



Plik Robots.txt służy do dostarczania cennych danych do systemów wyszukiwania skanujących sieć. Przed sprawdzeniem stron Twojej witryny roboty wyszukujące przeprowadzają weryfikację tego pliku. Dzięki takiej procedurze mogą zwiększyć wydajność skanowania. W ten sposób pomagasz przeszukiwać systemy, aby najpierw przeprowadzić indeksację najważniejszych danych w witrynie. Ale jest to możliwe tylko wtedy, gdy poprawnie skonfigurowałeś robots.txt.
Podobnie jak dyrektywy generatora plików robots.txt, instrukcja noindex w robotach metatag nie jest niczym innym, jak tylko zaleceniem dla robotów. Z tego powodu nie mogą zagwarantować, że zamknięte strony nie zostaną zindeksowane i nie zostaną uwzględnione w indeksie. Gwarancje w tym zakresie są nie na miejscu. Jeśli chcesz zamknąć indeksację jakiejś części witryny, możesz użyć hasła, aby zamknąć katalogi.
Główna Składnia
User-Agent: robot, do którego zostaną zastosowane następujące reguły (na przykład „Googlebot”). Ciąg agenta użytkownika jest parametrem używanym przez przeglądarki internetowe jako ich nazwa. Ale zawiera nie tylko nazwę przeglądarki, ale także wersję systemu operacyjnego i inne parametry. Ze względu na agenta użytkownika można określić wiele parametrów: nazwę systemu operacyjnego, jego wersję; sprawdź urządzenie, na którym jest zainstalowana przeglądarka; zdefiniuj funkcje przeglądarki.
Disallow: strony, które chcesz zamknąć w celu uzyskania dostępu (podczas rozpoczynania każdej nowej linii możesz dołączyć dużą listę dyrektyw)
Każda grupa User-Agent / Disallow powinna być podzielona pustą linią. Ale niepusty łańcuch nie powinien występować w grupie (między User-Agent a ostatnią dyrektywą Disallow).
Znak skrótu (#) może być użyty, gdy trzeba zostawić komentarze w pliku robotów dla bieżącej linii. Wszystko, co zostało wspomniane po znaku skrótu, zostanie zignorowane. Podczas pracy z generatorem plików robota txt komentarz ten dotyczy zarówno całej linii, jak i jej końca po dyrektywach.
Katalogi i nazwy plików są sensowne z rejestru: system wyszukiwania akceptuje «Katalog», «katalog» i «KATALOG» jako różne dyrektywy.
Host: jest używany przez Yandex do wskazania głównej strony lustrzanej. Dlatego jeśli wykonasz przekierowanie 301 na stronę, aby skleić dwie witryny, nie ma potrzeby powtarzania procedury dla pliku robots.txt (na zduplikowanej stronie). Tak więc Yandex wykryje wspomnianą dyrektywę na stronie, która musi zostać zablokowana.
Opóźnienie indeksowania plików: możesz ograniczyć szybkość przechodzenia przez witrynę, co jest bardzo przydatne w przypadku wysokiej częstotliwości odwiedzin witryny. Taka opcja jest włączona ze względu na ochronę generatora plików robot.txt przed dodatkowymi problemami z dodatkowym obciążeniem serwera spowodowanym przez różne systemy wyszukiwania przetwarzające informacje na stronie.
Regularne wyrażenia: aby zapewnić bardziej elastyczne ustawienia dyrektyw, możesz użyć dwóch symboli wymienionych poniżej:
* (gwiazda) – oznacza dowolną sekwencję symboli,
$ (znak dolara) – oznacza koniec linii.
Główne przykłady użycia generatora robots.txt
Zakaz całej indeksacji witryny
User-agent: *Disallow: /Instrukcja ta musi być stosowana podczas tworzenia nowej witryny i korzystania z subdomen, aby zapewnić do niej dostęp.
Bardzo często podczas pracy na nowej stronie programiści zapominają zamknąć część strony w celu indeksacji, w wyniku czego systemy indeksu przetwarzają jej pełną kopię. Jeśli taki błąd miał miejsce, twoja domena główna musi przejść przekierowanie 301 na stronę. Generator Robot.txt może być przydatny!
Następujące ZEZWOLENIA na budowę do indeksowania całej witryny:
User-agent: *Disallow:Zakaz indeksowania określonego folderu
User-agent: GooglebotDisallow: /no-index/Zakaz wizyty na stronie dla pewnego robota
User-agent: GooglebotDisallow: /no-index/this-page.htmlZakaz indeksowania plików określonego typu
User-agent: *Disallow: /*.pdf$Aby umożliwić wizytę na określonej stronie dla określonego robota internetowego
User-agent: *Disallow: /no-bots/block-all-bots-except-rogerbot-page.htmlUser-agent: GoogleAllow: /no-bots/block-all-bots-except-Google-page.htmlLink do strony internetowej mapy witryny
User-agent: *Disallow:Sitemap: http://www.example.com/none-standard-location/sitemap.xmlOsobliwości, które należy wziąć pod uwagę podczas korzystania z tej dyrektywy, jeśli stale wypełniasz swoją witrynę unikalną treścią:
- nie dodawaj linku do mapy witryny w generatorze plików tekstowych robotów;
- wybierz niestandaryzowaną nazwę mapy witryny sitemap.xml (na przykład my-new-sitemap.xml, a następnie dodaj ten link do systemów wyszukiwania za pomocą webmasterów);
ponieważ wielu nieuczciwych webmasterów analizuje zawartość z innych stron, ale samodzielnie i używa ich do własnych projektów.
Sprawdź strony swojej witryny pod kątem statusu indeksacji Wykryj wszystkie nieindeksowane adresy URL i dowiedz się, jakie strony witryny mogą być indeksowane przez boty wyszukiwarki
Który jest lepszy generator txt robotów lub noindex?
Jeśli nie chcesz, aby niektóre strony były indeksowane, noindex w robotach metatagowych jest bardziej wskazany. Aby go wdrożyć, musisz dodać następujący metatag w sekcji strony:
<meta name=”robots” content=”noindex, follow”>Korzystając z tego podejścia, będziesz:
- unikać indeksowania określonej strony podczas następnej wizyty robota internetowego (nie będziesz musiał wtedy ręcznie usuwać strony za pomocą webmasterów);
- zdołasz przekazać link do soku na stronie.
Generator plików robotów txt lepiej zamyka takie typy stron:
- strony administracyjne Twojej witryny;
- wyszukiwanie danych na stronie;
- strony resetowania rejestracji / autoryzacji / hasła.
Jakie narzędzia sprawdzające robots.txt mogą pomóc?
Kiedy generujesz plik robots.txt, musisz sprawdzić, czy zawierają jakieś błędy. Kontrola robots.txt systemów wyszukiwania może pomóc Ci poradzić sobie z tym zadaniem:
Google Webmasters
Zaloguj się na konto z potwierdzoną bieżącą witryną na swojej platformie, przejdź do Crawl, a następnie do robots.txt Tester.
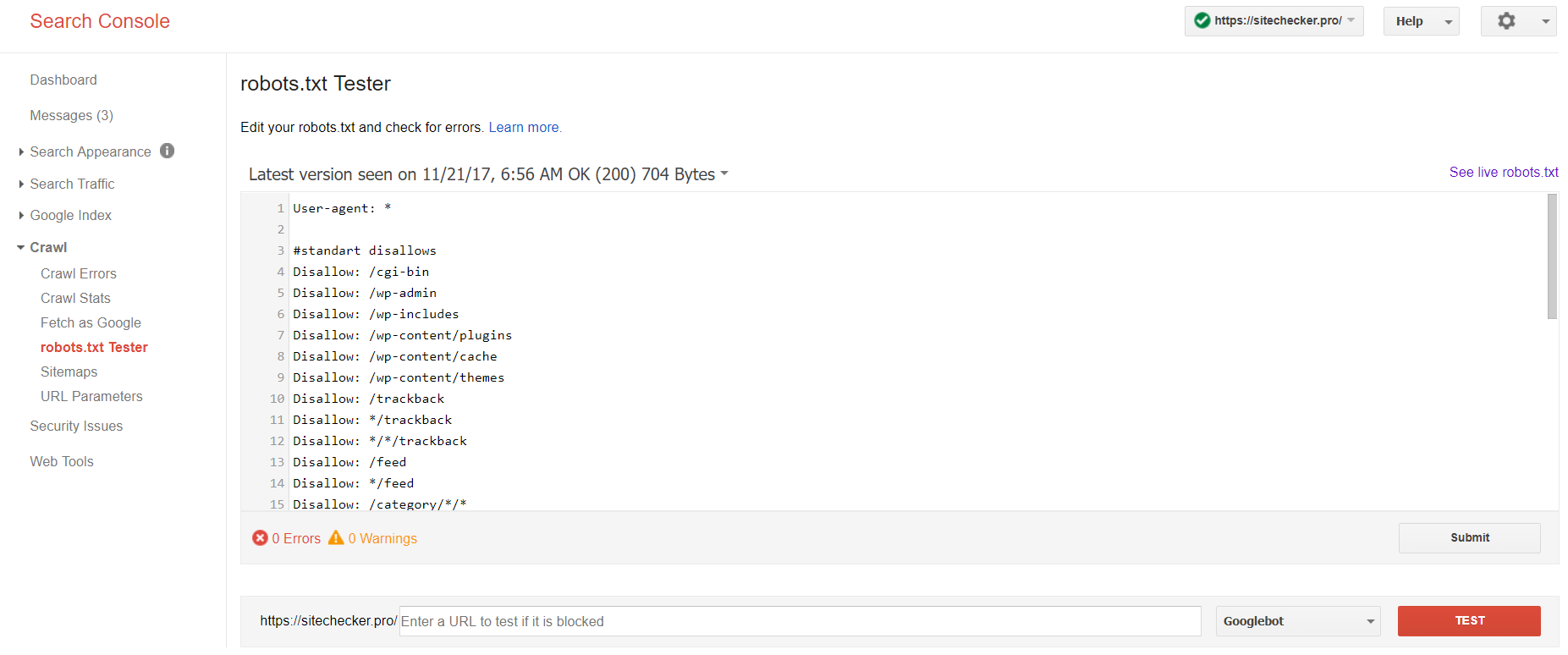
Ten test crawler pozwala na:
- wykrywać wszystkie swoje błędy i możliwe problemy na raz;
- sprawdźić błędy i dokonaj niezbędnych poprawek tutaj, aby zainstalować nowy plik na swojej stronie bez żadnych dodatkowych weryfikacji;
- zbadać, czy odpowiednio zamknąłeś strony, których chcesz uniknąć, i czy te, które mają podlegać indeksacji, są odpowiednio otwarte.
Yandex Webmaster
Zaloguj się na konto z bieżącą stroną potwierdzoną na swojej platformie, przejdź do Narzędzia, a następnie do analizy Robots.txt.
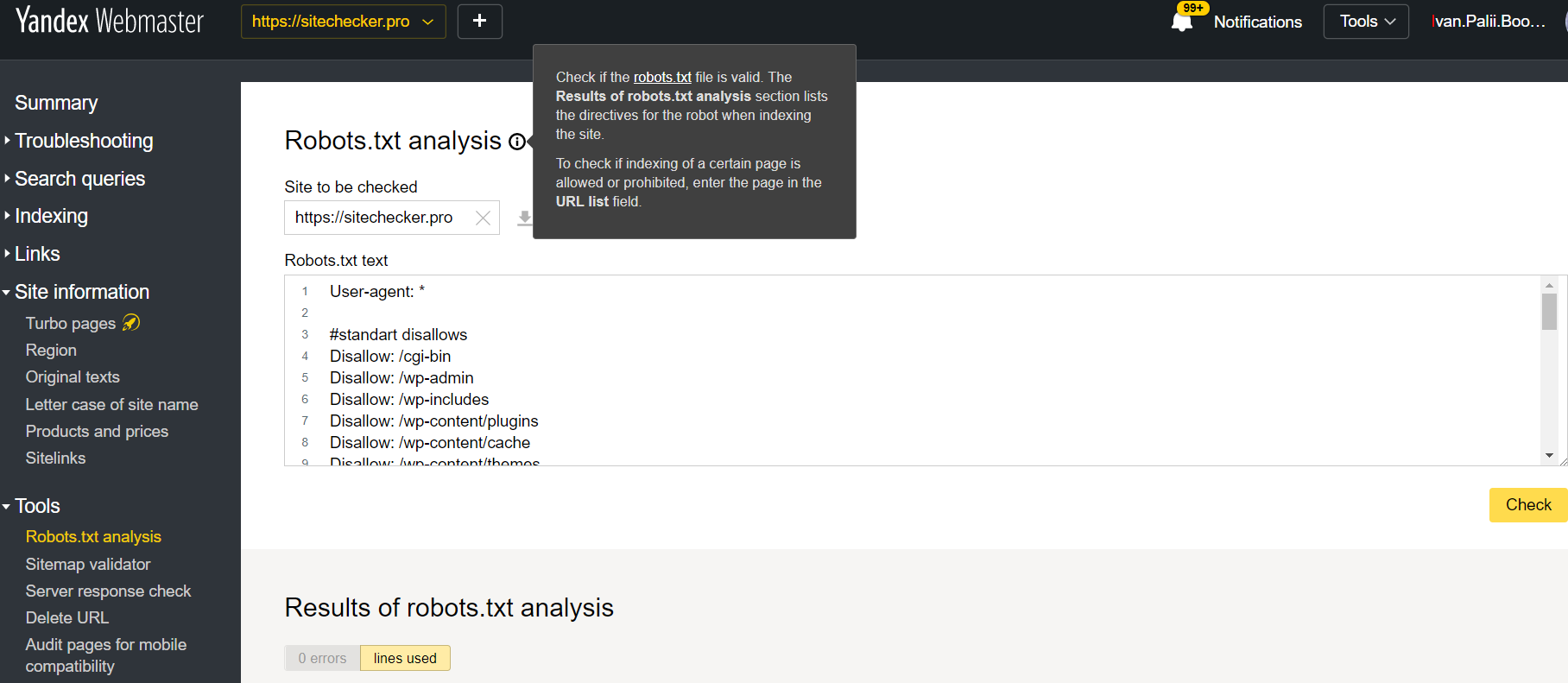
Ten tester oferuje prawie równe możliwości weryfikacji, jak opisano powyżej. Różnica polega na:
- tutaj nie musisz autoryzować i potwierdzać praw do witryny, która oferuje natychmiastową weryfikację pliku robots.txt;
- nie ma potrzeby wstawiania na stronę: cała lista stron może być sprawdzona w ciągu jednej sesji
- możesz upewnić się, że Yandex prawidłowo zidentyfikował twoje instrukcje.
Jak robots.txt może pomóc w strategii SEO?
Przede wszystkim chodzi o indeksowanie budżetu. Każda witryna ma własny budżet indeksowania, który jest szacowany przez wyszukiwarki osobiście. Plik Robots.txt zapobiega przeszukiwaniu witryny przez boty wyszukiwania niepotrzebnych stron, takich jak duplikaty stron, śmieciowe strony, a nie strony wysokiej jakości. Główny problem polega na tym, że indeks wyszukiwarek dostaje coś, czego nie powinno tam być – strony, które nie przynoszą korzyści ludziom i po prostu zaśmiecają wyszukiwanie.
Ale jak może to zaszkodzić SEO? Odpowiedź jest łatwa. Gdy roboty wyszukujące docierają do witryny w celu indeksowania, nie są zaprogramowane do eksplorowania najważniejszych stron. Często skanują całą witrynę ze wszystkimi jej stronami. Dlatego najważniejsze strony nie mogą być po prostu skanowane ze względu na ograniczony budżet indeksowania. Dlatego Google lub jakakolwiek inna wyszukiwarka zaczyna zajmować się Twoją witryną w zakresie otrzymanych informacji. W ten sposób twoja strategia SEO jest zagrożona niepowodzeniem z powodu nieodpowiednich stron.




