

Was ist robots txt? Die Datei robots.txt liefert Suchsystemen die Information, die sie braucht, um verwertbare Suchergebnisse zu liefern. Bevor sie Ihre Site durchsucht, durchleuchten Tobots diese Datei. Diese Prozedur macht das Scannen effizienter. Damit helfen Sie Suchsystemen, sodas die wichtigsten Daten auf Ihrer ersten Seite zuerst indiziert werden, dann der Rest. Aber das ist nur möglich, wenn Sie eine korrekt konfigurierte robots.txt haben.
Ähnlich wie die robots.txt Datei gibt die noindex-Anweisung im Meta Tag Robots nur eine Empfehlung für Robots. Das ist der Grund, warum sie nicht garantieren können, dass diese verschlossenen Seiten nicht indiziert warden und nicht im Index inkludiert sein warden. Garantien in dieser Sache sind ohnehin unangebracht. Wenn Sie eine Seite wirklich von der Indizierung ausschließen wollne, müssen Sie ein Passwort setzen, damit das Verzeichnis geschlossen bleibt. Das robots.txt erstellen ist ein wichtiger Schritt für SEO.
Hauptsyntax
User-Agent: Der Robot wird die folgenden Regeln anwenden (beispielsweise der “Googlebot”)
Disallow: (dt: Verbieten) die Seiten, die Sie vor Zugriff ausschließen wollen (am Beginn jeder neuen Zeile können Sie eine lange Liste von gewünschten Pfaden einschließen)
Jede Gruppe User-Agent / Disallow sollte mit einer Leerzeile abgetrennt werden. Aber nicht-leere Strings dürfen nicht innerhalb einer Gruppe (zwischen User-Agent und dem letzten Disallow-Pfad) aufscheinen.
Hash mark (#) kann verwendet werden, um ggf. Kommentare in der robots.txt innerhalb einer aktuellen Zeile einzupflegen. Alles, was nach dem Hash Mark angeführt wird, wird ignoriert. Wenn Sie mit einem robot txt Dateigenerator arbeiten, ist dieser Kommentar für die ganze Zeile oder auch am Ende davon nach den Pfaden anwendbar.
Kataloge und Dateinamen sind Verzeichnis-sensibel: Das Suchsystem akzeptiert «Catalog», «catalog» und «CATALOG» als unterschiedliche Pfade.
Host: wird für Yandex verwendet, um Mirrorsites hervorzuheben. Das ist der Grund, warum Sie eine 301 Weiterleitung pro Seite einpflegen, um zwei Sites miteinander zusammen zu kleben. Es gibt keinen Grund, diese Prozedur in der robots.txt zu wiederholen (auf der Dupplikatseite). Somit wird Yandex den angegebenen Pfad auf der Seite, die angeheftet wird, finden.
Crawl-delay: (dt: Crawl-Verzögerung) Sie können die Geschwindigkeit Ihrer Seitendurchkreuzung limitieren. Das ist ideal, wenn es zu hoher Aufmerskamkeitsfrequenz auf Ihrer Site kommt. Diese Option ist verfügbar, um die robot.txt Dateigeneratoren von zusätzlichen Problemen mit einer Extraladung Ihres Servers, verursacht durch Suchsysteme, die Informationen auf Ihrer Site suchen, zu bewahren.
Regular phrases: (dt: regelmäßige Ausdrücke) für flexiblere Einstellungen der Pfade können Sie die beiden Symbole unten verwenden:
* (Stern) – kennzeichnet jede Symbolsequenz,
$ (Dollarzeichen) – steht für das Ende der Zeile.
Hauptbeispiele für die Verwendung des robots.txt Generators
Bann der Indizierung auf der kompletten Site
User-agent: *
Disallow: /Diese Anleitung muss verwendet werden, wenn Sie eine neue Site erzeugen und Subdomains verwenden, um Zugriff darauf zu gewähren.
Häufig vergessen Web Entwickler, wenn Sie auf einer neuen Site arbeiten, einige Teile der Site von der Indizierung auszuschließen. Als Ergebnis legen Indiziersysteme eine komplette Kopie davon an. Wenn solche Fehler passiert sind, muss Ihre Masterdomain auf jeder Seite eine 301 Weiterleitung bekommen. Robot.txt Generator kann hier tolle Dienste leisten!
Die folgende Konstruktion VERHINDERT die Indizeirung der kompletten Site:
User-agent: *
Disallow:
Bann der Indizierung von einem bestimmten Verzeichnis
User-agent: Googlebot
Disallow: /no-index/
Bann eines bestimmten Robots beim Besuch einer Seite
User-agent: Googlebot
Disallow: /no-index/this-page.html
Bann der Indizierung einzelner Dateitypen
User-agent: *
Disallow: /*.pdf$
Um einen Besuch einer bestimmten Seite für einen bestimmten Web Robot zu erlauben
User-agent: *
Disallow: /no-bots/block-all-bots-except-rogerbot-page.html
User-agent: Yandex
Allow: /no-bots/block-all-bots-except-Yandex-page.html
Website Link zur Sitemap
User-agent: *
Disallow:
Sitemap: http://www.example.com/none-standard-location/sitemap.xml
Besonderheiten, die berücksichtigt werden sollen, wenn dieser Pfad benutzt wird, wenn Sie die Site mit einzigartigen Inhalten füllen:
- Fügen Sie keinen Link in Ihrer Site Map im Robots Textdatei Generator hinzu;
- Wählen Sie einige nicht standardmäßige Namen für die Site Map von sitemap.xml (beispielsweise my-new-sitemap.xml und dann fügen Sie den Link zum Suchsystem mittels Webmaster);
weil viele unfaire Webmaster zerlegen den Inhalt anderer Sites außer ihre eigenen und verwenden diese für deren eigene Projekte.
Überprüfen Sie auf Ihren Webseiten den Indexierungsstatus Erkennen Sie alle nicht indizierten URLs in und finden Sie heraus, welche Websiteseiten von Suchmaschinen-Bots gecrawlt werden dürfen
Was ist besser – Robots txt Generator oder Noindex?
Wenn Sie wollen, dass manche Seiten von der Indizierung ausgeschlossen werden, ist Noindex im Meta Tag Robots empfehlenswerter. Um dies zu implementieren, müssen Sie den folgenden Meta Tag im Bereich Ihrer Seite einfügen:
<meta name=”robots” content=”noindex, follow”>Wenn Sie diesen Ansatz verwenden, werden Sie:
- die Indizierung bestimmter Seiten während des Besuchs des Web Robots verhindern (Sie müssen dann keine Seiten manuell mittels Webmaster löschen);
- es schaffen, den Link Juice Ihrer Seite zu übertragen.
Robots txt Dateigenerator ist besser, wenn es darum geht, folgende Seiten auszuschließen:
- administrative Seiten Ihrer Site;
- Suchdaten auf der Site;
- Seiten der Registrierung/Authentifizierung/Passwort-Rücksetzung.
Welches Tool verwenden und wie kann es helfen, die robots.txt Datei zu prüfen?
Wenn Sie eine robots.txt generieren, müssen Sie überprüfen, ob diese irgendwelche Fehler enthält. Die robots.txt Überprüfung der Suchsysteme kann Ihnen dabei helfen:
Melden Sie sich mit dem Acocunt der aktuellen Site auf der Plattform an, gehen Sie zu Crawl, dann zu robots.txt Tester.
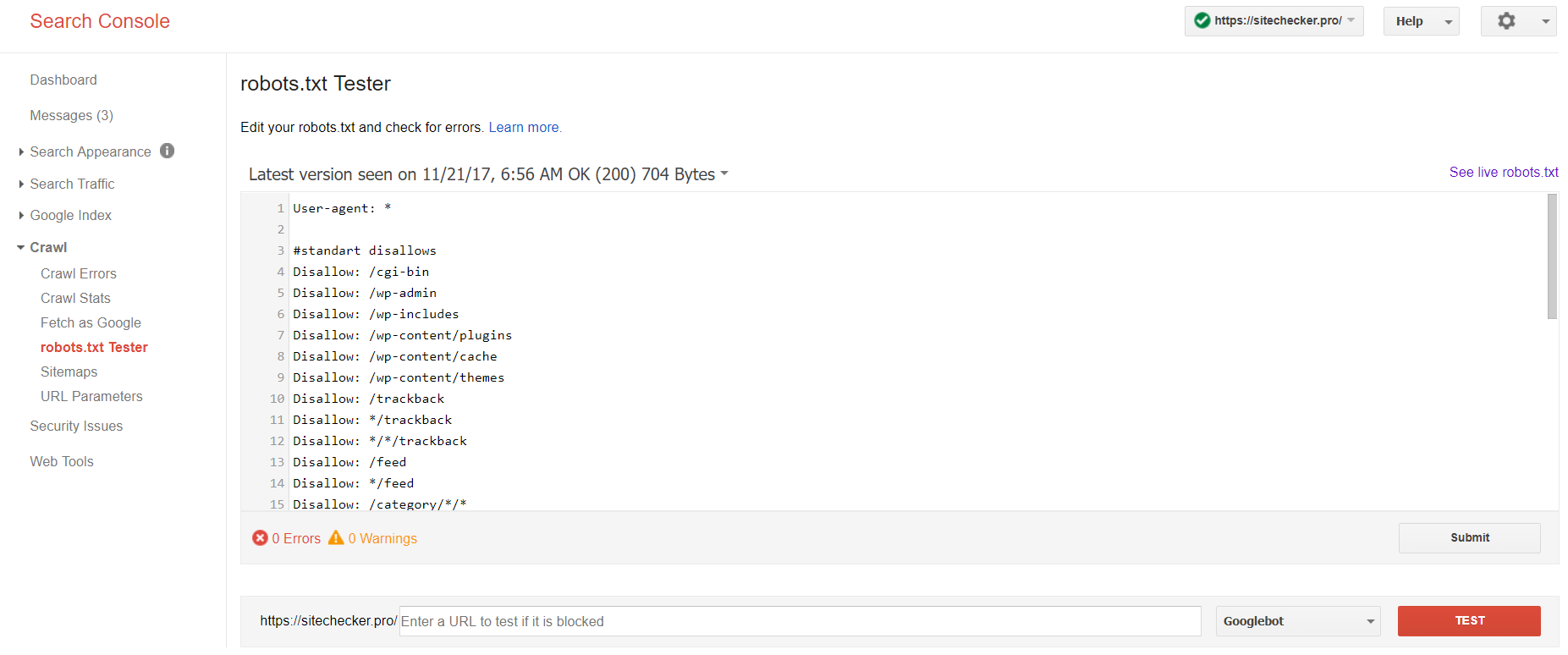
Dieser Robot txt Test erlaubt es:
- alle Fehler und möglichen Probleme auf einmal zu finden;
- Fehler zu suchen und alle benötigten Korrekturen sofort zu tätigen, um die neue Datei auf Ihrer Site ohne zusätzliche Änderungen zu installieren;
- Herauszufinden, ob Sie die Seiten, die Sie von der Indizierung ausgeschlossen haben, passen oder ob die, die indiziert werden sollen, auch offen sind.
Melden Sie sich am Account der aktuellen Site an, gehen Sie zu Tools und dann zu Robots.txt Analysis.
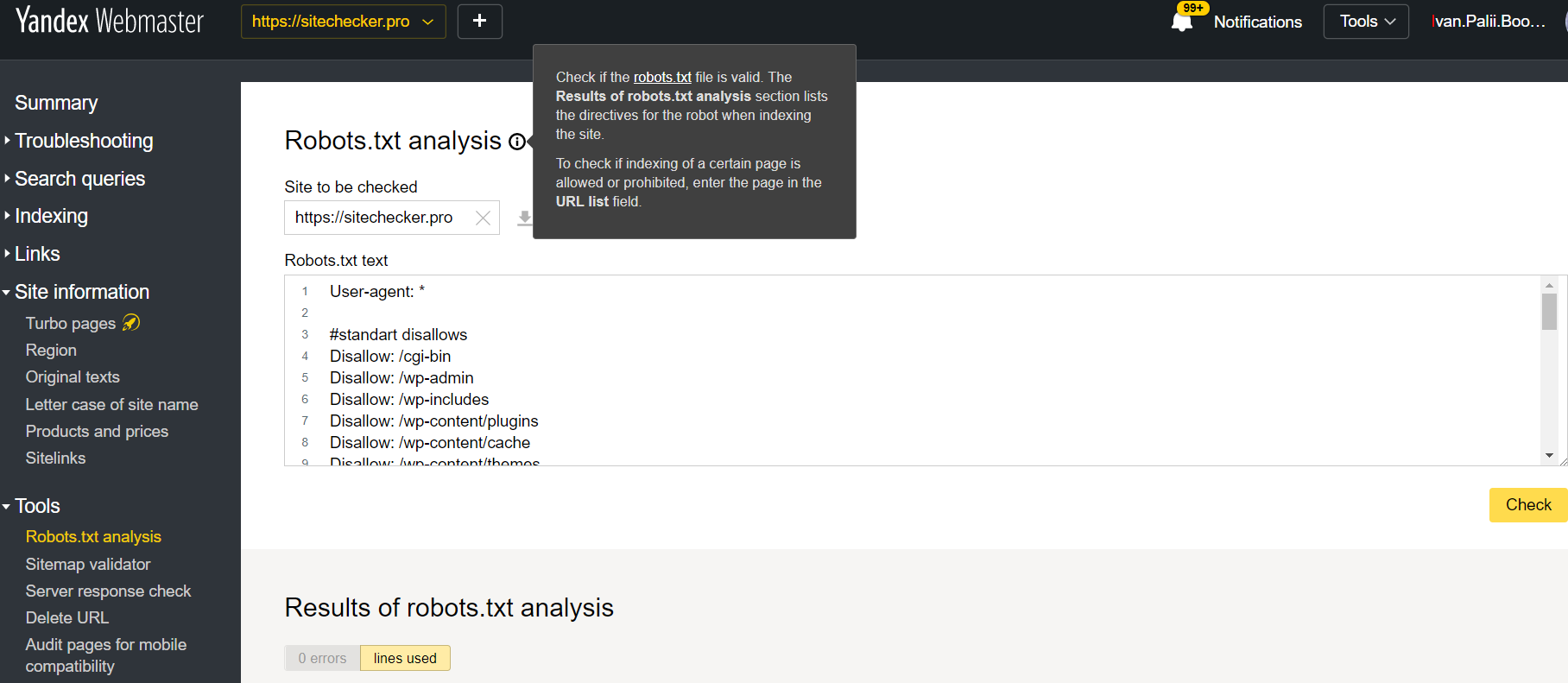
Dieser Tester bietet fast identische Möglichkeiten für die Verifizierung wie die oben beschriebene. Die Unterschiede sind:
- Hier müssen Sie sich nicht authorizieren, um die Rechte für eine Site zu bestätigen, die eine direkte Verifizierung zu Ihrer robots.txt Datei bietet;
- Es gibt keine Notwendigkeit, pro Seite folgendes einzufügen: Die komplette Liste der Seiten kann innerhalb einer Session überprüft werden
- Sie können sicher sein, dass Yandex Ihre Instruktionen passend durchgeführt hat.



