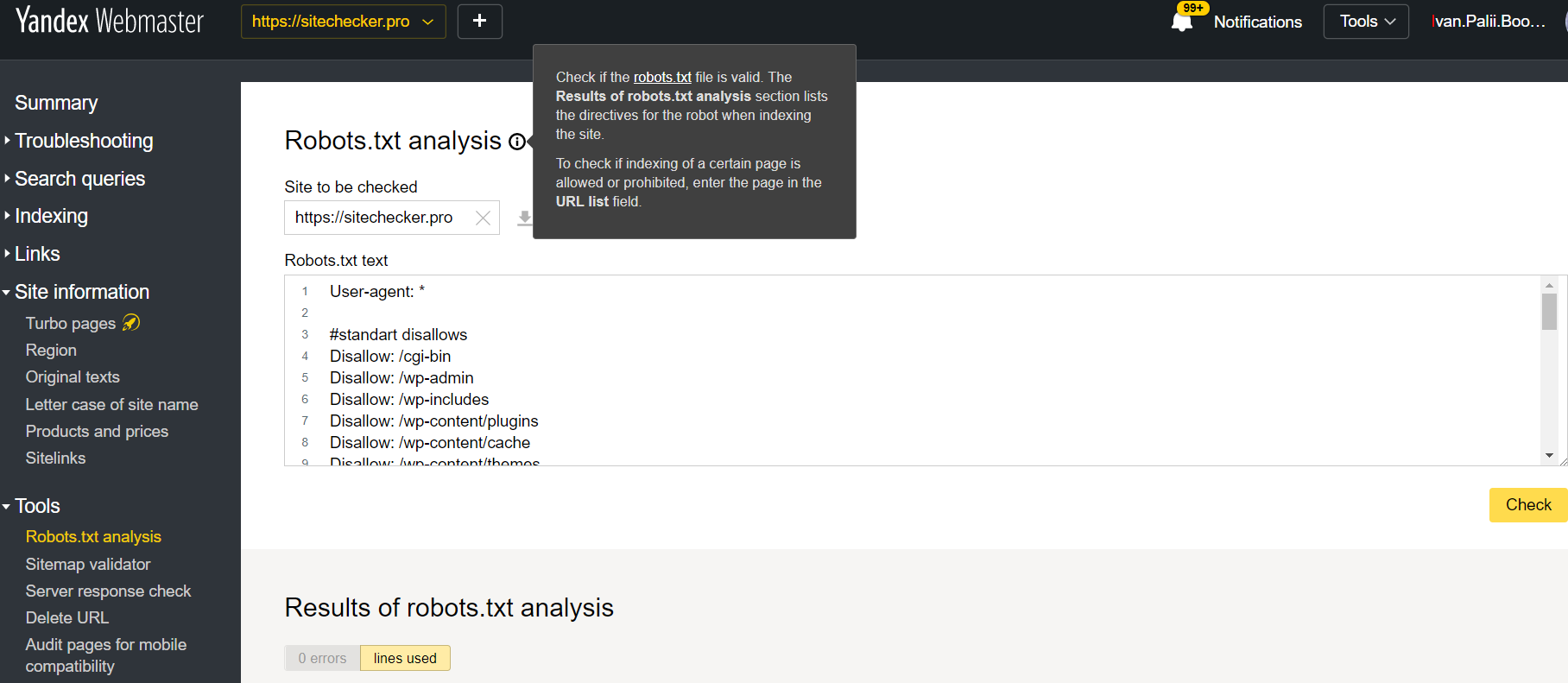
Este auditor ofrece casi las mismas oportunidades de verificación que el descrito anteriormente, la diferencia reside en:
- Aquí no necesitas autorizar y probar los derechos de un sitio que ofrece una verificación directa de tu archivo robots.txt;
- No hay necesidad alguna de insertar cada página: la lista entera de páginas puede ser revisada en sólo una sesión;
- Puedes estar seguro que Yandex identificará adecuadamente tus instrucciones.





