



Что такое robots.txt
Файл robots.txt устанавливает правила сканирования сайта для ботов поисковых систем. Перед тем как осуществить анализ сайта поисковые роботы выполняют проверку этого файла. Благодаря такой процедуре они могут повысить эффективность сканирования и сэкономить свои ресурсы. Но все это возможно, только если вы правильно настроили файл.
Инструкция noindex в мета-теге robots, как и команды файла robots.txt, является не более чем рекомендацией для роботов. Ни тот, ни другой способ не могут гарантировать того, что закрытые страницы не попадут в индекс. Если вам наверняка нужно закрыть для индексации часть вашего сайта лучше использовать пароль для закрытия отдельных папок.
Справка Google Search Console
Основной синтаксис
User-Agent: робот, к которому будут применяться следующие правила (к примеру, «Googlebot»)
Disallow: страницы, к которым вы хотите закрыть доступ (с началом каждой новой строки вы можете включить огромный перечень указаний и инструкций). Каждая группа User-Agent / Disallow должна быть разделена пустой строкой. Но непустые строки не должны встречаться внутри группы (между User-Agent и последним элементом списка Disallow).
Хэш-метка (#) может использоваться, когда необходимо оставить комментарии в файле robots.txt для текущей строки. Все, что упоминается после метки хэша, будет проигнорировано поисковым ботом.
Каталоги и имена файлов чувствительны к регистру: для поисковой системы «Каталог», «каталог» и «КАТАЛОГ» это разные страницы.
Host: используется Яндексом, для указания основного зеркала сайта. Поэтому, если вы выполняете 301 редирект на страницу, чтобы объединить два сайта, нет необходимости повторять процедуру для файла robots.txt (на дублированном сайте). Яндекс определит указанную директиву на сайте, который должен быть склеен.
Crawl-delay: вы можете ограничить скорость сканирования вашего сайта, что очень полезно в случае его высокой посещаемости. Подобные ситуации возникают из-за еще большей нагрузки, которую вызывают боты, обрабатывающие информацию на сайте.
Регулярные выражения: для обеспечения более гибких инструкций вы можете использовать два символа, упомянутых ниже:
* (звезда) – указывает на любую определенную последовательность знаков,
$ (символ доллара) – обозначает конец текущей строки.
Полезные ссылки: Справка Google по созданию robots.txt, полный синтаксис robots.txt
Примеры правил
Запрет на сканирование всего сайта
User-agent: *
Disallow: /Эту инструкцию нужно применять при создании нового сайта или использовании поддоменов для обеспечения доступа к нему. Весьма часто при работе на новом сайте веб-разработчики забывают закрыть часть сайта для индексации, а поэтому поисковые роботы обрабатывают полную его копию. Если вы сделали подобную ошибку, то для вашего основного домена следует сделать 301 редирект на страницу.
Разрешение сканировать весь сайта
User-agent: *
Disallow:Запрет на сканирование конкретной папки
User-agent: Googlebot
Disallow: /no-index/Запрет на сканирование страницы для конкретного бота
User-agent: Googlebot
Disallow: /no-index/this-page.htmlЗапрет на сканирование определенных типов файлов
User-agent: *
Disallow: /*.pdf$Разрешение сканировать страницу для конкретного бота
User-agent: *
Disallow: /no-bots/block-all-bots-except-rogerbot-page.html
User-agent: Yandex
Allow: /no-bots/block-all-bots-except-Yandex-page.htmlСсылка на карту сайта
User-agent: *
Disallow:
Sitemap: http://www.example.com/none-standard-location/sitemap.xml
Если вы постоянно наполняете свой сайт уникальным контентом, то лучше:
- не добавляйте ссылку на свою карту сайта в robots.txt;
- выберите нестандартное имя для карты сайта (например, my-new-sitemap.xml, а затем добавьте эту ссылку в поисковые системы с помощью сервисов Google, Yandex).
Это важно делать, так как множество нечестных веб-мастеров парсят контент с других сайтов и используют его для своих собственных проектов.
Найдите неиндексируемые страницы
Получите список всех неиндексируемых URL сайта и проанализируйте нет ли среди них ценных страниц
Исключение в robots.txt или noindex
Если вы хотите, чтобы некоторые страницы не индексировались, лучшим вариантом будет атрибут noindex в мета-тегах robots. Чтобы реализовать его, вам нужно добавить следующий мета-тег в коде вашей страницы:
<meta name="robots" content="noindex, follow">При использовании этого варианта вы:
- сможете избежать индексации определенной страницы во время следующего посещения веб-робота (вам не нужно будет удалять страницу вручную с помощью сервиса для веб-мастеров);
- сможете управлять передачей ссылочного веса на вашей странице.
В файле robots.txt лучше закрывать такие типы страниц:
- страницы управления вашим сайтом;
- страницы-результаты поиска по сайту;
- страницы регистрации/авторизации/сброса пароля.
Инструменты проверки robots.txt
Когда вы создаете файл robots.txt, часто нужно проверить, содержит ли он какие-либо ошибки. В этой задаче могут помочь такие инструменты.
Google Search Console
Сейчас инструмент тестирования robots.txt есть только в старой версии Google Search Console. Чтобы найти его войдите в аккаунт с подтвержденным сайтом и следуйте этому пути.
Старая версия Google Search Console > Сканирование > Инструмент проверки файла robots.txt
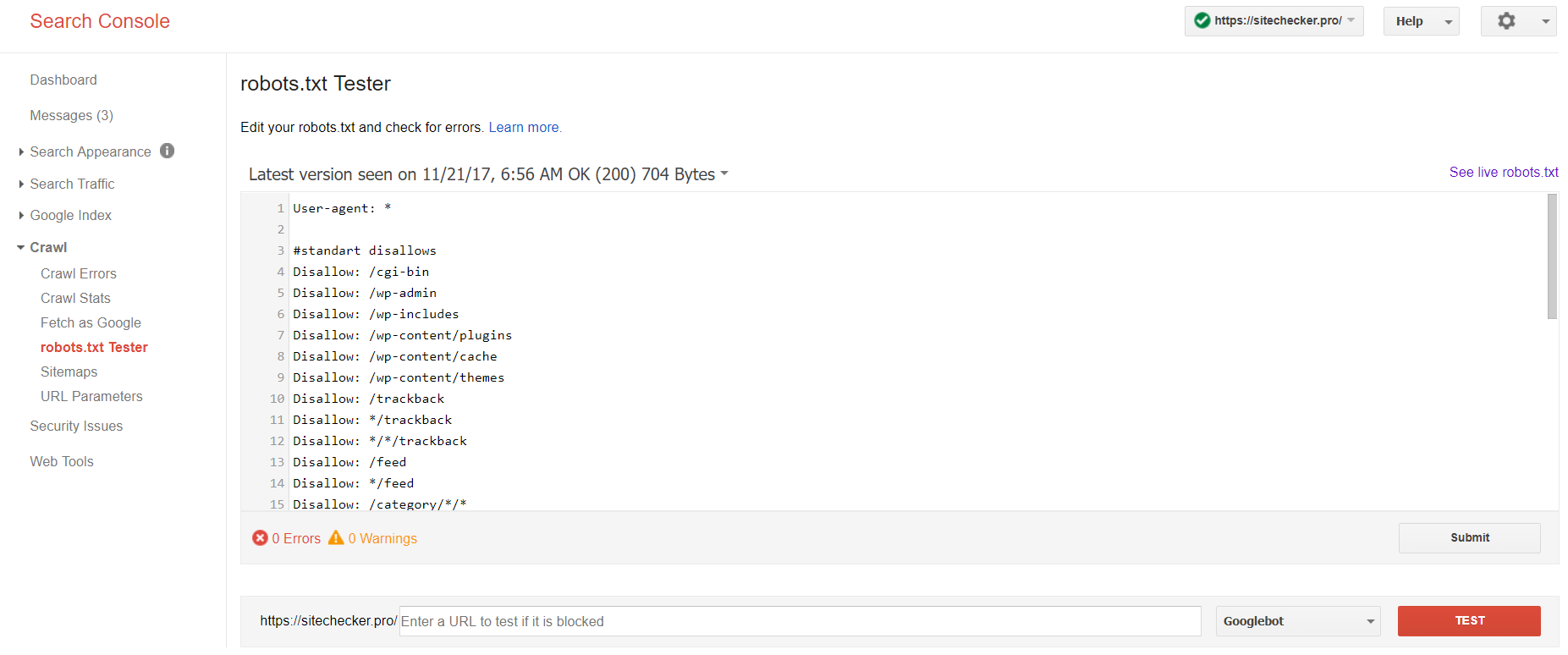
Здесь вы можете:
- сразу обнаружить все свои ошибки и возможные проблемы;
- проверить ошибки, внести необходимые исправления и загрузить новый файл на свой сайт без каких-либо дополнительных проверок;
- проверить корректно ли вы закрыли необходимые страницы от сканирования, и открыли те, которые обязательно должны быть просканированы.
Яндекс.Вебмастер
Чтобы перейти к использованию инструмента войдите в аккаунт Яндекс.Вебмастера и следуйте этому пути.
Яндекс.Вебмастер > Инструменты > Анализ robots.txt
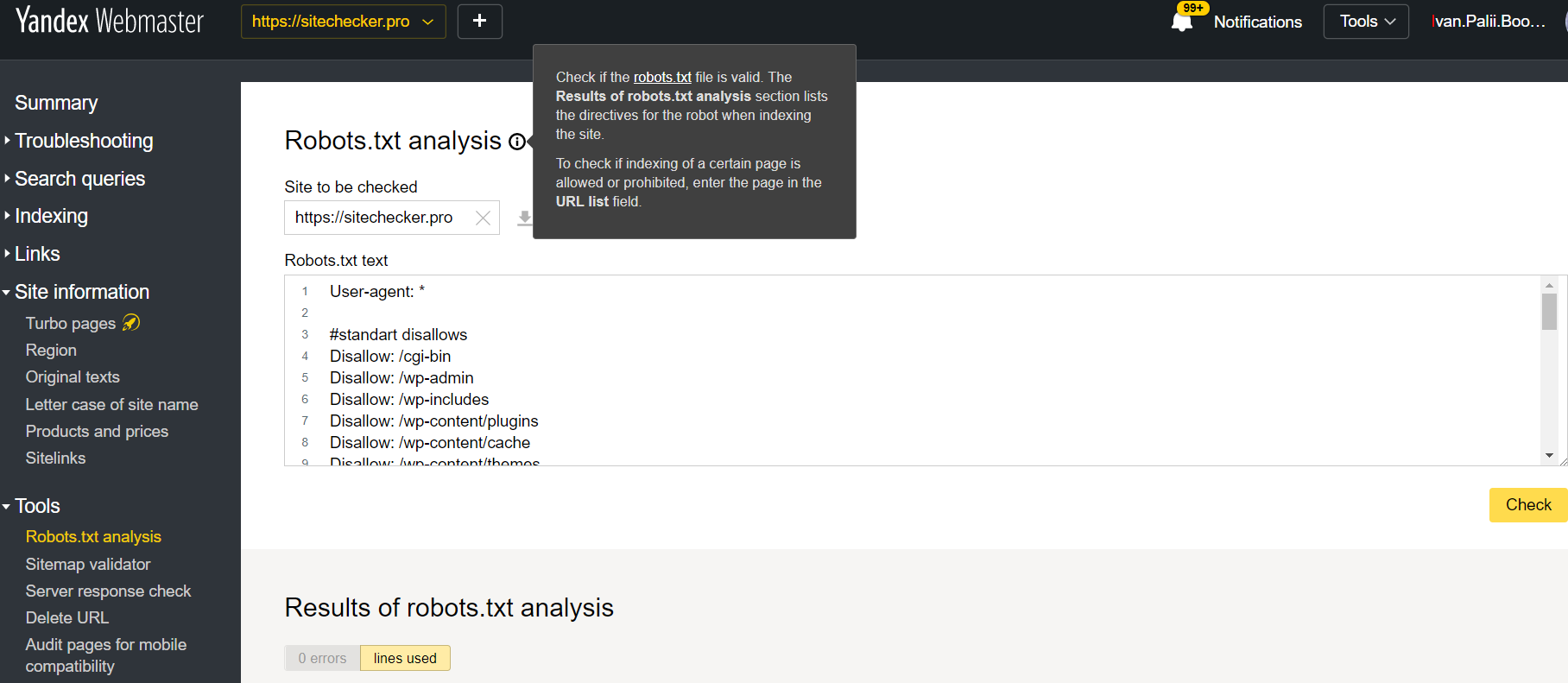
Этот инструмент предлагает почти такие же возможности для проверки, как и Google Search Console. Разница заключается в следующих параметрах:
- здесь не обязательно подтверждать права на сайт;
- нет необходимости вставлять отдельно каждую страницу для проверки, полный перечень веб-страниц можно проверить в одном окне;
- вы можете убедиться, что Яндекс правильно понял ваши инструкции.
Краулер Sitechecker
Это решение для массовой проверки. Наш краулер помогает проанализировать весь сайт и определить какие страницы сайта закрыты от индексирования в robots.txt, а какие через мета тег noindex.
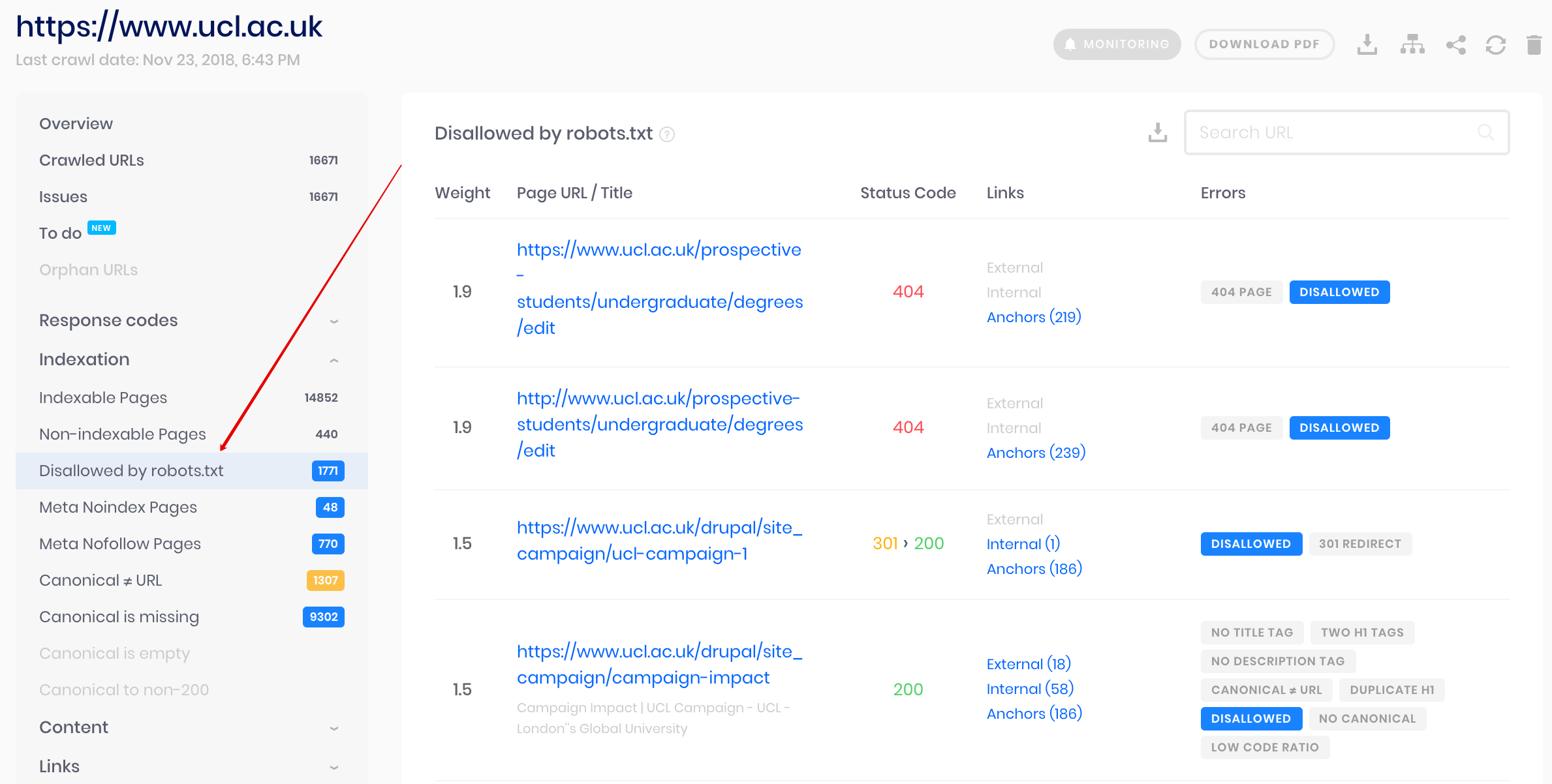
Наш краулер помогает проанализировать весь сайт и определить какие страницы сайта закрыты от индексирования в robots.txt, а какие через мета тег noindex.
Обратите внимание: чтобы найти страницы закрытые для сканирования в robots.txt нужно запускать аудит с настройкой “ignore robots.txt” . Иначе Sitecheckerbot будет следовать инструкциям указанным в роботсе, и сканировать только разрешенные страницы.





